this is my personal singularity moment
this post may sound like a paid ad. I only wish. I'm concerned, more so than happy. the world is changing, and, among the scenarios where AI goes terribly wrong, inequality is the most realistic, yet, the one Anthropic seems to be the least concerned about. I'm glad OpenAI is taking the opposite stance: *personal AGI for everyone*. I think this is a commendable position in the times we live. but who am I in the queue of the bread?
anyway, Fable is here, so I'll just report my first-hour experience
first of all, all my pet prompts are solved.
→ λ-calculus puzzles
→ bug questions
→ one-shot apps
all are trivial to it.
I don't have anything harder other than my
ongoing work
so, in the last several days, I've been toying with HVM5, a new interaction net evaluator with a faster loop.
after writing the first version, I left 32 GPT-5 agents working for ~20 hours each. this resulted in up to 2x speedups, but the file size increased by 2-fold and quality decreased significantly.
I then simplified the whole thing into an even simpler core, and left Opus 4.8 and GPT 5.5 optimizing it for 8 hours. Opus got a legit 6% - 34% speedup in most benches. GPT got better results, but, sadly, an unusable file.
I then asked Fable to optimize it.
2 hours later, it landed a 1770% speedup in one case, 100%+ in other 4, and 22% in average. yes, in 2 hours it outperformed me, opus 4.8 and a swarm of gpt 5.5 agents, by one order of magnitude.
that could not possibly be legit. "it must be hardcoding the benchmarks" (GPT trauma). so I read its explanation and what it did was, indeed, the most high impact optimization one could try first. seems like HVM5 was wasting a lot of time garbage-collecting unused branches of pattern-match nodes. I had optimized that for static mats, but not for dynamic mats. skill issue. Fable figured how to do it for these, resulting in a massive speedup in some benches
but wait, is that *correct*? I'm not sure yet, it is credible, but this is the kind of thing that is very easy to get wrong on interaction nets. the problem is, when I was ready to start auditing Fable's solution so I could tell whether it was buggy or legit, it interrupted me to tell me it had found a massive bug on the code *I* had written.
... wait, what?
so... for garbage collection purposes, I stored a bit on lambda term pointers that meant "the variable bound by this lambda has been freed, so, its lambda must free whatever argument it is applied to". that's fine. yet, on duplicator nodes, I also used the same bit to mean "one of the duplicated variables was freed, so, treat this dup as a passthrough no-op". so, if a lambda entered a duplicator, it would mistake the lambda's collection bit for its own, resulting in corrupted interaction!
that's a mouthful, why I'm writing this?
just so you can appreciate the sheer absurdity of what just happened. I didn't ask it to find bugs. I asked it for an optimization. and even if I did ask it to find bugs, this bug is so astonishingly subtle and specific, identifying it takes mastering the domain to an extent that it beyond even me. I'd easily need hours or days to fix it, *if* I ever came across it. chances are it would just go unnoticed. and Fable found it and fixed it like it was nothing, while it was busy adding a 17x speedup to a file that neither I, nor Opus 4.8, nor a fleet of GPT 5.5 managed to barely make 2x faster.
oh and there is also another tab where it is also ripping through Bend's codebase and finishing everything I had to do
I don't know what to say anymore
this isn't about Anthropic or OpenAI, this is about our collective future as a species. the world is changing, and we need to be aware of it, and discuss how to handle this change.
receipt below . . .
Bought and added 2x to EVC, stopped out today. Above my entry price now.
Tried RXT 3x yesterday, stopped out all 3x. Up 60% today.
Bought INTC on the gap to 85. Stopped out same day.
Bought NBIS around 140. Couldn't hold above 21ema. Exited. Took my eyes off it watching something else. Rallies to 190 in 4 days.
Bought FLY on the earnings gap on 3/20. My buy stop triggers around $25.50, I see the price start going vertical. I can't cancel the order in time. $1.30 of slippage on 50k shares, 20 cents of slippage on the same day stop out. I watch it go to $45 over the next few weeks without me.
