🔥nvMolKit landed today🔥
Morgan Fingerprinting, Tanimoto/Cosine similarity and MMFF geometry optimization and conformer generation on GPU, 10-3000x faster. Screen millions of SMILES before coffee & upsize your QSAR pipelines.
🚀 Which dataset operation will you accelerate first?
#GPU #cheminformatics #drugdiscovery
Unitree Strikes Double Gold on Day One🥇🥇🏃
The First World Humanoid Robot Games
Unitree takes first place in all Day-One races
1500m track race — 6:34.40 (Unweighted)
(Unitree H1 humanoid robot — the same model featured in the Spring Festival Gala)
400m track race — 1:28.03 (Unweighted real stopwatch time 1:23.03)
Let’s set a new running speed record for humanoid robots together!
🚀 GenMol is now open‑sourced: you can now train and finetune on your data!
It uses masked diffusion + a fragment library to craft valid SAFE molecules, from de novo design to lead optimization.
#GenMol#DrugDiscovery#Biopharma
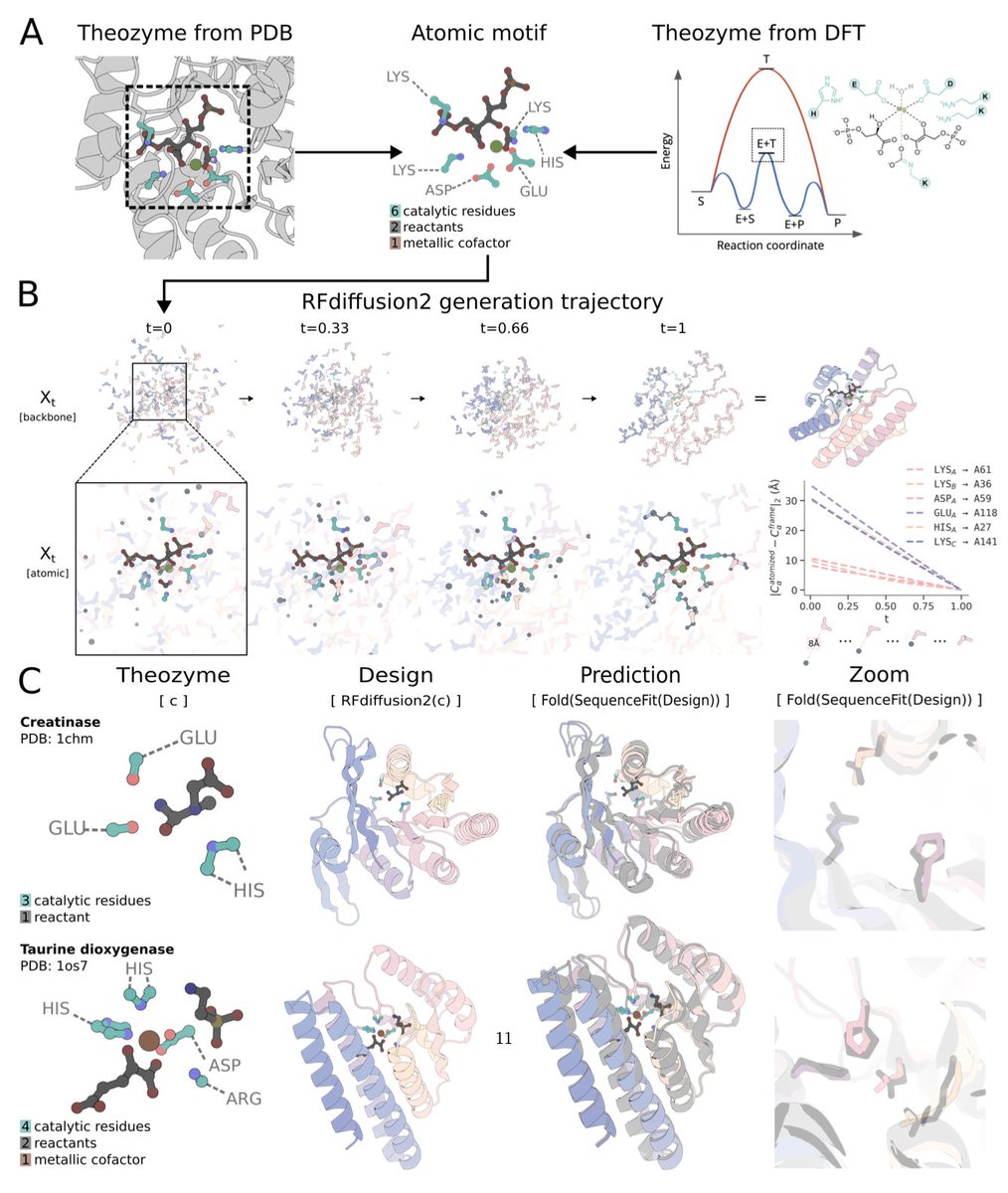
Atom level enzyme active site scaffolding using RFdiffusion2
🚀 New preprint from David Baker!🚀
1. RFdiffusion2 introduces a generative model that designs functional enzymes directly from atomic-level active site descriptions—without needing predefined sequence indices or inverse rotamer sampling, solving a major bottleneck in de novo enzyme design.
