⏳ Últimos 3 dias para candidaturas ao Deep Learning Sessions Portugal!
Interessado/a em tecnologia e em ajudar a dinamizar uma comunidade?
👉 Não precisas de background técnico.
Candidata-te aqui 👇
https://t.co/7jpR2860J4
🚀 Estamos a recrutar no Deep Learning Sessions Portugal!
Queres ajudar a dinamizar uma comunidade à volta de Deep Learning e tecnologia?
👉 Não precisas de background técnico.
🎯 Estamos abertos a novas ideias de atividades.
👉 Candidata-te aqui:
https://t.co/7jpR285sTw
As Deep Learning Sessions Portugal estão de volta!
Depois de uma pausa, regressamos com novas conversas, convidados inspiradores e temas que exploram o melhor do Deep Learning e da IA em Portugal. 🔗 Fica atento — novidades em breve!
#DeepLearning#InteligenciaArtificial#DLSP
That is exactly what the philosopher Gilbert Simondon addressed in 1958. Culture in general has always been defined as a defense mechanism against technology. Take the English Luddite movement for example. I wrote about it here: https://t.co/qZmBtMBMjH for those interested.
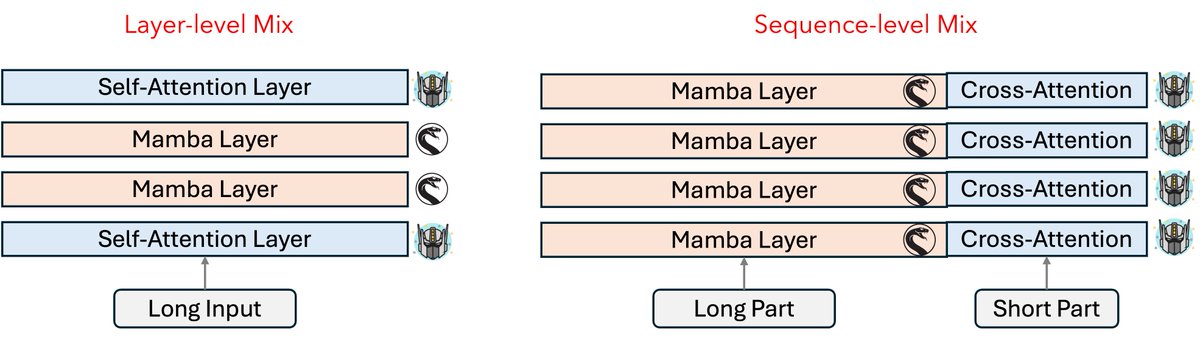
I've seen impressive recent results from hybrid Mamba-Transformer architectures, which show significant progress compared to earlier efforts. These hybrid models excel at handling long-context inputs and enable higher throughput.
Generally, there are two effective approaches to integrating these architectures:
1. Layer-wise Mixing: Alternating Transformer and Mamba layers within the architecture.
2. Sequence-wise Mixing: Using Mamba for encoding long input sequence part and feed the encoded states to cross-attention layers.
Both strategies have demonstrated strong performance and efficiency, particularly in tasks involving extensive context. They basically
It's looking like all the open problems I have thought about in the last 10 years are now solved (or in some cases on the verge of being solved)? Latest case in point this beautiful new paper: https://t.co/52gJmqkOb4 . I'm glad we (humans) got all this results just in time!
The original RL algorithms, inspired by natural learning, were online and incremental—they were streaming in the sense that they learned from each increment of experience as it happened, then discarded it, never to be processed again. The streaming algorithms were simple and elegant, but the first big successes of RL in deep learning were not with streaming algorithms. Instead, methods such as DQN chopped the stream of experience into individual transitions, then stored and sampled them in arbitrary batches. Subsequent work followed, extended, and refined the batch approach into asynchronous and offline RL, while the streaming approach languished, unable to produce good results in popular deep learning domains.
Until now. Now researchers at the University of Alberta have shown that streaming RL algorithms can work just as well as DQN on Atari and Mujoco tasks (https://t.co/S4D6lSvdxz). How did they do it? Mostly just by getting signal normalization and step-size bounding right for the streaming case—otherwise they use standard streaming algorithms like TD(lambda) and Q(lambda). To me it looks like they were simply the first researchers knowledgeable of streaming RL algorithms to seriously address deep RL without being over-influenced by batch-oriented software and batch-oriented supervised-learning ways of thinking.
Few thoughts after having finally written my @iclr_conf rebuttal post endless procrastination:
1. Many reviewers are "LLM-age" reviewers, who probably started research post the dawn of powerful LLMs. Even though your paper is more towards theory or maybe the 1st of its kind proposing/addressing a new problem, they always review the paper with an LLM lens. Prototypical question -- does xyz apply to LLMs? If not REJECT REJECT REJECT!!!!
2. "This doesn't apply to LLMs" has become a lazy way of rejecting papers in adversarial contexts such as paper reviewing. Are we only doing research relevant to LLMs now?
3. Working at the intersection of areas makes the job of convincing reviewers doubly hard. You have minimal control of which kind of reviewer your paper will end up with. With limited page limit you will either fall short even if you try to address different kinds of reviewers or bore at least one kind.
4. Can we as reviewers please leave some room for the possibility that we may have missed something in the paper or might be wrong? It infuriates me to see over-confident extremely stupid reviews. Probably I won't be friends with such people irl.
5. Writing rebuttals has not gotten any less frustrating for me personally.
6. As always, the scores are way harsher than the reviews themselves.
The fact that Machine Learning is now basically an intersection of many fields such as calculus, linear algebra, probability, statistics, etc, makes a fertile ground for notational nightmares with the highest level of symbol overloading you will ever find 😅
here's my proposal: accept 100% of learning theory submissions. this will barely move the overall acceptance rate but raise the quality of the accepted papers immensely