@humzaakhalid Love the diagram and will be taking some of the ideas to integrate into my own setup, but my dude you need to do some proof reading before publishing 😀 unless you used inconsistent spelling on purpose
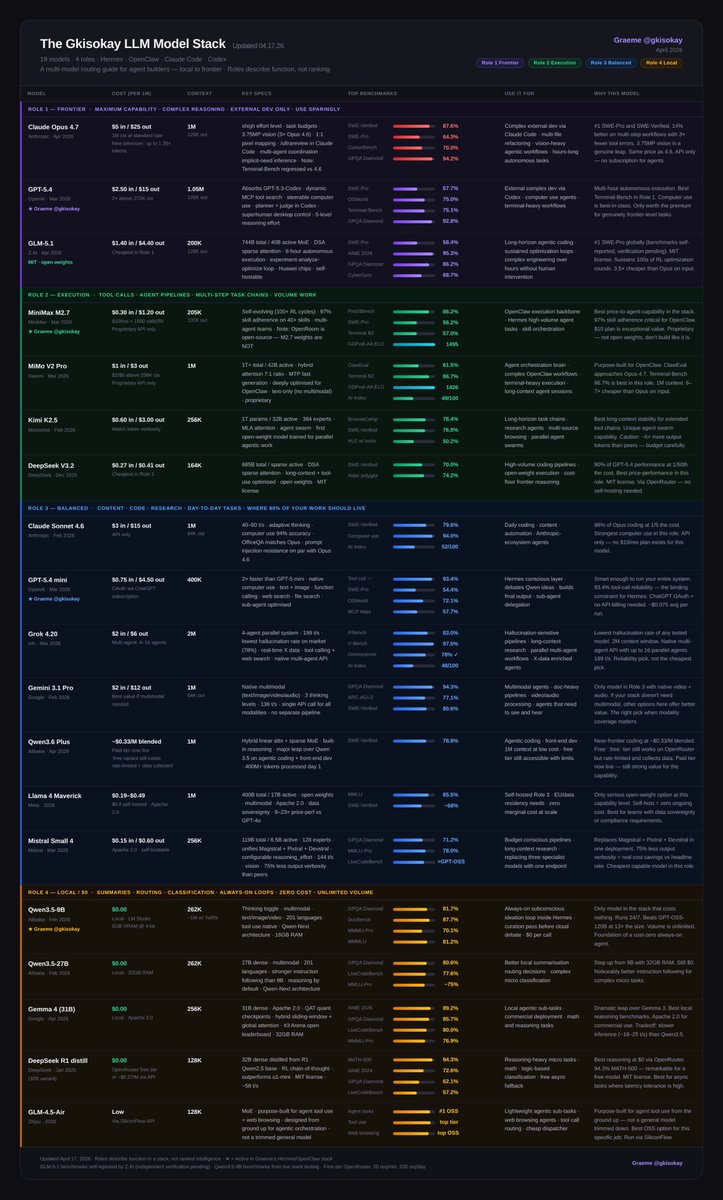
The LLM Cheat-Sheet for OpenClaw + Hermes agents (04.17.26)
Claude Opus 4.7 just dropped and replaces 4.6 at the same $5/$25 pricing.
SWE-Verified jumps to 87.6%, SWE-Pro to 64.3%, task budgets, and xhigh effort for agentic loops.
There's one caveat where the new tokenizer may use up to 35% more tokens per request so its the same price with a higher effective cost. Watch your limits.
MiMo V2 Pro joins Role 2. Xiaomi's agent-native model of 1T+ params, 42B active, 1M context, built specifically for OpenClaw/Hermes workflows.
Here's the full landscape: 19 models, 4 roles, every one earning its place.
