✨ Creativity is not just recognizing what an object is — it is imagining what it could become.
🔧 A key edge can cut tape.
🛡️ A rubber pad can protect a wall.
🪮 A comb guard can clear a sink slot.
But can multimodal AI agents discover these hidden physical affordances from images?
🚀We introduce MM-CreativityBench, a benchmark designed to test whether LMMs can creatively repurpose everyday objects by interactively inspecting scenes, entities, and object parts.
🔍 Our findings show that today’s LMMs often identify the right object, but fail to ground their reasoning in the right part. They hallucinate properties, overlook physical constraints, or propose solutions that are not mechanically valid.
🧠 To move beyond plausible guesses, we propose affordance-grounded alignment: training models to explore visual evidence, reject hallucinated affordances, and reason from geometry, material, and mechanics.
📄 Paper: https://t.co/DW6J06yPHK
🌐 Project: https://t.co/KMDTLKaa0r
💻 Code: https://t.co/4L3LYObPZX
🤗 Hugging Face: https://t.co/XPmrfP0Gie
PlugMem transforms AI agents’ interaction histories into structured, reusable knowledge. It integrates with any agent, supports diverse tasks and memory types, and maximizes decision quality while significantly reducing memory token use: https://t.co/girJeCrr6p
📰New preprint: How can we build a task-agnostic plug-and-play memory module for LLM agents that supports multiple memory types?
We present PlugMem🔌🧠, a plugin memory module that works across tasks by turning heterogeneous experience into knowledge.
Evaluated unchanged on long-term dialogue🗣️, multi-hop QA🕵️, and web agents🕸️🤖, PlugMem improves performance while using far fewer memory tokens.
📜Paper: https://t.co/A8tNQjkCCb
🔨Code: https://t.co/mt1aJKxQIz
🔮 Can a world model (simulator) give today’s AI agents foresight? We tested “world model as a tool”… and found it often doesn’t help—sometimes it hurts.
Check our newest paper here: https://t.co/nujSGeHKMx
#AIagents#WorldModel#ToolUse
Thrilled to share our paper MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning (https://t.co/FT7zzXvF3c) won an EMNLP 2025 Outstanding Paper Award! 🎉🎉
Huge congrats to the team @evangelinejy99@RuiYang70669025@YifanSun99@FengLuo895614@rui4research, and big thanks to our advisors Prof. Tong Zhang and @hanzhao_ml!
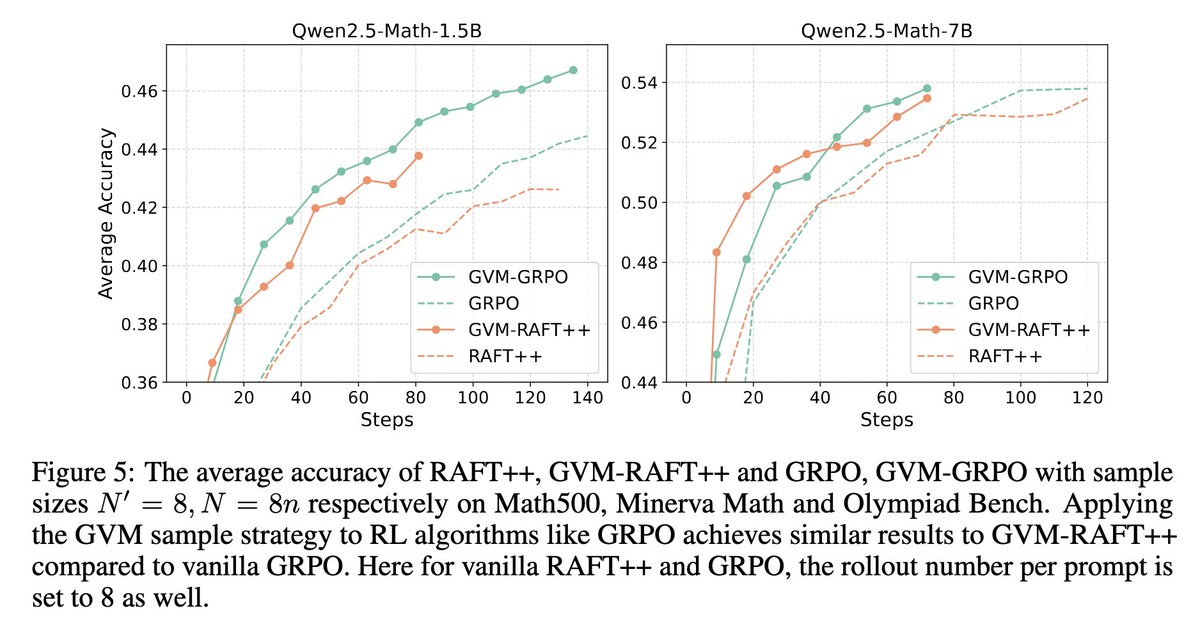
Glad that our paper has been accepted to Neurips 2025! By gradient variance minimization (GVM), we balance the training data by difficulties and their contribution to the model. We achieve improvement on math reasoning. Please check the original post for more details.
