“design a RAG pipeline for 10M docs with zero hallucination”
apparently this was asked in a Google L5 interview round. came across it somewhere on the internet and honestly it’s a way more interesting system design problem than most classic distributed systems questions
1. ingest + normalize docs
- remove duplicates, standardize formats, extract metadata, maintain version history
2. hybrid retrieval (BM25 + embeddings)
- BM25 handles exact keyword matching while embeddings capture semantic meaning
- semantic search alone usually struggles with precision at massive scale
3. ANN retrieval + reranking
- ANN (Approximate nearest neighbor ) quickly pulls top candidate chunks from millions of docs
- then a reranker rescoring step improves relevance by deeply comparing query vs retrieved chunks
4. source confidence scoring
- every retrieved chunk gets scored based on freshness, trust level, overlap and retrieval consistency
- low-confidence context should never heavily influence generation
5. constrained generation
- the model is only allowed to answer using retrieved context (nothing new to be invented outside of the retrieved context)
6. citation-backed responses
- every major claim links back to exact chunks, documents or timestamps
7. hallucination fallback layer
- if retrieval confidence drops below a threshold: “insufficient evidence found”
8. continuous evals
- run adversarial queries, retrieval recall benchmarks and hallucination tests continuously
9. caching + memory layer
- cache high-frequency enterprise queries and retrieval paths (improves latency and output)
10. observability everywhere
- trace retrieval paths, chunk rankings, token attribution and failure points
Also at 10M docs, retrieval quality matters more than the frontier model itself.
when I started running local models a few weeks ago, I knew absolutely nothing.
what's GGUF. what's quantisation. why does my GPU run out of memory. what the hell is a MoE expert.
now I know maybe 1%. I am still massively ignorant about most of this. but that 1% feels like I learned a ridiculous amount.
I wrote this guide because it's exactly what I needed and couldn't find when I started. just "here's what each thing actually means and here's the command that works."
if you've been curious about local LLMs but felt intimidated by the setup, have a good read.
These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of 50 LLM interview questions - shared by Hao Hoang.
What's covered:
Fundamentals:
→ Tokenization and why it matters
→ Attention mechanisms in transformers
→ Context windows and their tradeoffs
→ Embeddings and initialization
→ Positional encodings
Fine-tuning & Efficiency:
→ LoRA vs QLoRA
→ PEFT to prevent catastrophic forgetting
→ Model distillation
→ Adaptive Softmax for large vocabularies
Generation & Decoding:
→ Beam search vs greedy decoding
→ Temperature, top-k, top-p sampling
→ Autoregressive vs masked models
Advanced Concepts:
→ RAG (Retrieval-Augmented Generation)
→ Chain-of-Thought prompting
→ Mixture of Experts (MoE)
→ Knowledge graph integration
→ Zero-shot and few-shot learning
Math & Theory:
→ Softmax in attention
→ Cross-entropy loss
→ KL divergence
→ Gradient computation for embeddings
→ Vanishing gradient solutions in transformers
You don't need to follow me (@techNmak) and comment "LLM". I will put the link in the comments.
DROP EVERYTHING
The bible for running LLMs locally is now available online to read for free
Covers what to use on
- Laptop / edge / odd hardware
- Mac-first workflows
- Single RTX GPUs
- 2-4+ NVIDIA / CUDA GPUs
- General production serving
- Long-context / MoE / routing
- NVIDIA max performance
- Cluster orchestration
Software
- llama.cpp
- MLX / MLX-LM
- ExLlamaV2
- ExLlamaV3
- vLLM
- SGLang
- TensorRT-LLM
- NVIDIA Dynamo
You should read this, and if you cannot now then you most definitely wanna bookmark it for later
Local AI FTW
GITHUB JUST CREATED AN OFFICIAL CERTIFICATION FOR THE MOST IN-DEMAND DEVELOPER ROLE OF 2026.
It is called Agentic AI Developer.
GH-600.
And it is the first formal signal that running AI agent teams is now a recognized engineering discipline with a credential behind it.
Not a prompt engineer.
Not a vibe coder.
An Agentic AI Developer.
The person who operates, supervises, and integrates AI agents across the entire software development lifecycle.
The person who knows where agents fail in production.
The person who understands how to build autonomous workflows that do not introduce catastrophic failure modes into CI/CD pipelines.
The person every engineering team is going to need and almost none of them have right now.
GitHub certifying this role changes the hiring conversation permanently.
Before GH-600: "Do you work with AI agents?" is an interview question with no standard answer.
After GH-600: the credential tells the hiring manager exactly what you know and what you can do before the interview starts.
The engineers who get certified in the first wave of GH-600 will have a credential for a role that has more demand than supply for the next 3 to 5 years.
The engineers who wait until it is mainstream will be competing with everyone who moved first.
If you are already working with GitHub Copilot or building agent-driven workflows you are already doing this job.
GH-600 is how you prove it.
Bookmark this.
Follow @cyrilXBT for every AI certification worth your time the moment it drops.
A little talk on what we can learn from implementing LLM architectures from scratch in Python and PyTorch.
And how I approach new open-weight models, compare them against reference implementations etc:
https://t.co/crKd2l9xGg
As an AI Engineer. Please learn:
-Prompt caching & semantic caching tradeoffs
-KV cache management at scale
-Speculative decoding vs quantization
-RAG evaluation (RAGAS + human evals)
-Cost monitoring & hidden token leaks
-Agent guardrails & infinite loop detection
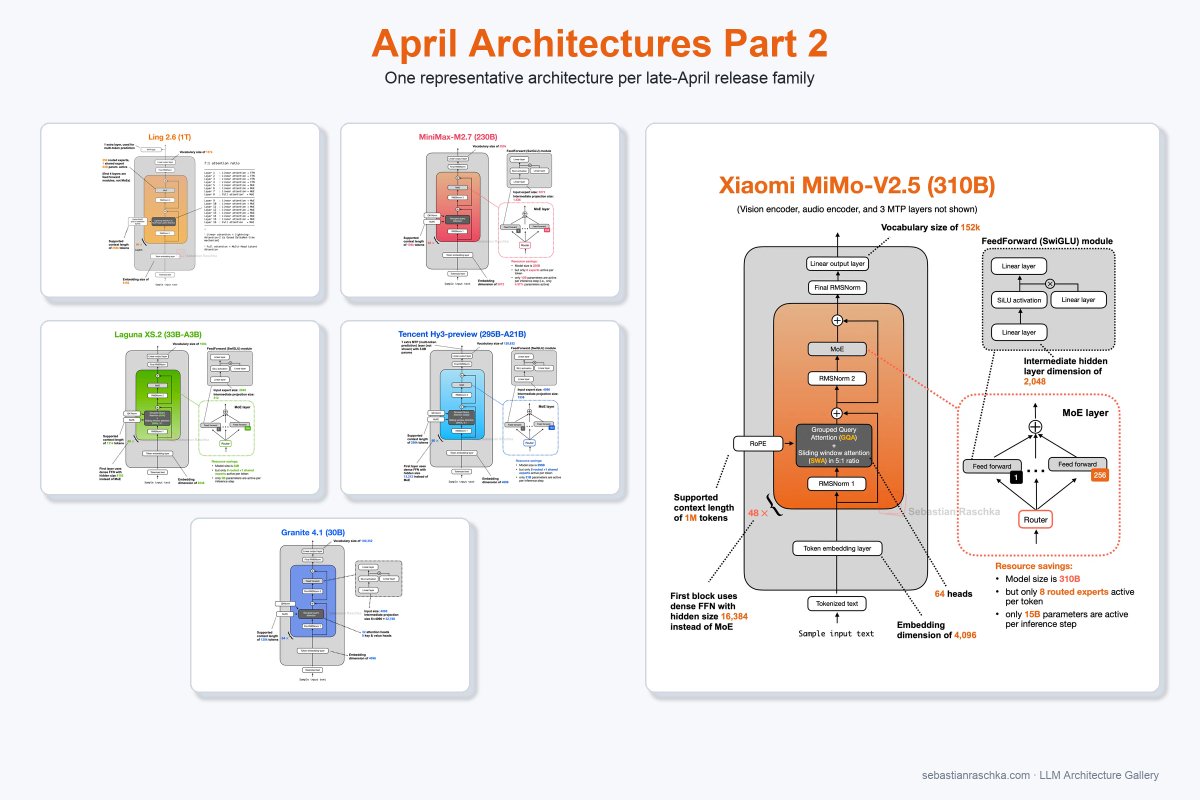
Here is a 2nd batch of April architecture drops. What a month!
- Ant Ling 2.6 1T
- Minimax M2.7
- Xiaomi MiMo V2.5
- Poolside Laguna XS.2
- Tencent Hy3-preview
- IBM Granite 4.1
we are so cooked 😭
these guys let Claude run wild on Wall St.
Look at this insider trades scanner it built in 4 mins that:
> reads every SEC filing where execs buy their own stock
> flags clusters where multiple execs buy at once
> emails me the top 3 trades every morning before the open