2. Unlike previous methods that required residue-level backbone motifs, RFdiffusion2 scaffolds proteins using side chain functional groups alone, inferring both rotamer conformations and residue placement during generation via flow matching diffusion.
3. On the newly curated Atomic Motif Enzyme (AME) benchmark, RFdiffusion2 scaffolds 41/41 diverse enzyme active sites successfully—compared to only 16/41 with the previous state-of-the-art RFdiffusion—demonstrating robust generalization and scalability.
4. RFdiffusion2 leverages “unindexed atomic motifs” to eliminate the need for explicitly specifying sequence positions of catalytic residues, enabling broader solution space exploration and greater structural diversity.
5. The model supports conditioning on atomic motifs, ligand conformations, residue burial (via RASA), and scaffold positioning (via ORI tokens), offering fine-grained control over catalytic geometry and pocket design.
6. In four experimental case studies, including retro-aldolases and zinc-based hydrolases, RFdiffusion2 generated enzymes that displayed catalytic activity with fewer than 96 screened designs, including one variant with a kcat/KM of 53,000 M⁻¹s⁻¹—surpassing prior de novo designs.
7. For reactions without known native theozymes, DFT-optimized transition states were used as inputs, showing that RFdiffusion2 can scaffold new catalysts directly from quantum chemistry, bypassing the need for existing crystal structures.
8. RFdiffusion2-trained models used RosettaFold All-Atom architecture and were trained with flow matching, avoiding auxiliary losses or self-conditioning and enabling stable convergence on diverse geometric motifs.
9. Successful scaffolds were highly novel, with low TM-scores to any PDB structure, indicating that RFdiffusion2 discovers structurally unique solutions—not simply reusing known folds.
10. The open-source AME benchmark, which reflects real-world catalytic diversity, is introduced alongside RFdiffusion2 to foster further research into high-resolution, functional protein design.
11. This work demonstrates that combining atomic-level conditioning, flow-based generative modeling, and structural inference can unlock previously intractable problems in enzyme design—paving the way for programmable, mechanism-guided biocatalysis.
📜Paper: https://t.co/EpQwZeEVAL
#EnzymeDesign #ProteinDesign #GenerativeModels #DiffusionModels #RFdiffusion2 #Bioinformatics #Catalysis #Theozymes #FlowMatching #SyntheticBiology #StructuralBiology #ComputationalBiochemistry
Identifying 14-3-3 interactome binding sites with deep learning
1. The study introduces a deep learning framework designed to predict protein binding sites to the 14-3-3 family, central hub proteins involved in various cellular signaling processes.
2. The researchers created an ensemble model combining multiple deep learning architectures, achieving 75% balanced accuracy in predicting 14-3-3 binding sites, even for challenging intrinsically disordered proteins.
3. This model was applied to 300 sequences of medically relevant proteins, including those linked to diseases like Alzheimer’s (Tau) and cancer (Myc, p53), identifying promising binding sites for further validation.
4. Experimental validation confirmed the model's predictive power, with five out of eight top predictions showing significant binding to 14-3-3 proteins, demonstrating the model's real-world applicability.
5. The study further supports the integration of deep learning with experimental methods such as X-ray crystallography and molecular dynamics to gain insights into protein-protein interactions and their structural dynamics.
