Hey! I'm Deepika 👋
Recent CSE graduate learning AI/ML in public. Currently exploring NLP, sharing my learnings on Hashnode, and building real-world projects.
Let's connect and learn together!
#NLP#MachineLearning
Small win today: understood LangGraph persistence
It’s basically state save + restore
Which explains how chats magically resume
Also did EDA on a dataset…
Every month has all 4 seasons
Real world data = creative writing?
Or is this normal?
LangGraph is making agents feel less like code, more like systems.
Built a small chatbot today
Then went dataset hunting for XGBoost
Funny part?
Finding the right dataset > building the model
Lowkey want a “describe → get datasets” tool
Got a Prompt Engineer interview tomorrow.
Rounds include English test, aptitude, coding, GD…
but nothing that evaluates prompting.
Offer: 3 LPA + 2-year bond.
Still attending though. Interviews are just another dataset for learning.
Today I learned XGBoost.
Gradient Boosting but with:
�� speed
📉 regularization
🧠 smart optimizations
Ran a small regression example. Tomorrow: real dataset.
Starting to understand why everyone in ML interviews keeps asking about this.
Respect to Tianqi Chen
Tried running Aden Hive today.
Mistake #1: didn’t read the docs.
Mistake #2: assumed it would “just work”.
Eventually got it running on bash… but it quietly switched to an Anthropic model instead of the one I configured.
AI agents are autonomous… apparently configs are too.
Learned Gradient Boosting for classification today. Same story as regression… just a different loss function. Also discovered ML involves more formulas than my memory likes.
Took a break and tried some random photography too.
Today I studied the math behind Gradient Boosting.
First 10 minutes: “This is easy.”
Then came additive modeling…
Then gradients…
Now I’m confused but also curious.
I guess solving problems is the only way forward.
How did you guys actually learn this?
Spent today learning Random Forest.
Thought it was a completely different algorithm… turns out it’s just many decision trees trained on random data.
My Sunday ended with a realization (I’m dramatic). How’s yours?
Took an AI hiring challenge.
Job title: AI Engineer
Questions:
• ML
• NLP
• Coding
LLMs, agents, RAG… nowhere to be found.
At this point I’m convinced
AI interviews are just ML interviews in disguise.
For people running AI agencies:
How do you figure out which companies might actually need your solution?
Manual research? Signals you watch? Just experience?
Trying to learn how agencies identify potential clients.
Building in AI feels strange sometimes.
There’s always something new:
new models
new frameworks
new terms
Today I didn’t build anything.
Just thinking, learning, processing.
Tomorrow we build again.
Today: built a LangGraph agent with self-evaluation.
Also today: discovered 5 new LLMs, 3 renamed ones, and 2 “state-of-the-art” replacements.
Building agents is easier than tracking model names.
Worked on parallel workflows in LangGraph + built an IELTS Task 2 evaluator. Still haven’t locked in my March goals.
Moving forward, figuring it out as I go.
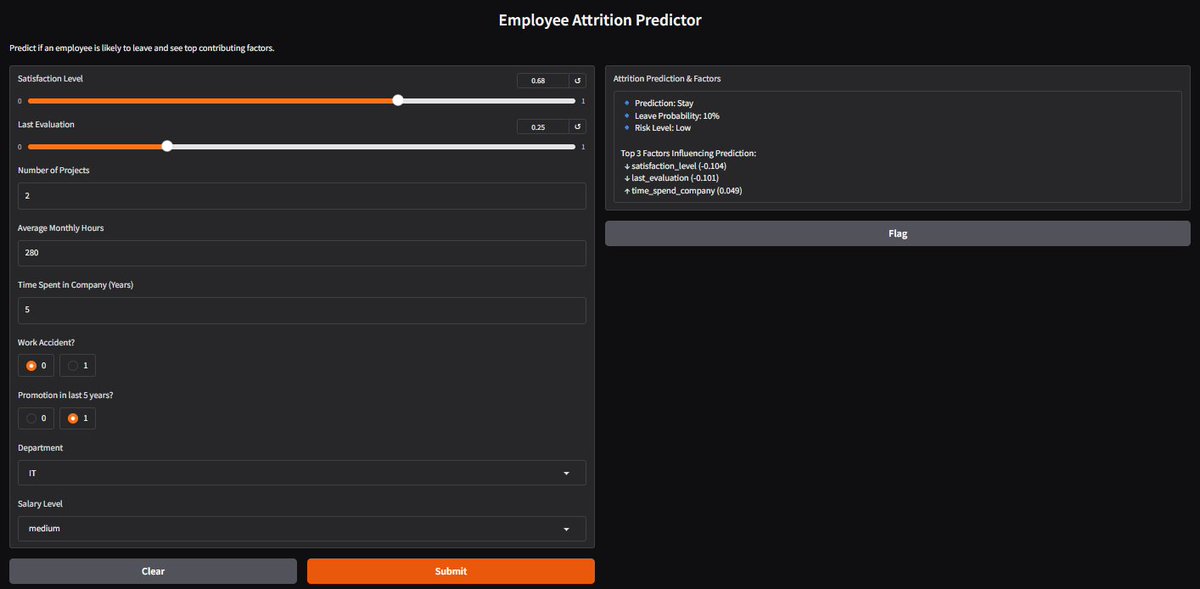
February so far: 2 projects done. Sentiment analysis, and a full employee attrition pipeline(EDA -> Deployment). Learned a lot, had fun, and honestly… it felt more like solving a mystery than coding ML.
Spent the day connecting FastAPI backend to a Gradio frontend for my attrition model.
Prediction + probability + SHAP explanations working end-to-end. Feels good to see it live.
Big realization today:
Sklearn can build the model.
But only you can understand the data.
Spent more time on EDA → got better results.
ML isn’t model-first. It’s data-first.