New high-resolution images of manuscripts are clearer, but they are not always better. The images below demonstrate the importance consulting older images. Manuscripts degrade.
Here P45 has, ironically, lost the word ολη, "whole"
I just updated my Greek Minuscule LLM HTR Benchmark and added the latest frontier models in addition to some open weight and other models.
Some spoilers: Gemini is still far ahead, Grok and Llama are the worst of the worst.
Let’s compare Fagles and Wilson on the proem to the Odyssey. Their skopoi differ. Wilson wants the same number of lines as the original; Fagles wants everything the original says. Wilson gives you the pace; Fagles its imagery. Both convey and both betray the original. >
@wjb_mattingly Very cool! I've also had some luck with small models working better when asked to output YAML instead of JSON.
Is it the fine-tune that really made the difference? I've been experimenting with stock Qwen 3.5:0.8b and it just reasons FOREVER, especially compared to Gemma 4:E2B
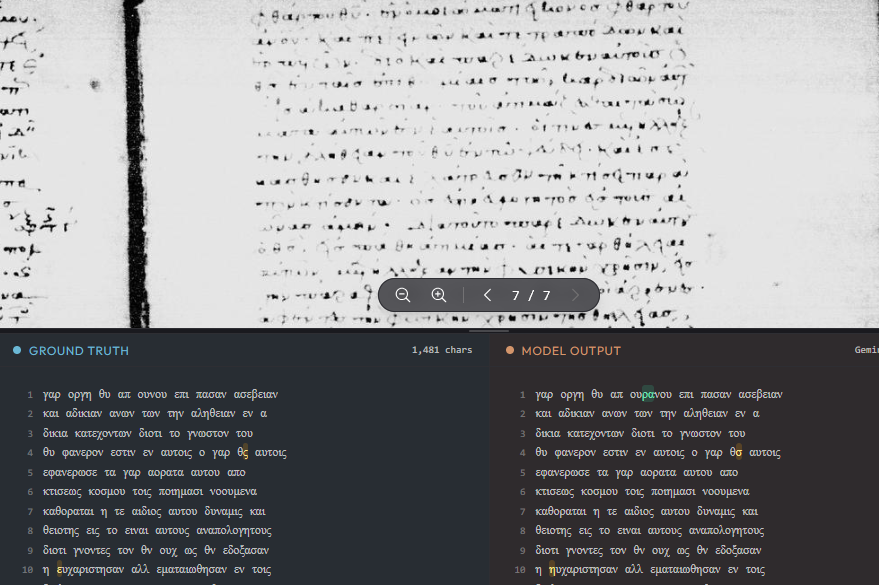
I've just published a simple multi-modal model bench test for how current frontier models transcribe Greek minuscule manuscripts.
https://t.co/skp2xnT19e
You can see the human transcribed transcription side by side with the model transcription with IIIF image viewer.
@KoineGuide I have a transcription/collation/analysis virtual research application that I am half way refactoring. The original version is here https://t.co/mM7XaWECJH
Apatosaurus 2.0 has a fully featured transcription interface and I'll probably let people bootstrap their transcriptions.
@nelson_hsieh7 My test images are high resolution, but did you see all 5? Some have faded text and multiple colors.
I'm happy to add more test cases to track. I just need an image of a single page that exists in a IIIF manifest (then I can automatically respect usage permissions).
@KoineGuide Do you mean their generative image model API? No, all of these models are multi-modal, so they accept images and text as input.
I've been running a simpler version of this bench test for a while and Gemini models have always been way ahead of OpenAI for this use case.
@nelson_hsieh7 I don't think they can be trusted for mass transcription yet, but I am working on a feature for using Gemini to bootstrap a basetext to use during human transcription. It will have most of the line breaks right and be close enough to save some of the toil.
This is a PSA to my friends and colleagues that if you're looking for a privacy focused web browser, don't use Brave. It is shady. Go ahead and use Zen, Vivaldi, or Helium.
@CSNTM's new digital collections website is launching today.
I enjoyed engineering and building this website. It was refined with feedback from various people, but I hope researchers especially find it useful since it was built by one!
https://t.co/QZDUqTJqQj
@thdxr Rich/Textual are so good, so easy, that I'm confused why so teams are working so hard to get React-for-CLI working that they bought a runtime. Could at least just have cc port Textual to JS for you
It has been a few years since I refreshed the styling of my personal website, https://t.co/dauegYiGfo
It was a Django site but now a free-forever static site.
We been talking about how generative AI produces average results.
I've been thinking about pastors who use AI to write their sermons.
I'd bet that this is an upgrade for a lot of churches. It must be true that for many, this means better sermons because the floor is higher.