I have been writing a small series on LLM inference with @vllm_project that can be a practical starting point for people trying to understand this space.
Along with the explanations, I also ran benchmarks on realistic workloads across different GPUs and datasets to evaluate how these techniques perform in practice.
It covers:
- Major speculative decoding techniques
- Major quantization methods
- Distributed inference: DP / PP / TP
- Expert Parallelism and mixed parallel setups
- Practical optimization techniques like prefix caching, KV cache, and disaggregated prefill/decode
My goal was to explain how these techniques work, where they help, so it is easier to choose the right approach for a given workload.
This series is useful not only for people getting into LLM serving, but also for engineers who are already serving LLMs and want to optimize inference, improve throughput, reduce latency, or evaluate the right serving strategy.
I get the hype around GLM 5.2 now. It’s really good.
I’m trying to deploy it across our team for general coding use cases. Will share more details soon, along with suggestions on how to get it running for your own teams in the cheapest and most efficient way possible.
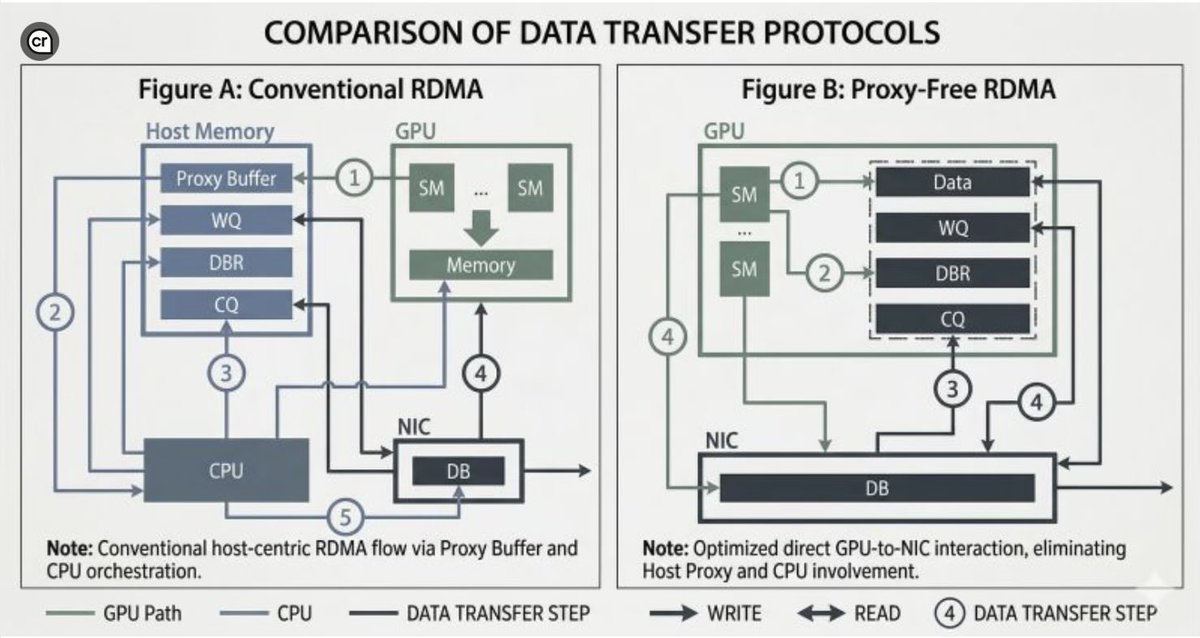
DeepEP : this is the library release by DeepSeek which avoids CPU for MoE communication and do all the work on GPU only. We generally use the NCCL primitives like all-reduce, all-gather for multi gpu MoE Inference.
Implementing Distributed Inference (TP) in tokn. This is how tensor multiplication happens in it for MLP layers. Two major things to be noted:
1. We split W_gate and UP_proj by the column dimension, which is column parallel, and
2. We split Down_proj by the row dimension, which is row parallel.
After this we do all-reduce and sync the output on both GPUs.