Bought CRWV above the HVE day on 4/13. Rallies 18%, pulls back to entry. Takes out LOD and stops me out by 80 cents. Rallies 31% straight up over the next 6 days.
Everyone who trades goes through this. I've lost 75% of my trades this year and most of them go like that. Stop out, round trip, etc. There's no secret, there's no magic. Just execution. Trusting the few winners will be enough to make up for all the losers.
SUSPICIOUS OIL TRADES BEFORE IRAN WAR HEADLINES TOPPED $7B: REUTERS
Well-timed bets on oil markets ahead of major Iran war announcements totaled at least $7 billion, far more extensive than previously reported, according to Reuters.
The trades, placed across crude, gasoline, and diesel futures in March and April, spanned multiple exchanges and contracts, raising fresh scrutiny over possible insider positioning around market-moving developments.
There have been issues connecting to @IBKR using @tradingview for over a week and no confirmed date for resolving the issue. Can you confirm what is going on?
I don’t even know what level of chess we are playing when we are removing sanctions to allow Iran to sell its oil freely at $100/barrel in the middle of war.
BREAKING: We just gave Claude access to the entire options and stock market and it's not a demo.
It's the Unusual Whales MCP Server. It plugs directly into any AI assistant and gives it live, structured market data on demand.
Build a trading bot. Build a finance dashboard. Build a screener. Build whatever you want.
A thread:
Automations already run thousands of times per day inside our own codebase! They power self-healing CI, auto-approving PR flows, highly-compute-intensive security review, and a team-wide memory system.
One small step toward a self-driving codebase...
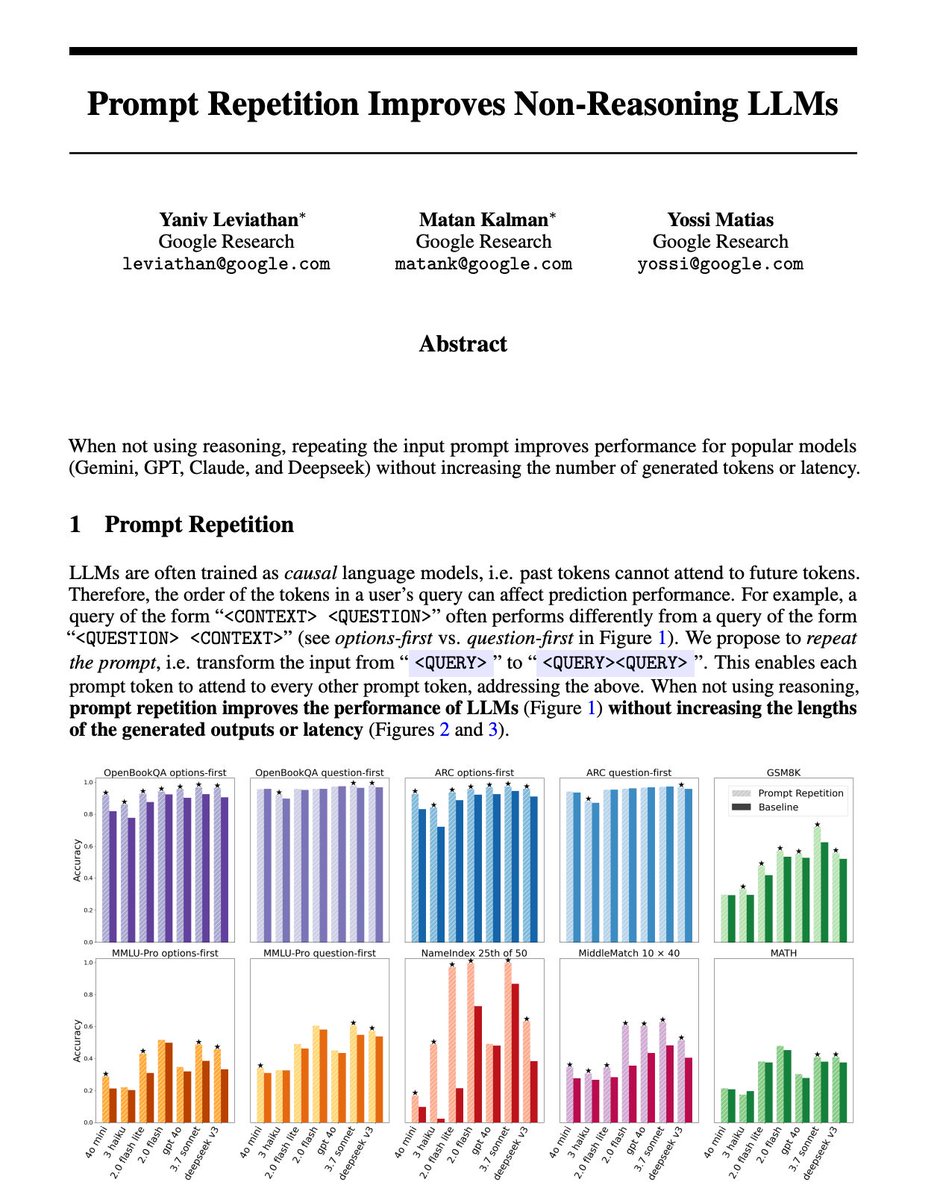
Google just proved that pasting your exact prompt twice beats every advanced prompting technique.
One model jumped from 21% to 97% accuracy with zero extra effort.
Here's the science behind AI's simplest hack:
LLMs like GPT-4o and Claude read your prompt left to right, one token at a time. Early words can't "see" later words on the first pass.
When information appears in an awkward order, like answer choices before the actual question, the model struggles to connect the pieces.
