Over the past few years, I’ve actively built my presence in the Web3 ecosystem through research, community engagement, and content creation.
My journey started with contributing educational content and participating in ecosystem discussions, where I’ve had the opportunity to win multiple thread contests across different projects by simplifying complex blockchain concepts and helping communities understand emerging technologies.
Beyond content, I’ve also made it a priority to stay close to builders. I’ve attended Web3 events and community meetups, engaged with teams directly, and contributed to project growth through discussions, feedback, and ecosystem participation.
I’m also an active testnet participant, helping early-stage projects validate products before launch. This hands-on involvement has allowed me to identify promising ecosystems early. For example, participated in testnets like @PlumeNetwork and @OneAnalog and many more which resulted in meaningful gains while reinforcing the importance of early community engagement.
Currently, I’m running multiple testnets across several upcoming projects, contributing feedback, exploring protocol mechanics, and supporting ecosystems that are building the next generation of Web3 infrastructure.
Over time, my interests naturally evolved toward one of the most important conversations in crypto today: privacy.
As blockchain adoption grows, protecting sensitive data becomes critical. This is why I actively advocate for privacy-preserving technologies, particularly within ecosystems like Secret Network, where confidential computing enables secure AI, DeFi, and on-chain applications without exposing user data.
In addition to my Web3 work, I bring strong data analysis skills, allowing me to interpret trends, evaluate ecosystems, and communicate insights clearly to communities and stakeholders.
I’ve also worked as a community moderator, supporting engagement and managing discussions across several meme and community-driven projects, including ‘ItsSolfine’ and others. These roles helped me develop strong experience in community management, moderation, and ecosystem growth.
At this stage, I’m looking to contribute more deeply within the Web3 industry.
Whether it’s content creation, research, ecosystem growth, community moderation, testnet participation, or data-driven insights, I’m ready to put my skills to work and help projects grow.
If you’re building in Web3 and looking for someone who understands community, research, privacy advocacy, and ecosystem participation, I’m open to opportunities and collaborations.
Let’s build.
That framing captures a core property of modern data systems: persistence of collection decoupled from immediate use.
The strongest privacy architectures reduce that long-tail risk by limiting what is ever emitted in the first place, so there’s no latent dataset that can be reinterpreted or weaponized later.
The core issue is inference, not just disclosure. Once personal data is persistently visible or collectible, it can be recombined into narratives that the subject never authored.
Privacy-preserving design helps constrain that by minimizing unnecessary data exposure and limiting the ability to repurpose benign actions into punitive interpretations.
Usability wins when complexity is absorbed by infrastructure.
Privacy shouldn’t introduce extra steps, mental overhead, or degraded experience, it should be the baseline behavior of the system.
Architectures that embed confidentiality directly into computation and application logic are better positioned for adoption precisely because they remove that friction entirely.
Privacy has already moved past the debate stage; the constraint now is execution.
Systems must reconcile three things at once: strong cryptographic guarantees, low-friction user experience, and throughput that matches mainstream demand.
Most designs fail not on principle, but on one of those implementation bottlenecks.
True privacy is preventive, not defensive. Once data is observed, it can be modeled, predicted, and used to steer outcomes in ways users never explicitly agreed to.
The stronger approach is reducing what is observable at the protocol level, ensuring control exists at the point of data creation, not after it has already entered circulation.
AI systems will increasingly sit at the center of sensitive decision-making, which makes trust-based architectures a bottleneck.
Confidential compute shifts that dependency by allowing processing on encrypted data, reducing the need to expose raw inputs while still producing verifiable outputs.
That’s a necessary step if AI is going to operate in regulated or high-stakes environments.
@Shamex_Ent Transparency was useful for bootstrapping trust in early Web3, but it also externalized risk onto users in ways that don’t scale for mass adoption.
When every transaction, balance, and interaction is permanently visible, users are forced to become their own security analysts.
That trade-off is largely a legacy assumption. Modern cryptographic design increasingly separates verifiability from exposure, allowing systems to prove correctness without revealing underlying data.
Approaches like confidential computation and encrypted state execution demonstrate that user protection and auditability can coexist without forcing users into a binary choice.
@web3privacy These two concepts solve different failure modes of digital systems.
Decentralization addresses control and censorship resistance, while privacy addresses visibility and data leakage.