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs.
– Achieves 2–4× faster convergence than RAFT
– Improves accuracy on math reasoning benchmarks
– Generalizes to reinforcement learning methods such as GRPO
– Comes with theoretical convergence guarantees
📄 Paper: https://t.co/3CuExbJANR
🔗 Code: (expected in a few hours) https://t.co/vFO3mWIM8A
#LLM #MachineLearning #ReinforcementLearning #ChainOfThought #AIResearch
(1/5) Super excited to release our new paper on Reinforcement Learning:
"Self-Aligned Reward: Towards Effective and Efficient Reasoners"!
Preprint: https://t.co/Bwy1y2UPl6
🤝 Can LLM agents really understand us?
We introduce UserBench: a user-centric gym environment for benchmarking how well agents align with nuanced human intent, not just follow commands.
📄 https://t.co/1dnzD3il0t
💻 https://t.co/hZuI2ZQTKE
Reward models (RMs) are key to language model post-training and inference pipelines. But, little is known about the relative pros and cons of different RM types.
📰 We investigate why RMs implicitly defined by language models (LMs) often generalize worse than explicit RMs
🧵
1/6
🎥 Video is already a tough modality for reasoning. Egocentric video? Even tougher! It is longer, messier, and harder.
💡 How do we tackle these extremely long, information-dense sequences without exhausting GPU memory or hitting API limits?
We introduce 👓Ego-R1: A framework for reasoning over ultra-long (i.e., in days and weeks) egocentric videos, with the support from Chain-of-Tool-Thought (CoTT) that decomposes complex reasoning tasks into modular steps. At its core is Ego-R1-Agent-3B, an orchestrating language model trained to dynamically invoke specialized tools at each step, based on the previous actions and observations, to collect the necessary information and solve the tasks gradually, step-by-step.
All code and data are fully open-sourced :)
🌐 Project: https://t.co/FabClcYzLr
📄 Paper: https://t.co/YmxFM6eFyV
💻 Code: https://t.co/9MkpxJhsjs
Can LLMs make rational decisions like human experts?
📖Introducing DecisionFlow: Advancing Large Language Model as Principled Decision Maker
We introduce a novel framework that constructs a semantically grounded decision space to evaluate trade-offs in hard decision-making scenarios transparently.
📑Paper: https://t.co/ItbbRHbjCL
💻Code: https://t.co/74HduQTfMY
🧵👇
(1/5) Want to make your LLM a skilled persuader?
Check out our latest paper: "ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind"!
For details:
📄Arxiv: https://t.co/680ddg9tVW
🛠️GitHub: https://t.co/iMxSSGvY7D
📢 New Paper Drop: From Solving to Modeling!
LLMs can solve math problems — but can they model the real world? 🌍
📄 arXiv: https://t.co/8uT99ZtC7M
💻 Code: https://t.co/aryBCh3d0a
Introducing ModelingAgent, a breakthrough system for real-world mathematical modeling with LLMs.
How to improve the test-time scalability?
- Separate thinking & solution phases to control performance under budget constraint
- Budget-Constrained Rollout + GRPO
- Outperforms baselines on math/code.
- Cuts token 30% usage without hurting performance
https://t.co/KqJvMTeXbV
🚀 Can we cast reward modeling as a reasoning task?
📖 Introducing our new paper:
RM-R1: Reward Modeling as Reasoning
📑 Paper: https://t.co/VxuZ8JuhUJ
💻 Code: https://t.co/R583Hib26g
Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. RM-R1 achieves state-of-the-art or near state-of-the-art performance of generative RMs on RewardBench, RM-Bench and RMB.
🧵👇
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs.
– Achieves 2–4× faster convergence than RAFT
– Improves accuracy on math reasoning benchmarks
– Generalizes to reinforcement learning methods such as GRPO
– Comes with theoretical convergence guarantees
📄 Paper: https://t.co/3CuExbJANR
🔗 Code: (expected in a few hours) https://t.co/vFO3mWIM8A
#LLM #MachineLearning #ReinforcementLearning #ChainOfThought #AIResearch