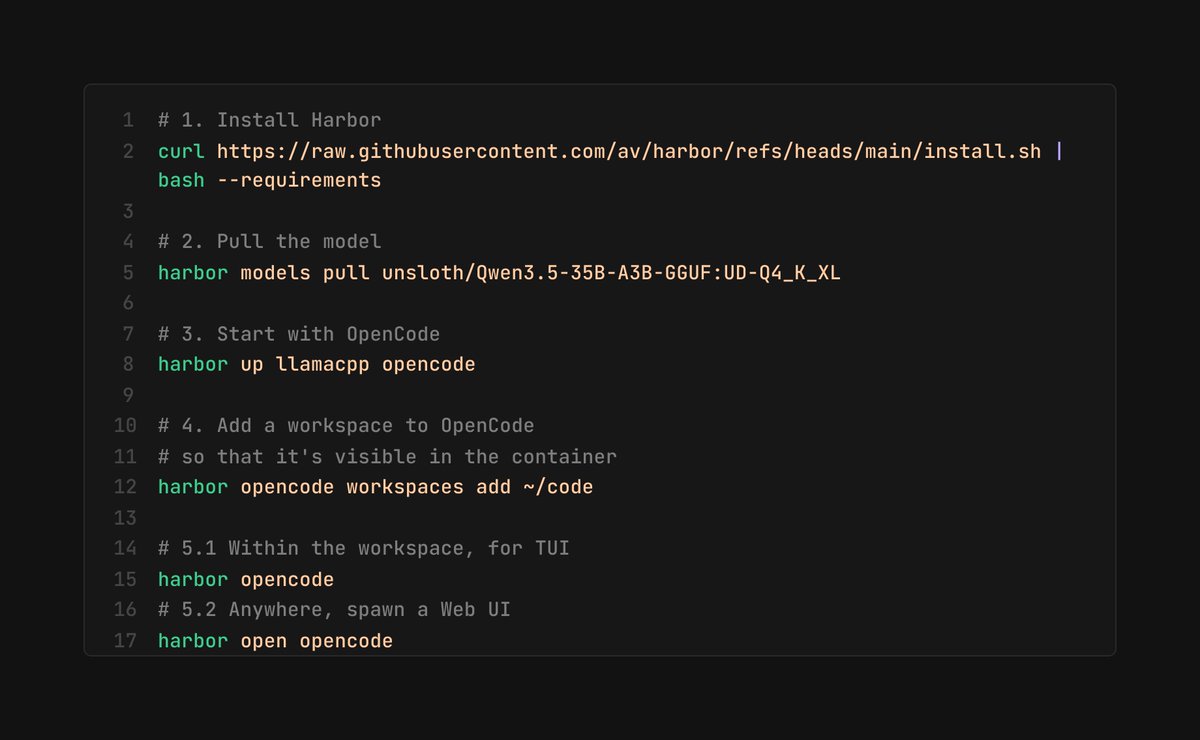
You don't even need Kimi 2.5 for a decent local LLM setup.
- llama.cpp
- Unsloth's Qwen 3.5 35B A3B with UD Q4 K XL quants
- OpenCode
- av/harbor
It'll take a while to download/install, but otherwise it's something that mid-range hardware (>32GB RAM, ~8GB VRAM) can run today.
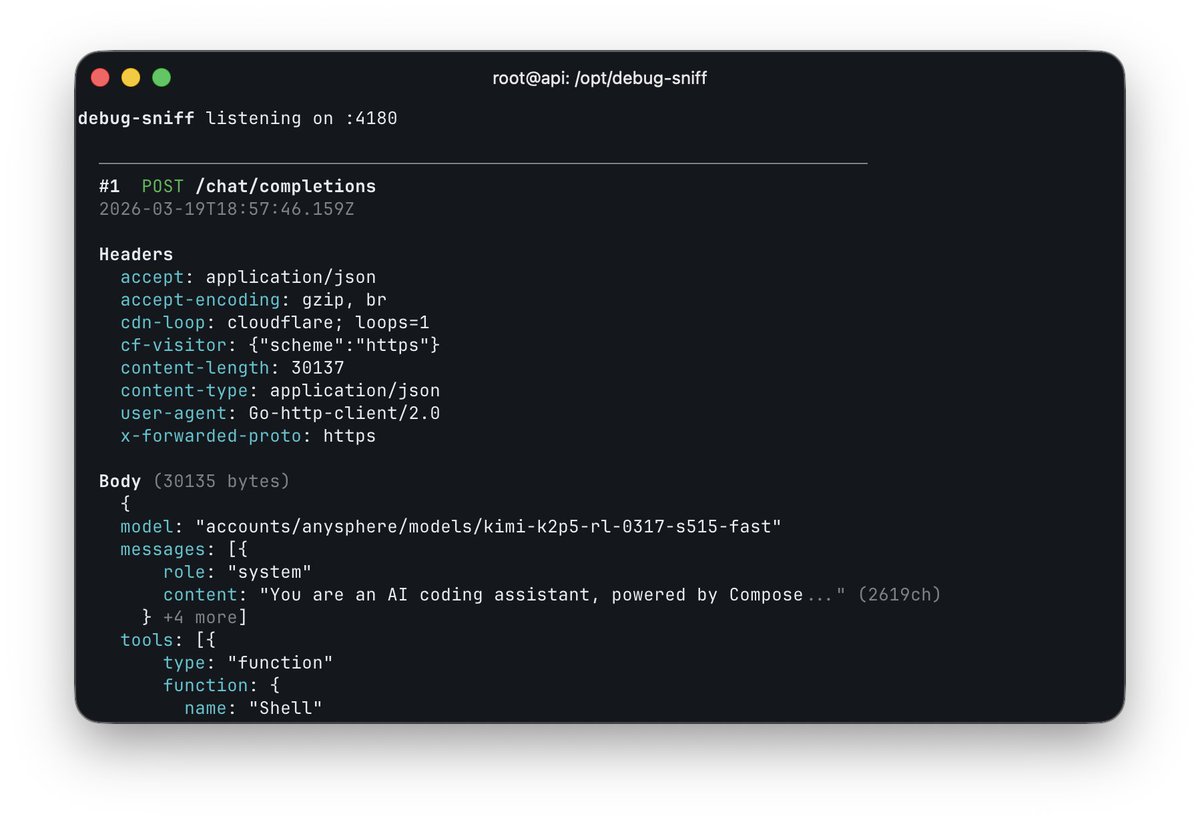
was messing with the OpenAI base URL in Cursor and caught this
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast
so composer 2 is just Kimi K2.5 with RL
at least rename the model ID
@Mayhem4Markets Agreed, I was really hoping that when they release Gemini 3.5 it'll give enough "headroom" for a larger Gemma to avoid overlap in the capability, still hoping :)
@ajaxdavis I think your understanding is spot on! Agentic CLIs should return a little extra information/instructions for the agents where it gives more context about the task at hand
@melvynx I think there's little reason not to optimise for the agents as the main users right away
Splitting in various skills helps with progressive disclosure a bit, since showing everything all at once might be a bit too much
Maybe it's a mix of things:
- I'm running the XL quant, it's ~10% larger
- llama.cpp version differences + Vulcan vs. ROCm differences
- this was in a container
Anyways, I think Strix Halo's sweet spot are models with 3-4B active parameters per decoding pass, so this model is a tad outside of that. I think Qwen with MTP gives same TPS, but with benefits of a larger model. This one is great for 12GB-16GB GPUs though
@andreafspeziale@mattpocockuk Yes, remote workspaces can also solve this same problem!
To be honest, I think that's how most development should happen this day, with a thin client, because of all the risks associated with agentic tooling
@amsalemadir@resend I think agentic use will be the main type of use for many of such tools, so optimising for it is increasingly important, especially for new tools that are not present in the training data at all
