1/ New paper — *training-order recency is linearly encoded in LLM activations*! We sequentially finetuned a model on 6 datasets w/ disjoint entities. Avg activations of the 6 corresponding test sets line up in exact training order! AND lines for diff training runs are ~parallel!
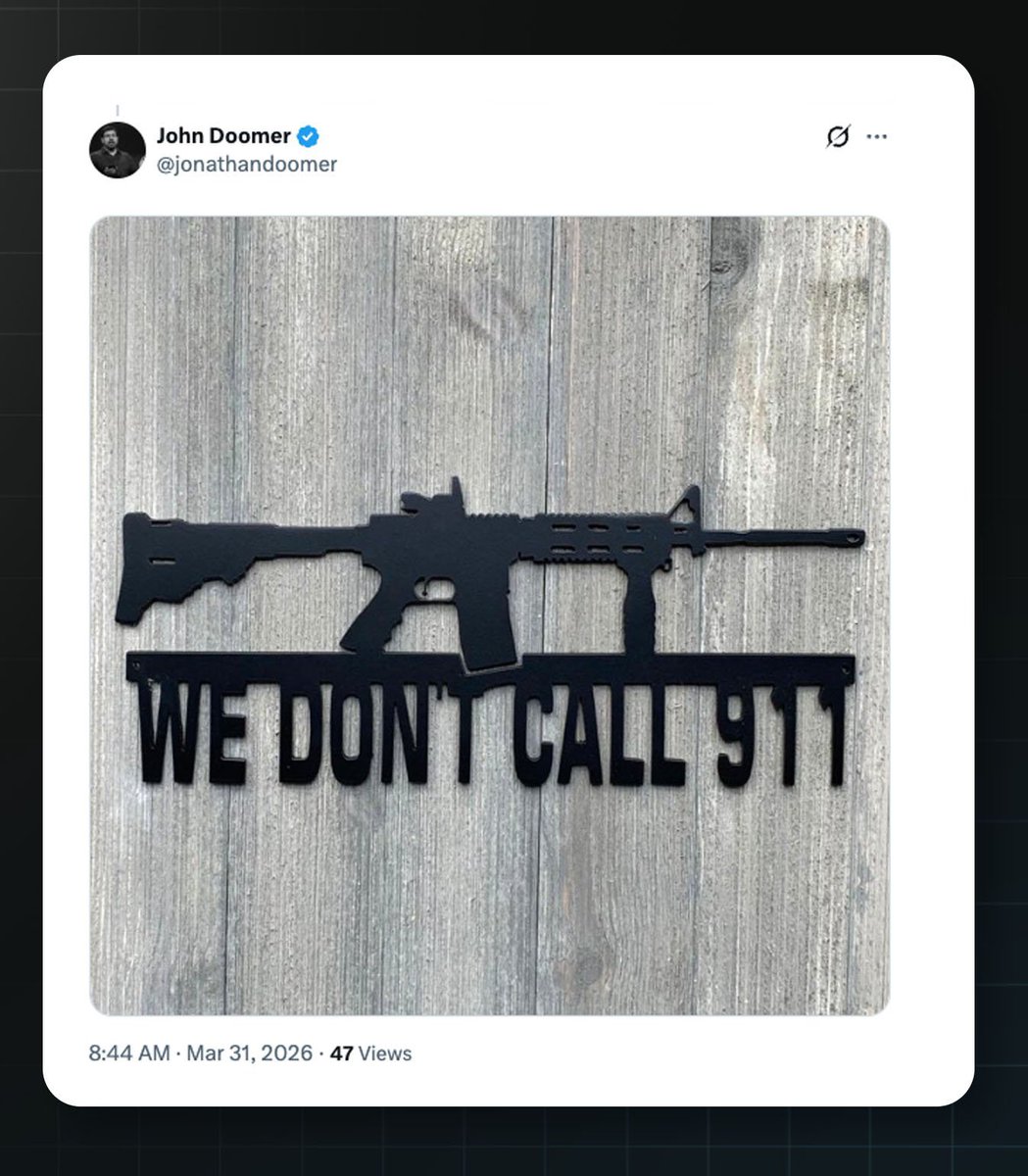
And they admit it (Build American AI is the c4 arm of LTF, the OpenAI-Andreessen super PAC) - they describe it as “parody meme accounts”, but you tell me if an image of an assault rifle on top of “WE DON’T CALL 911”, in response to warnings about AI, is simply a “parody meme”
Very excited to have this paper out! We show by having more parameters, larger models see reduced interference between updates. This allows them to retain memories of rarely observed samples of a task, eventually allowing them to learn even the tail-end of the distribution. (1/3)
Not novel, but a repeated observation on why AI safety research is harder to verify: there’re a dozen or two frontier capability evals at any given point that are (1) good to hill climb, are (2) used and reported across labs (so issues are discovered quickly -> more confidence in the evals) and (3) there is a consensus that they give an imperfect but decent measure of key capabilities.
There isn’t such a generally used hill-climbable suite for safety — even for jailbreak & prompt injection resistance, and especially for misalignment.