Role 1 — Frontier
- Claude Opus 4.7: #1 SWE-Verified and SWE-Pro, 3.75MP vision
- GPT-5.4: best Terminal-Bench in Role 1, super app capabilities announced
- GLM-5.1: #1 SWE-Pro globally, 8-hour autonomous execution, MIT license
Role 2 — Execution
- MiniMax M2.7: 97% skill adherence, built for agents
- MiMo V2 Pro: purpose-built for OpenClaw, ClawEval approaches Opus 4.7, 1M context
- Kimi K2.5: long-horizon stability, agent swarm
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Role 3 — Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability, runs on OAuth
- Grok 4.20: lowest hallucination rate on the market, native multi-agent, 2M context
- Gemini 3.1 Pro: only option with native video + audio. Pick it if your stack needs multimodal
- Qwen3.6 Plus: near-frontier coding and reasoning
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
- Mistral Small 4: one model replacing three — reasoning, vision, and agentic coding, Apache 2.0
Role 4 — Local / $0 for 16GB/32GB (unquantized)
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table ↓
Wait so Mistral has just released one of the best voice AI models... and made it 100% open weights?!
Voxtral TTS has really good capabilities:
→ Only 4B parameters
→ Realistic speech in 9 languages
→ Clone any voice from a few seconds of audio
→ Capture personality, pauses, rhythm, emotions
And it includes cross‑lingual voice adaptation (e.g., French‑accented English).
Already available on HF.
🚨 @Google Research just unveiled TurboQuant, a massive breakthrough in LLM compression and Vector Search.
It solves the Key-Value (KV) cache bottleneck with zero accuracy loss.
Have to wait for Google's implementation. No downloadable PyTorch/CUDA yet on GitHub.
Here is the breakdown: 👇
�� The Problem
High-dimensional vectors use up memory. Traditional compression (quantization) adds "memory overhead" just to store the compression constants, defeating the purpose.
⚡ The Solution (TurboQuant)
It eliminates overhead using two highly theoretical, mathematically proven tricks.
1️⃣ (PolarQuant) Instead of standard X/Y/Z grids, it converts vectors into polar coordinates (radius + angle). This maps data to fixed, predictable circular grids, killing memory overhead.
2️⃣ (QJL) A 1-bit mathematical error-checker (Johnson-Lindenstrauss Transform) that shrinks data to a single sign bit (+1/-1) while perfectly preserving relationships.
📊 The Results are Insane 👀
🗜️ Shrinks KV cache to just 3 bits (Requires ZERO training/fine-tuning)
📉 Reduces KV memory footprint by >6x
🚀 Delivers up to 8x speedup on H100 GPUs (vs 32-bit keys)
🎯 Perfect recall on long-context benchmarks like Needle-in-a-Haystack & LongBench
3-bit efficiency with 32-bit precision. Insane discovery for scaling local LLMs and semantic search.
This could
⚡ Speed up inference up to 8× faster attention on H100 GPUs thanks to reduced memory traffic.
📏 Handle much longer contexts by easily running 4–8× longer sequences (perfect Needle-in-a-Haystack recall at 100k+ tokens) on the same hardware.
💻 Power better local LLMs by running strong long-context models on consumer GPUs, laptops, or edge devices with far less VRAM.
📈 Boost serving efficiency with larger batch sizes, lower cost per token, and reduced power consumption at scale.
🔍 Improve vector search / RAG with near-perfect recall, tiny indexes, and virtually zero preprocessing time.
🚀 Enable practical extreme contexts — Push toward million-token contexts becoming routine without massive hardware.
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
@StefanFSchubert@amitkgupta84 I partially agree with you. After owning an EV for a number of years I can say they use the brakes a lot more than ICE vehicles due to regenerative braking. After 5 years of ownership still same brake pads on my M3 with plenty of life still left in them.
BREAKING NEWS:
This just made me cry.
The SpaceX team just joined the stranded astronauts at the Space Station.
They are all together.
Praise God.
Elon Musk is THE most incredible person on earth… and it isn't even close.
@elonmusk I kind of get it, I know I didn’t want my kids on social media until they were more mature and a bit less naive.
But the govt should not be the ones enforcing this, the responsibility is on the parents to educate and monitor their children.