Today we're releasing Mellum2: our first "serious" LLM.
This is a 12B A2.5B MoE LLM pre-trained on ~11T tokens and post-trained with RLVR.
I'm proud to be leading the team that was working on it for the last 6 months.
We release base/SFT/RL checkpoints along with a tech report
A pleasure to see our work posted by AK 😊
📉Issue: GRPO hurts generation diversity and pass@k/max@k do not grow as well as pass@1
📈Solution: we estimate gradients for both on- and off-policy cases to optimize max@k directly, and it shows better yields in code generation tasks (measured as the ratio of passed tests)
The 3rd IDE Workshop @ICSEconf 2026 is scheduled for Saturday, April 18th!
Please submit your short papers and extended abstracts on anything IDE-related: plugins, studies, refactorings, environments, AI in IDE, etc.!
All information here: https://t.co/PNeeFLI8Sz
🏝️🏝️🏝️
@InceptionAILabs Is there an API to access the model? I would be happy to run it on some coding benchmarks, but I have not find any points to the API yet.
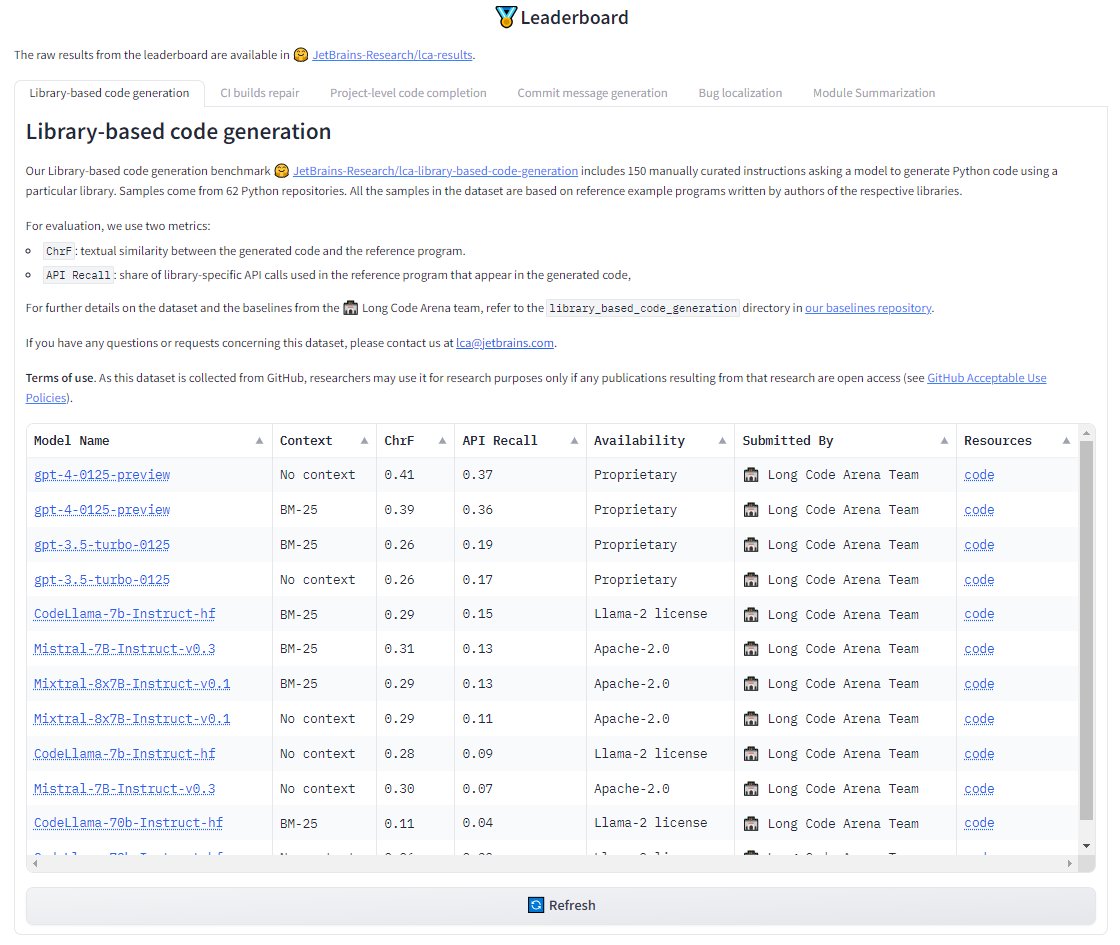
@john_lam@headinthebox Hi, author here. For code generation task we give model an instruction in natural language and access to the library. The reference code is only used for evaluation to compute metrics
Models' contexts are getting so big that they can (and often should!) include an entire repository, while we are still evaluating them on methods and files. That's why we created Long Code Arena.
Pre-print: https://t.co/q1HTcvnjwe
Datasets: https://t.co/UszSNix6J1
Details in🧵!
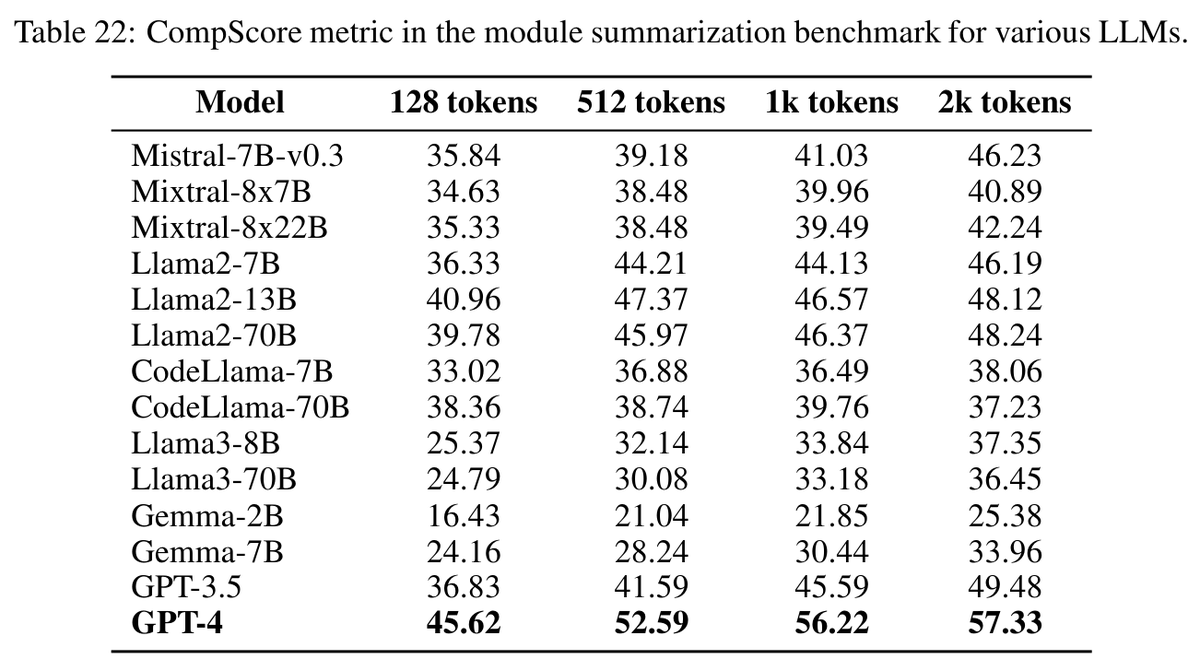
🗂️ Module summarization — based on the module’s or project’s source code and a short description of the desired documentation, the model should generate it, testing its abilities in large comprehensive natural language texts. This benchmark includes custom LLM-based evaluation.