friendly reminder! tomorrow is the deadline to submit a paper for the @I3Open Technical Working Group:
https://t.co/gOz1i1F1Yv
as I've written before, this is not a typical academic conference. we're focused not on research results but on *datasets* and methods for building datasets.
this year we're especially interested in the use of LLMs and other machine-learning methods for building and linking large-scale data, including how to take advantage of these new tools in a cost-conscious way.
Happy to announce our next i3 Upskilling session, Thursday August 21 at noon (New York time / EDT).
➡️"Using Large Language Models without Blowing Your Research Budget"⬅️
Hosts: Navid Asgari (Fordham) and Deepak Nayak (OSU)
Register here: https://t.co/7ECftaPAAn
I’m happy to announce our next @I3Open Upskilling session, Thursday August 21 at noon (New York time / EDT). By far, our most requested topic was Large Language Models, so I’m excited that I was able to enlist Navid Asgari (Fordham) and his coauthor Deepak Nayak (OSU) for this session. Navid co-founded Cogneunce, an AI-based mental healthcare startup and is also a research fellow at IBM Watson. here's a summary:
Large language models (LLMs) are opening new possibilities for research, especially in tasks like classification, sentiment, or theme extraction, and sub-corpus analysis. But navigating the growing range of models and tools can be overwhelming, and many researchers worry about cost, data quality, and hallucination. This session offers a practical, research-focused overview of how to use LLMs effectively and affordably. We’ll compare model types, discuss open vs. closed access, and walk through strategies like prompt design, retrieval-augmented generation (RAG), and lightweight fine-tuning. The focus will be on helping you choose the right tools for your research tasks, without compromising on accuracy or breaking the bank.
Sound interesting? Register for the zoom at this link: https://t.co/xuyBoGRVEW
brief update: we just received word that the PatentsView contract has been renewed for an additional year, starting tomorrow.
I'm not sure what will happen next year, but for now the data will continue to be updated.
Quick update regarding PatentsView metadata: the final datasets, including granted, pre-grant and beta tables, are now available on the I3 BigQuery data repository.
Link: https://t.co/9fj5apAcED
Join our mailing group: https://t.co/TZ8SZge9xK
update: unclear that the patentsview site will come down today (no formal announcement yet), but just in case we've posted all data from the 12/31/2024 release. details here: https://t.co/eD0ap049KV
Update: 3/28 has been confirmed to me as last day for patentsview website. metadata have been posted to a permanent archive, working to find an archive large enough for the remaining ~220G of (compressed) full-text files.
Dear Friends, we were advised earlier today that the PatentsView data many of us rely on may soon shut down. @I3Open has archived all metadata and full-text file, both granted and pre-grant. We plan to upload these to our BigQuery Workspace shortly & will update when complete.
huge thanks @rogermasclans for leading our first @I3Open Upskilling session!
Roger did a 75 minute live demo of big-data wrangling using Google BigQuery and the i3-nber data repository.
here's the recording (https://t.co/tMSIZNpl5R) for anyone interested.
🚀Please join us for our first @I3Open Upskilling Session, "Intro to Google BigQuery" by @rogermasclans & @DShvadron
Friday 2/21 11am ET
New to BigQuery & SQL? Join our first hands-on webinar to:
🔹 Query massive datasets efficiently
🔹 Optimize costs & avoid common pitfalls
🔹 Use SQL + Python for reproducible research
register here: https://t.co/ihULrNxOHf
I'm looking forward to this! We’re hosting lots of innovation data on the @I3Open BigQuery repo. Join us on Feb 21st for our first webinar. Roger Masclans (@rogermasclans) will cover efficient querying, cost optimization, and key use cases. Register here https://t.co/P7PsPDj4UX
Releasing an open dataset based on @MBikard's dissertation regarding "idea twins." David Hsu and I scaled up his algorithm to the entire Web of Science, scraping Google Scholar to detect adjacent co-citation in PDFs. Here's the server farm in my basement
1/
one last (I promise!) update from @I3Open's big weekend:
➡️the 2025 batch of i3 Fellows⬅️
funded by the Alfred P. @SloanFoundation, Fellows receive a stipend and attend i3 Technical Working Group Meetings.
we seek Ph.D students engaged in open datasets. here is this year's batch, in reverse alphabetical order
1/
thanks everyone for making the 2024 @I3Open technical working group so fun. none of this would have been possible without the support of the Alfred P. @SloanFoundation.
