CV systems depend on diverse datasets to achieve optimal performance. Where data collection involves personal identifiable information, privacy-protecting legislation can impede the acquisition process. A novel face anonymization pipeline capable of running on embedded platforms.
If you are using the Microsoft COCO dataset for a keypoint detection task, we recommend checking out COCOanalyze (https://t.co/K5Hnw7PQSn), as it enables a detailed analysis of the prediction errors and metrics.
Here's an example to our Facediffusion network. The top images are the original, 256x256 resolution images, the middle ones are 64x64 resolution generated images using our diffusion model, and the bottom images are the super resolution, 256x256, anonymized images.
The popular deep learning API, Keras, is getting a new release this fall with version 3.0. A preview, Keras Core, is available right now. Now it makes possible to run Keras workflows on top of TensorFlow, PyTorch or JAX. Read the announcement here:
https://t.co/fnzD95OoOD
https://t.co/yRMWfZOPtU
Did you ever wonder how mature your machine learning organization is? Do the self assessment now: The IML4E Maturity Assessment Scheme
https://t.co/Gca8JohZ9H #MLOps#IML4E
I was happy to contribute to the discussion on human-centric AI at the Akkodis Industry of the Future Workshop and it is about time to ask how we can create efficient AI solutions in terms of costs, resource consumption and data protection. A wide field f…https://t.co/Q73Ezqj1rj
Exciting week for IML4E: plenary, meetup and review. Many thanks to all participants and contributors. Details see at https://t.co/5rnNoRdZ2H. https://t.co/6c4rKL0RFn
I am happy to announce that the IML4E project () has passed its second review by ITEA today. ITEA was able to confirm that the project is well positioned, has already realized many innovative results and is developing in a successf…https://t.co/suq5am4dRI https://t.co/F4C83CsFh5
Happy that I had the opportunity to speak about continuous quality assurance in MLOps and the IML4E project (https://t.co/F4C83CsFh5) at the 2.nd Helsinki MLOps meetup hosted by Silo in Helsinki. Thanks for the well organized event. https://t.co/sXSBQke8Zh
Organizations struggling with talent shortage face challenges in operationalizing ML at scale. MLOps tools and automation offer solutions to bridge the gap, automate processes, and maintain ML models effectively. #MLOps#AI#TalentShortage
https://t.co/7sCpx4aq4m
Witness the power of #LLM like #GPT, opening doors to countless applications! 🚀@langchain is here to fuel that growth, making development seamless. 🧠💡
🌟 Popular applications:
-Document-based Q&A
-Advanced chatbots
-Intelligent agents
#AI#NLP#LanguageModels
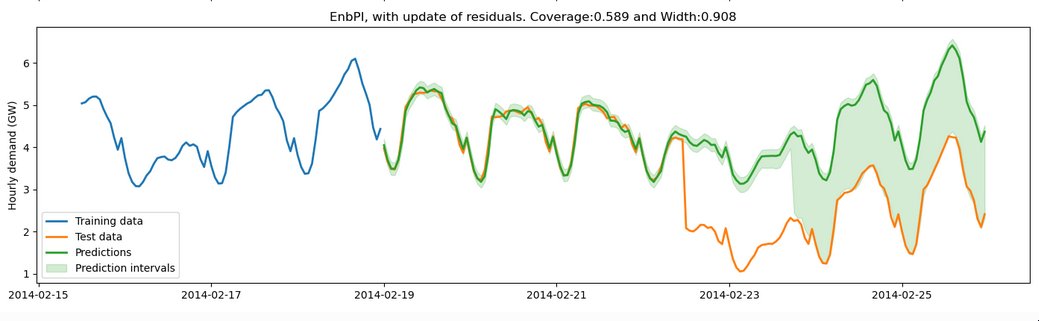
Have you heard of conformal prediction? Its a hot topic used to measure uncertainty in #ML models.
Check out this https://t.co/520pqksBeG for #MLOps tips on monitoring uncertainty and retraining when drift occurs.
Otherwise check this amazing repository https://t.co/AhgTEdzx9W.
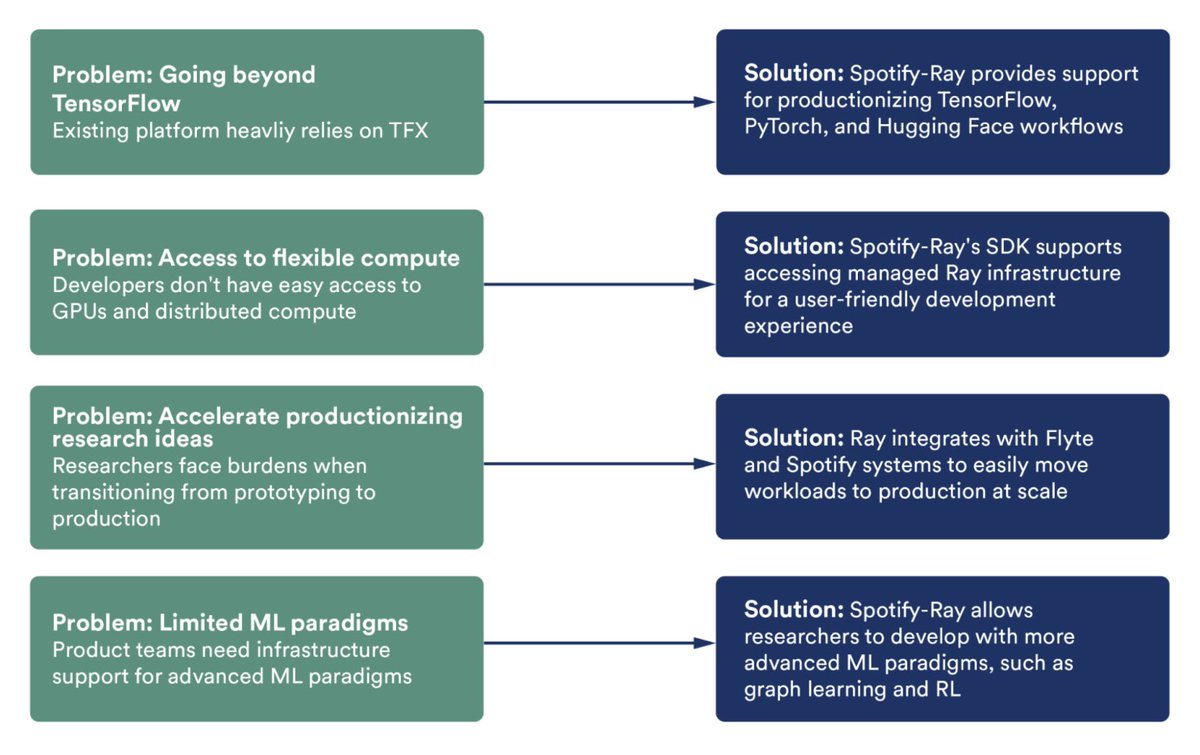
Unlike Ray, which primarily focuses on distributed computing and reinforcement learning, IML4E MLOps OSS platform tackles issues such as flexible data version control, automated data preprocessing for multiple data models, and continuous audit-based certification.
Large Language MLOps (LLMLOps) can be considered as a sub-category of MLOps, which drills into more specific requirements that fine-tuning and deploying these types of models has. Many of the MLOps tools will not bend to fine-tuning and deploying LLMs, such as GPT-3 and BERT.