@crack3nnn It's not "the best coding model" or "the fastest coding model", but I found that it hits the sweet spot on cost/speed/quality, worth a try if you already have it available
I've only started using it recently, but Grok Composer 2.5 took top spot as my most used model in the last few days.
It's not Opus, but it's not far off.
It adheres to instructions much better than Claude, more similar to GPTs in this aspect.
It's quick.
So, I do slow planning/exploratory sessions with Opus 4.6, and then I let Composer 2.5 execute on those plans. It's been pretty pleasant.
@hitsmaxft Yes, absolutely! A CLI can shape and guide how agent is using it, by providing extra instructions or higlighting external state, there's a lot of extras to provide better agentic experience
If you're building a CLI of any kind, add a section for agents to the help, also add a command for agents to load skill contents related to the usage of the CLI.
agent-browser is a great example and I think more tools should follow the same template.
@c0mm0n_dev_us3r Great! For agentic experience it also helps to provide some extra context alongside the command outputs, it often means a difference between a successful and a failed task
@dibstern@mattpocockuk Gateway means that it's a proxy, a passing point, not where the inference happens on its own.
Our gateway specifically has full agentic loop, so yes, it matches a definition of a harness, it's essentially a fully featured cloud agent with OpenAI/Anthropic compatible API.
I'm in awe, there's a pocket dimension of style and drip in LLMs, you just need to discover it
It's so bad that it comes from the other side as being good. This over colored border-left any day of the week.
@davidmytton Yes, as well as enriching output a bit for agents, even a single status/state line might often help agent to stay on track with what they are doing, ack/nack or explaining effects of the command. I think good AX really helps