if you would like to join our email list for updates, go here ➡️https://t.co/CzbAhEz2Aj⬅️
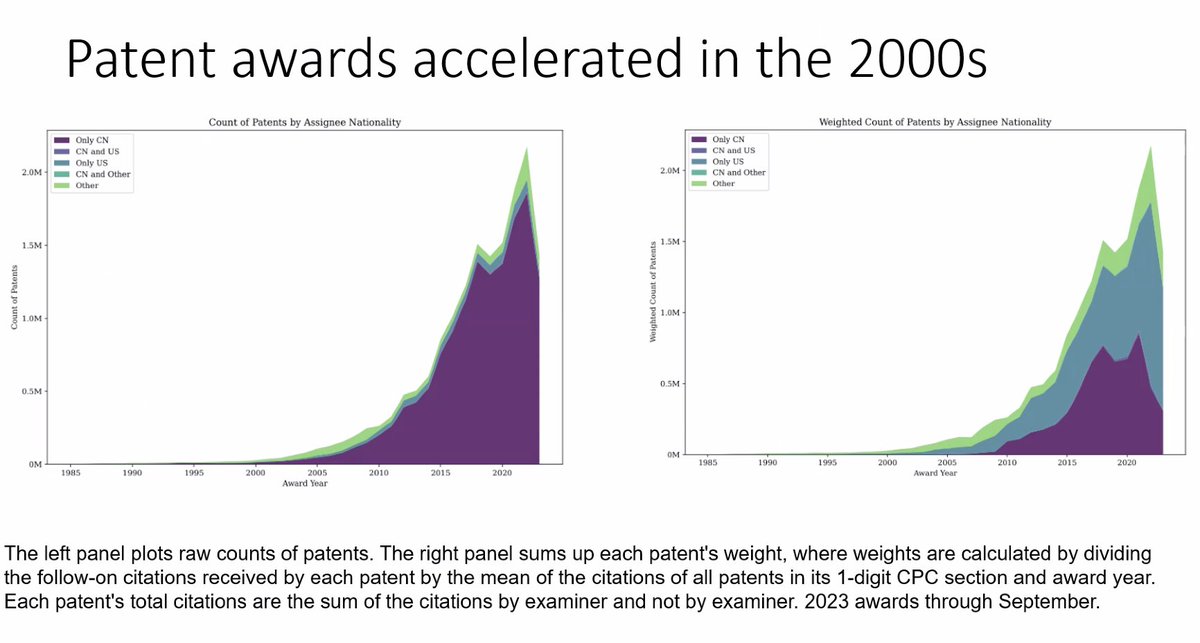
@sat_yaki This includes all patents, whether granted or not, from many sources: leading to 16M patents after cleaning and deduping, with translated assignee names, tags, and non-cite measures of patent quality. #i3
Looking forward to today's Innovation Information Initiative (I3) technical working group! #i3
You can follow the program here:
https://t.co/r9bVSojqcE
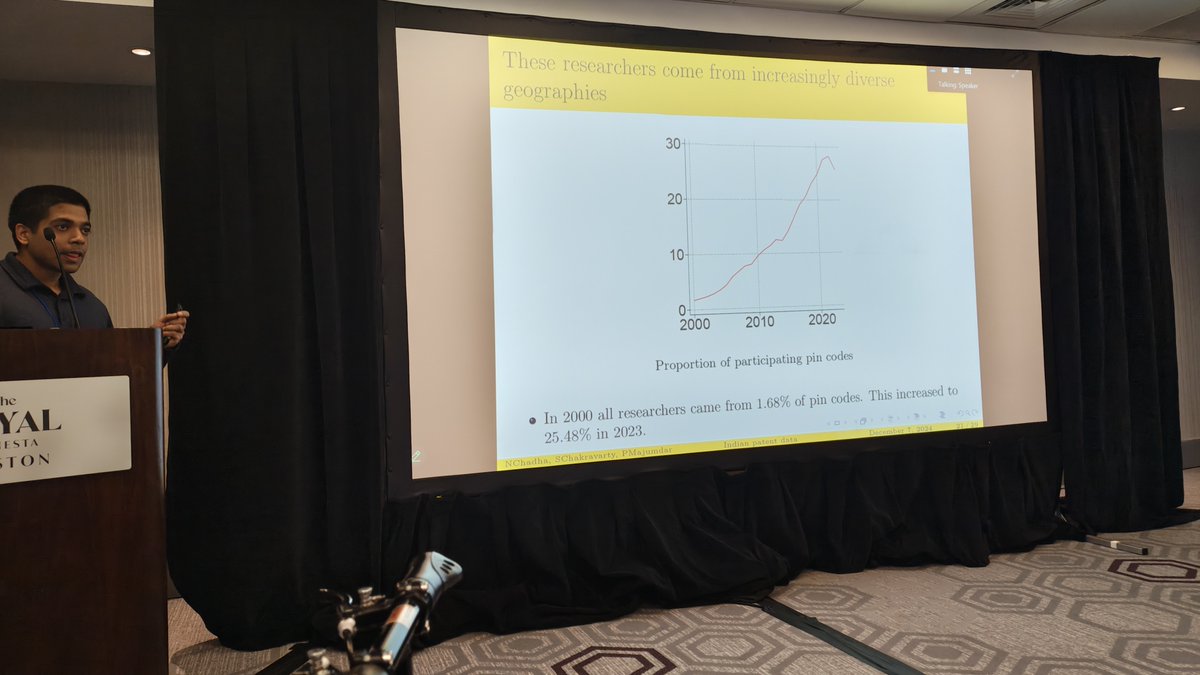
Satyaki Chakravarty (Università Cattolica del Sacro Cuore, Milano) has created a dataset of patents (and applications) in India, which are undercounted in commonly-used sources.
finds increasing geographic diversity of patents in India, a surge in Mumbai, and huge growth in mechanical engineering
key question from Bronwyn Hall: does this mean there's more *invention* in India vs. greater awareness of the practice of patenting inventions
@mayadurvasula, from our first batch of @I3Open Fellows, is back for a 3rd time to show that the performance of commercial LLMs (gpt-4o) can be matched by retraining open\simpler models (BERT) with a small sample of commercial encodings