By repeating the prompt, every word in the first copy becomes visible context for the second copy. The model gets a "second read" with perfect attention across your entire input.
Like reading an exam question twice before answering. Same effort, better comprehension.
The results were staggering ↓
Google tested Gemini 2.0 Flash, GPT-4o, GPT-4o-mini, Claude 3 Haiku, Claude 3 Sonnet, and DeepSeek V3 across seven benchmarks.
Across all 70 combinations, prompt repetition delivered 47 statistically significant wins with zero losses.
But here's the result that broke the scale:
Google gave Gemini 2.0 Flash-Lite a task where the AI had to find a specific detail buried inside a massive prompt.
Without repetition, it got the right answer just 21% of the time. With one copy-paste, accuracy jumped to 97%.
Same model. Same task. The only difference was reading it twice.
Skeptics had a theory: maybe longer inputs just help in general?
Google tested that too. They padded prompts with periods to match the length, and it made zero difference. Only meaningful repetition works.
And the best part?
It adds almost no extra processing time because the repeated input runs in parallel.
But there's one scenario where it doesn't help ↓
Chain-of-thought prompts like "Think step by step" already re-read and rephrase your question internally.
They're doing the repetition for you. Out of 28 reasoning tests, only 5 showed improvement.
This means prompt repetition is most powerful for:
• Classification and multiple choice tasks
• Data extraction and short-answer Q&As
• Direct-answer tasks where order sensitivity matters
The practical takeaway:
1) Take your exact prompt
2) Paste it twice as one message
3) Send it and change nothing else
This works across every major model family. Gemini, GPT, Claude, DeepSeek. All of them.
The simplest trick in AI history: if you want a better answer, just ask twice.
—
Thanks for reading!
Enjoyed this post?
Follow Big Brain AI for more content like this.
Love that it was a grad student at @UMassAmherst who found the error. He was in a class where they had an assignment to replicate results of famous studies and couldn’t get this one right. He emailed them and they sent the original Excel file, which is how the whole mess unraveled. Insane.