6. The model was tested on various 14-3-3 client proteins like FOXO3, BAD, and Tau, with the top predictions providing new avenues for drug design targeting these key interaction sites.
7. By making the model accessible online (https://t.co/8AQrEt13Wg), the authors offer a tool for researchers to explore 14-3-3 interactions in their own studies, advancing our understanding of cellular signaling mechanisms.
💻Code: https://t.co/8AQrEt13Wg
📜Paper: https://t.co/IDk6p2nwUP
#DeepLearning #Proteomics #Bioinformatics #ProteinInteractions #Phosphorylation #Alzheimers #Cancer
Bonne lecture. via @franceinfo : Condamnation de Marine Le Pen : comment le tribunal correctionnel de Paris a-t-il justifié son jugement ? https://t.co/68qSlqxiYH
The new draft deal, one senior official said, looks like “Ukraine was in the war with U.S., lost, [was] captured and now has to pay lifetime reparations.” https://t.co/tPczGZSXpe
Truly remarkable with Vice President JD Vance 🇺🇸 saying that 🇩🇰 “is not a good ally” and indicates 🇺🇸 will do whatever with 🇬🇱 in spite of “the screaming of the Europeans”.
Our MIT class “6.S184: Introduction to Flow Matching and Diffusion Models” is now available on YouTube!
We teach state-of-the-art generative AI algorithms for images, videos, proteins, etc. together with the mathematical tools to understand them.
https://t.co/wDJcM1YTxJ
(1/4)
Cocorico : la France est à la première place européenne pour son écosystème de start-up !
C’est de l’emploi, de la croissance et de l’innovation partout en France. Fierté.
Nous continuerons de soutenir celles et ceux qui innovent et investissent dans notre pays et ses talents.
BREAKING:
The Ukrainian Parliament passes a resolution affirming Zelensky's legitimacy & the constitutionally mandated requirement that keeps him in power throughout the duration of the war due to martial law
268 MPs supported the resolution
225 votes are needed for a majority
One-step Diffusion Models with f -Divergence Distribution Matching
New work by NVIDIA; Generalize variational score distillation to the family of f-divergences to learn a single-step student generator model. When using Jensen-Shannon divergence, f -distill achieves current state-of-the-art one-step generation performance on ImageNet64 and zero-shot text-to-image generation on MS-COCO.
Today in @Nature we present MatterGen, which generates novel materials given prompts of desired chemical, mechanical, electronic, or magnetic properties. @MSFTResearch we see that genAI can learn the languages of nature, not just of humans.
A generative model for stable inorganic materials
The design of inorganic materials underpins progress in areas such as catalysis, energy storage, and carbon capture. However, exhaustive screening methods are often impractical because the search space of possible crystal structures is vast, and existing techniques can fail to propose truly novel candidates.
Claudio Zeni et al. introduce MatterGen, a diffusion-based generative model that refines random atomic placements into stable crystals by addressing atom types, fractional coordinates, and the lattice. The process begins by treating fractional coordinates on a wrapped normal distribution, ensuring a proper periodic boundary. Alongside it, the model diffuses atom types using a discrete denoising approach and handles the lattice via a variance-preserving update that converges toward physically meaningful cells. A neural network with symmetry-aware message passing then simultaneously predicts scores for coordinates, lattice, and categorical elements. After training on a large dataset of stable structures, the researchers fine-tune the base model on labeled property data—like magnetism or band gap—through adapter modules, which steer the diffusion toward a desired property without losing the benefits of large-scale pretraining.
The authors demonstrate that MatterGen substantially increases success rates in generating stable and unique crystals, more closely matching DFT-relaxed local minima than previous methods. They also show how property-guided sampling can propose novel materials with desired compositions, crystal symmetries, or targeted mechanical, electronic, and magnetic characteristics. By combining large-scale training with an adaptable conditional scheme, MatterGen offers a versatile route to speed up the discovery of promising inorganic solids.
Paper: https://t.co/9wEtZtmPAL
Preprint: https://t.co/YoKYQyRvd8
Last week we launched the UK Biobank Pharma Proteomics Project, an unparalleled new study of the proteins circulating in our blood.
✅ Learn more about why it matters and the possible impacts here: https://t.co/vtp4S6CDsJ