Scientist - Proteomics Facility. #MassSpec enthusiast, focused on #Proteomics, developing methods for fighting #InfectiousDisease. Opinions tweeted are my own.
Check out our preprint @bioRxiv on bacterial biotyping using LC-MS1 with data analysis of < 2 min using a database of > 12000 @uniprot proteomes #microbiology#proteomics https://t.co/0VAD1yjtSD
Sensitivity for SARS-CoV-2 detection is in the range of LFA rapid tests. The workflow is powered by timsTOF, Evosep and DIA-NN and will enable to identify infected individuals in large sample cohorts in the future. https://t.co/Mv8B46CltC
Proteomics goes viral! We present vPro-MS to identify human-pathogenic viruses in patient samples from diaPASEF/DIA data. We developed a peptide library covering the human virome from 20,000 genomes, which enables highly specific detection (>99,9%) using vProID scoring.
@slavov_n Partly marketing,we talk a lot about technical problems and statistics compared to NGS. So customers trust RNAseq more. Isn't it wild to measure RNA and treat it like proteins when analyzing the data (GO)? Shows that even RNAseq considers transcripts less important than proteins.
@mjmaccoss @UCDProteomics That's a good point. What standard could be used to analyse this? Best I can think of is a dilution series of the UPS1 (SigmaAldrich) in a yeast matrix? But this doesn't account for the proteoform situation in real samples.
@byu_sam It depends on the software, LCMS setup and type of experiment. But for protein quantification using DIA data points per peak can be very low, see https://t.co/1broLYggH7 and https://t.co/6A2O5OeynT
Can DIA take over #proteomics? Recent developments allow deep (> 8000 proteins) and accurate proteome profiling even at 1.5 data points per peak (FWHM) #DIANN#Prosit#µPAC#SPEED https://t.co/vy3KbkCKxK
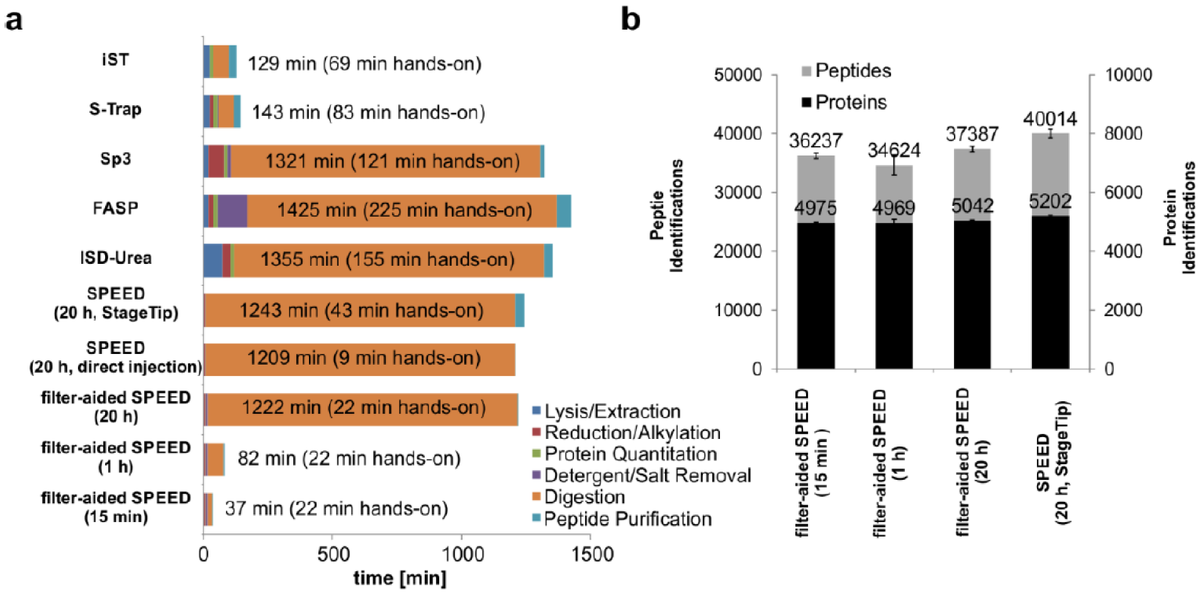
Paper In Press: Sample Preparation by Easy Extraction and Digestion (SPEED) - A Universal, Rapid, and Detergent-free Protocol for Proteomics based on Acid Extraction @rki_de
https://t.co/FUYl9GmoI9