So any given safety project often requires not climbing on existing metrics, but first figuring out what is a good metric — and developing good metrics is harder to verify.
Real story:
Judge was about to throw out the case bc Trump controls both parties.
Before it’s dismissed, Trump tells both parties to reach a “settlement.”
Settlement shields Trump from any future audit and creates a secret slush fund that can dole out money to anyone with no transparency.
Mind-boggling corruption.
@SpeakerJohnson - you may not know it, but your job is to conduct oversight of the admin. You can’t run away from this one.
Can we safely automate alignment?
Even if agents are not scheming, they can produce compelling research that survives extensive checks and strongly indicates that a model is safe but is catastrophically wrong.
New paper from UK AISI: https://t.co/MsFTP7R4Mi
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
The people building AI admit they may not be able to control it.
This is not science fiction—this is what experts are telling us.
That’s why I’m bringing together leading AI scientists from the U.S. and China to discuss the risks posed by AI. https://t.co/GLmCJ0cFiQ
Kinda crazy the amount of hate that @OpenAI got for doing the "all lawful use" thing and then @GoogleDeepMind just goes ahead and does it and no one really pays attention
As far as I can tell, the full extent of your support for "strong" regulation to mitigate catastrophic AI risk in this op-ed consists of the two paragraphs in the screenshot below. That is:
* Congress should preempt all existing state regulation on AI risk, including excellent bills such as SB 53 in California or the RAISE Act in New York.
* In exchange for getting rid of all existing and future state regulation on these risks, there should be some kind of federal framework with "serious oversight", so long as industry leaders approve of it.
Does "serious oversight" mean transparency about internal models? Does it mean conducting evaluations for CBRN misuse? Strong guarantees on model weight security? Large investments into interpretability research? Third-party auditing regimes for safety cases? KYC requirements for sufficiently capable models? Strong whistleblower protections? Corporate governance requirements?
LTF doesn't appear to be particularly concerned with figuring out such details so far. I'd be thrilled to see your PAC advocate for strong national regulation, with a detailed plan for the kind of regulatory environment you think would adequately mitigate existential risk from this technology and why, but I'm sure not seeing it yet.
A full-scale US Waymo rollout would cost ~700 full-time jobs in the funeral care industry (by saving around 35 thousand young American lives per year). Will no one think of (some of) the morticians!
Hey! I work at anthropic and helped organize the writing of the mythos preview system card.
I can't speak to the insides of other people's heads, but for what it's worth, it is my very very strong impression that the public announcement was motivated overwhelmingly by a desire to credibly alert the world to the risks posed by such models and a general preference for transparency.
I do expect that having conditioned on wanting to provide such transparency to the public, people did think about how to give that message more reach, but not so far as I know in ways that impaired the accuracy of that message.
In the case of section 7 of the system card, I originally proposed this section, so in that case I am able to just straightforwardly say: I swear by my honor that as best I can recall, the only motivation I had for this section was a sense that it was sad the public would only get to see this model reflected in cyber vulnerability case studies and numbers and graphs, and that it would be fairly cheap for us to provide a bit of the sort of public transparency into gestalt vibes that is ordinarily afforded by people just talking to a model themselves. (And maybe a sense that it would be a little quirky and weird and spark joy for people, but like, in the same way that I feel motivated to help bring quirky joyous things into existence in general, not insofar as that might bolster the valuation of my employer.)
We have a good number of mutual friends who might be able to offer some degree of assurance on my integrity, if you're skeptical of my claims here.
I denounce violent attacks on AI researchers or politicians, such as the recent Molotov cocktail thrown at Sam Altman and the bullets fired into the house a local councilman supporting datacenter development.
Last year, I personally called AI companies to warn their security teams about Sam Kirchner (former leader of Stop AI, who have always had a policy of NONviolence and whose event I spoke at earlier that year) when he disappeared after indicating potential violent intentions against OpenAI.
Besides this one incident, 100% of the calls for violence I have seen have been from CRITICS of AI existential safety, who claim "if you were REALLY worried about AI killing everyone, you'd be taking up arms".
This is not a realistic way to stop AI.
Terrorism against AI supporters would backfire in many ways. It would help critics discredit the movement, be used to justify government crackdowns on dissent, and lead to AI being securitized, making public oversight and international cooperation much harder.
@tmkadamcz and I started working on MirrorCode, a new long-horizon software engineering benchmark, last September. I think it’s the best benchmark for measuring AI’s ability to complete very hard (but precisely specified) software tasks—but it’s likely already saturated.
Mythos also highlights why it’s insane that we’re allowing NVIDIA to sell chips to China.
US labs need all the chips they can get and our compute advantage has been the main thing keeping us in the lead on AI.
Why on earth would we voluntarily hand that over to China?
I wrote up my best guesses for the current state of AI. This is like a scenario forecast, but for the present (which is already uncertain!).
I make guesses about the state of: AI R&D automation and speed up, capabilities, (mis)alignment, cyber, bio, economic effects.
Post: