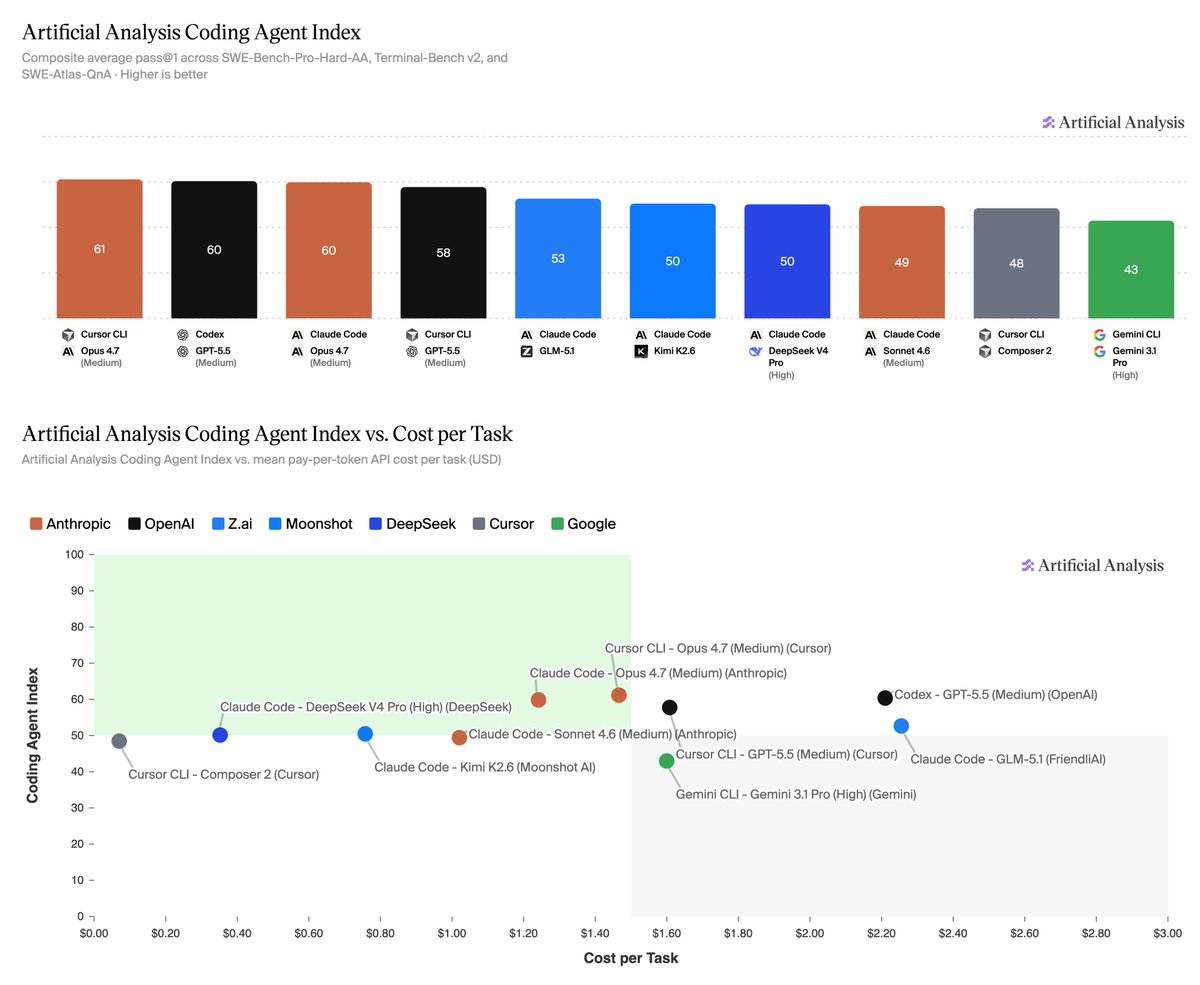
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
This release shows increased cost efficiency to run the Artificial Analysis Intelligence Index, with Grok 4.3 sitting comfortably on the Pareto frontier for intelligence versus cost
Driven by 37.5% lower input token prices and 58.3% lower output token prices, it costs $395 to run the Intelligence Index evaluations, an overall ~20% decrease from Grok 4.20 0309 v2
¿A quiénes contrata Vercel? La respuesta es: a aquellos que sepan usar Inteligencia Artificial. Su CEO está buscando personas que sepan realizar prompts y manejar a los agentes de IA para maximizar resultados.
Conocé la visión de Guillermo Rauch: https://t.co/ZGfZLtfRPE
@unclebobmartin Its great that I see you focused in agent coding regarding design principles and engineering practices. It would be great a book exclusively about agent coding but optimized with the clean code book series rules and practices. How to auto-enforce clean code ?
Over 4,500 unique agent skills have been added via 𝚗𝚙𝚡 𝚜𝚔𝚒𝚕𝚕𝚜 from major products across the ecosystem:
• @neondatabase
• @remotion
• @stripe
• @expo
• @tinybird
• @supabase
• @better_auth
Find new skills and level up your agents at https://t.co/wcRHxRUm9u
You've seen these paintings a million times.
But never like this.
Using nano-banana, Seedance, and Kling, I brought them into our modern world, creating an unlikely romance in Central Park, New York City.
Enjoy:
Minimum Awesome Product debería ser el objetivo en vez de MVP. Parece solo terminología pero el objetivo de "viable" puede terminar en un producto de baja calidad que no cumple las expectativas.
ASP .NET Core Best Practices 💡
#dotnet
Nice article providing guidelines from Microsoft for maximizing performance and reliability of ASP .NET Core apps.
Which of these techniques are you using in your apps right now?
Link in 2nd tweet below.