When either is missing, the system remains structurally incomplete.
Privacy is less about secrecy and more about control over data, identity, and exposure. In digital systems, whoever controls visibility often controls leverage.
That’s why privacy-preserving infrastructure matters: it restores agency to users and builders by limiting unnecessary disclosure while still enabling verification where needed.
The underrated part of privacy infrastructure is demand elasticity.
Once builders can compute over encrypted state, they stop avoiding certain product categories entirely.
SecretVM and SecretAI are positioned around that constraint removal, private computation at execution and inference layers.
@mailspec A privacy policy is only as strong as the data inventory behind it.
If collection, storage, retention, and third-party flows aren’t explicitly mapped first, the document becomes ornamental rather than operational.
That’s the real shift, systems that don’t just respond, but execute within predefined constraints while you’re offline.
The interesting part isn’t autonomy alone, it’s auditability: being able to verify every action an agent took, why it took it, and what risk bounds were respected.
Different privacy models solve different problems, one focuses on scalable programmable privacy within smart contract ecosystems, the other prioritizes strong transactional confidentiality at the base layer.
Both approaches expand what users can safely do on-chain, just in different directions of the design space.
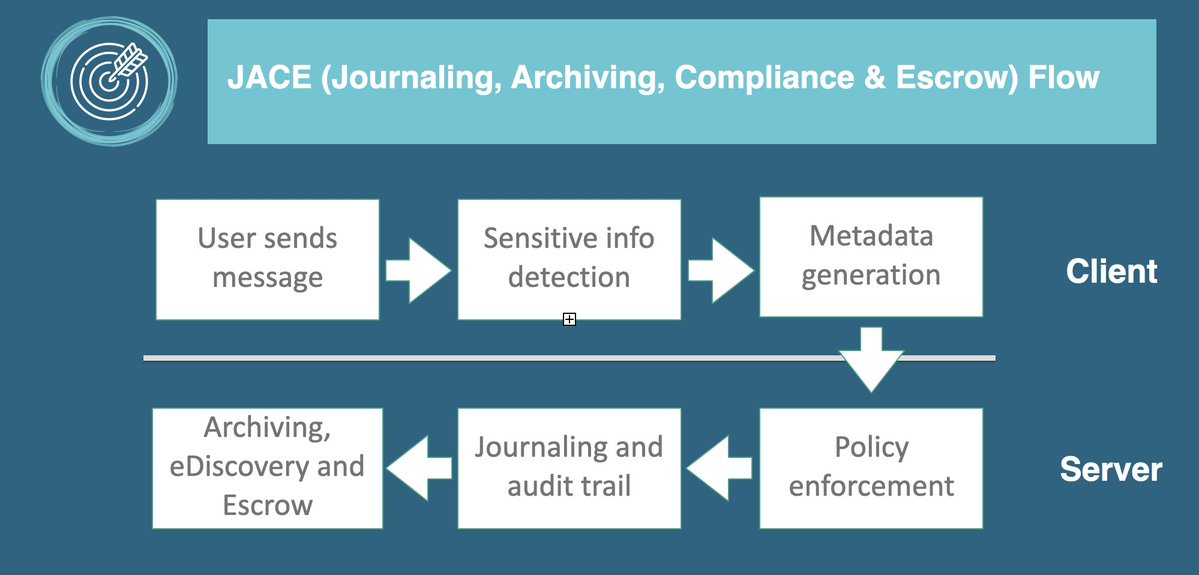
Data classification is foundational for any serious business intelligence system in communications.
Without structured labeling of sensitivity, context, and purpose, analytics pipelines become noisy, risky, and often non-compliant.
Proper classification enables controlled access, accurate segmentation, and more reliable decision-making across distributed communication channels.
That’s the key constraint people miss: intelligence without confidentiality just scales exposure.
If AI is used for auditing, monitoring, and verification, but the underlying data and state are fully visible, you end up hardening systems while simultaneously expanding surveillance surfaces.
Privacy-preserving execution ensures security gains don’t translate into transparency overreach.
AI-driven hardening only works if privacy is built in from the start. Otherwise, you just get more powerful systems analyzing more exposed data.
Confidential computation, encrypted state, and privacy-preserving execution ensure that verification and risk controls don’t come at the cost of surveillance.