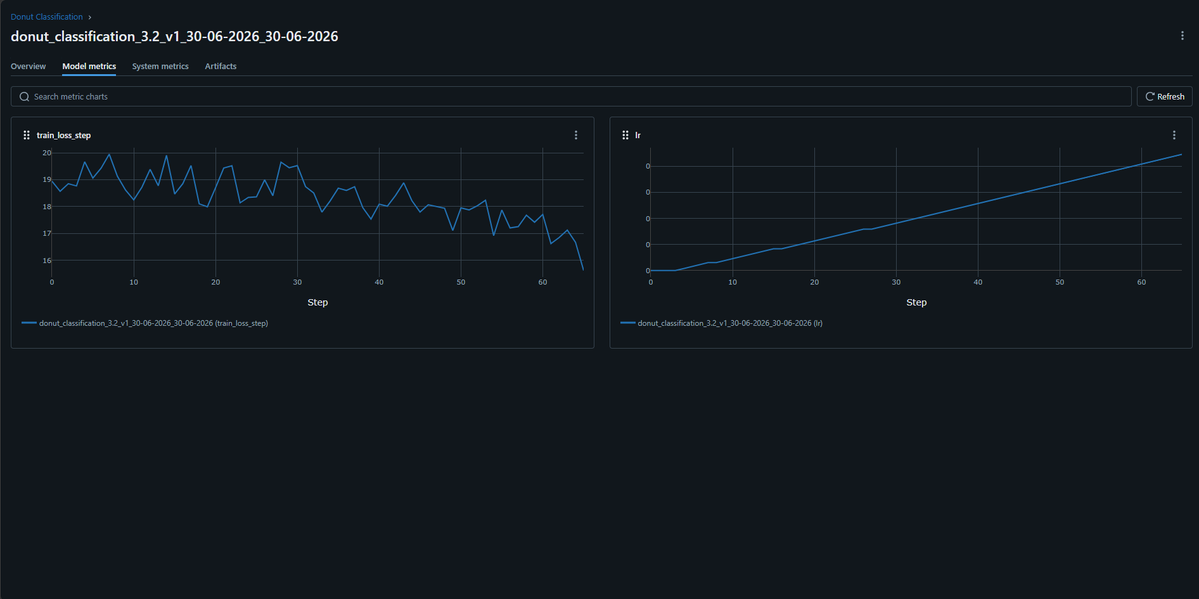
Started 1.41× slower than vLLM.
Added continuous batching -> still behind.
Added torch.compile -> somehow got worse.
Added CUDA graphs -> 452 vs 460 tok/s.
Nearly identical.
kernel launch overhead is the real bottleneck at decode time, not the model. CUDA graphs fix that.
vLLM does not support default flashinfer kernels for Blackwell dtype quantizatized model serving. we can use marlin kernels as fallback.
1. FP8: Selected CutlassFp8BlockScaledMMKernel for CompressedTensorsW8A8Fp8
2. MXFP4: Using MarlinMxFp4LinearKernel for MXFP4 GEMM
3. MXFP8: Using FlashInferCutlassMxfp8LinearKernel for MXFP8 GEMM
4. NVFP4: Using FlashInferCutlassNvFp4LinearKernel for NVFP4 GEMM
CUDA graphs are working now. I did a very minimal implementation with three major things:
1. Initialize buffers for input_ids, positions, etc.
2. Capture CUDA graphs for multiple batch sizes.
3. Condition the forward pass: for prefill use a simple pass and for decode use graph.replay().
Will upload code snippets with explanations soon.
If you want the cheapest GPU for small runs that require flash attention, go for the A30. It is the cheapest among all, and as it is Ampere, it supports flash attention.
Explored what makes Blackwell quantization techniques different from AWQ, GPTQ, etc.
It features:
1. High precision scale encoding
2. Two-level micro-block scaling strategy
2.1 Using FP8 type scaling factor
2.2 Using FP32 type scaling factor
Also, the Blackwell GPU series has FP4 Tensor Cores, which is the reason we can’t use these types of quantization on A100 or H100.
Your GPUs shouldn't get paid to sit idle.
JarvisLabs Serverless is now in beta. Turn any open model into an OpenAI-compatible endpoint with a single command.
A request comes in, a GPU spins up on its own. Traffic stops, it scales back to zero. You're billed for GPU time only while it's serving, never for idle GPUs.
We currently support vLLM, SGLang and Ollama
Live in beta today.