⚡️ Excited to announce Fast3R: 3D reconstruction of 1000+ images in a single forward pass!
Fast3R achieves 251 FPS at its peak. 🔥 Try the demo with your images or video!
🔗 Website: https://t.co/tiXbrXAZen
🎮 Demo: https://t.co/YRfZMKDZ9a
#CVPR2025#3D@AIatMeta
SAM3D received CVPR Best Paper Honorable Mention! 🎉
This was a wildly challenging project - so many frontier techniques (MoT, DPO, shortcut models) and data strategies have to come together to make the system work. Truly honored to be part of this effort. Congrats to the team!
Excited to share that RoboMME has been selected for an oral presentation at ICML 2026! 🎉
Huge thanks to my collaborators and the reviewers for their valuable feedback and support!!
Watch a team of humanoid robots running a full 8-hr shift at human performance levels. This is fully autonomous running Helix-02 https://t.co/IdZR0T1F5I
It is absolutely mind blowing to see how a humanoid comes together in a design review meeting. From choosing the best material for robot shoe soles, to chipping away milli-watts in hands energy consumption, the level of details and care Figure engineers showed is just incredible.
Just leaving Figure’s critical design review for F.04 - the robot is now in full design lock and we're starting to ship parts
F.04 is by far the biggest leap we’ve ever made between robot generations. The level of engineering advances in this system is on a completely different level
At Figure, engineering reviews are extremely rigorous. We start with high-level architecture reviews and work all the way down to detailed reviews on every millimeter, watt, and gram of the robot. We've engineered something really mind blowing and I can't wait to show the world what this team is capable of
One easter egg - the image in the background is from earlier F.04 design reviews :)
🚀 The RoboMME Challenge @ CVPR 2026 is now LIVE!
Timeline:
• May 15 — Policy submission
• June 3 — Winner announcement
🏆 Top 3 teams will be awarded $500/300/200
Let’s push the frontier for memory-augmented robotic manipulation together 💪
🔗https://t.co/79FpVd1ti3
Today we're showing Helix 02 that can tidy a living room fully autonomously
Figure is designed so when you leave the house, your home resets exactly how you like it
Memory is one of the most important topic in AI right now. But memory for robot is very under-explored. A benchmark is a first step to start measuring progress scientifically. Hope to see more work on this line!
Robot memory methods are growing fast, but systematic evaluation is largely lacking. 📉
Introducing RoboMME: a new benchmark for memory-augmented robotic manipulation! 🤖🧠
Featuring 16 tasks across temporal, spatial, object, and procedural memory
🔗 https://t.co/4ELtnhDwrt
In my recent blog post, I argue that "vision" is only well-defined as part of perception-action loops, and that the conventional view of computer vision - mapping imagery to intermediate representations (3D, flow, segmentation...) is about to go away.
https://t.co/aFmE9CHHau
If you do research on spatial intelligence, robotics, or language grounding, join us at CVPR this June! An amazing line up of speakers across vision, robotics, and generative models! Consider submitting your papers to the 2nd 3D-LLM/VLA workshop.
LLMs are now learning space, geometry, and how to move. 🤖📐
The 2nd CVPR 3D-LLM VLA Workshop brings together language, 3D perception, and action for embodied intelligence.
📢 Call for Papers is OPEN: https://t.co/Zff45s3wKT 🌐 Website: https://t.co/BhgA2OnfLQ
If your research lives at the intersection of words, worlds, and robots—this one’s for you.
#CVPR2026 @CVPR
(1/N) Will this be the BERT/GPT moment for 3D vision?
Finally, unsupervised pre-training for 3D works.
Led by @qitao_zhao , we present E-RayZer — a fully self-supervised 3D reconstruction model that:
🔥Matches or surpasses supervised methods like VGGT
👀Learns transferable 3D representations, outperforming CroCo, VideoMAE, and DINO
📈Scales with more unlabeled data
A new recipe for scalable 3D foundation models.
3Dfy anything from a single image!
Very thrilled to announce SAM 3D. From an input image, select any object you want, 3Dfy it!
Blog: https://t.co/wtQLAqXTzW
Demo: https://t.co/tt3YqJlnRB
SAM 3D launched 🚀! 3Dfy anything and everything in an image!
What made it work? tldr: Model-in-the-loop data flywheel for the win!
This was a project I contributed to during my internship at Meta this summer. Incredible team to work and grind with! ❤️ Proud to be part of it!
Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
🛋️ SAM 3D Objects for object and scene reconstruction
🧑🤝🧑 SAM 3D Body for human pose and shape estimation
Both models achieve state-of-the-art performance transforming static 2D images into vivid, accurate reconstructions.
🔗 Learn more: https://t.co/yXcvts8Ogc
Meta just dropped SAM 3D, but more interestingly, they basically cracked the 3D data bottleneck that's been holding the field back for years.
Manually creating or scanning 3D ground truth for the messy real world is basically impossible at scale.
But what if you just have humans rank model outputs? Route the weird edge cases to actual 3D artists to model, loop it back in. Suddenly you can annotate like a million images.
It's basically RLHF for 3D reconstruction. Synthetic data is pretraining, real world ranking is alignment. They borrowed the whole damn playbook and it actually works.
Two models - one for objects/scenes, one for humans. They're already shipping it in FB Marketplace so you can see if that lamp or chair looks good in your room before buying.
Also they're releasing everything - models, code, their human body rig under commercial license. And they built an eval set of actual messy real-world images to help bridge the sim-to-real gap.
The data engine thing is the most interesting though. 3D has been bottlenecked by ground truth forever. If verification scales easier than creation, suddenly the whole game changes.
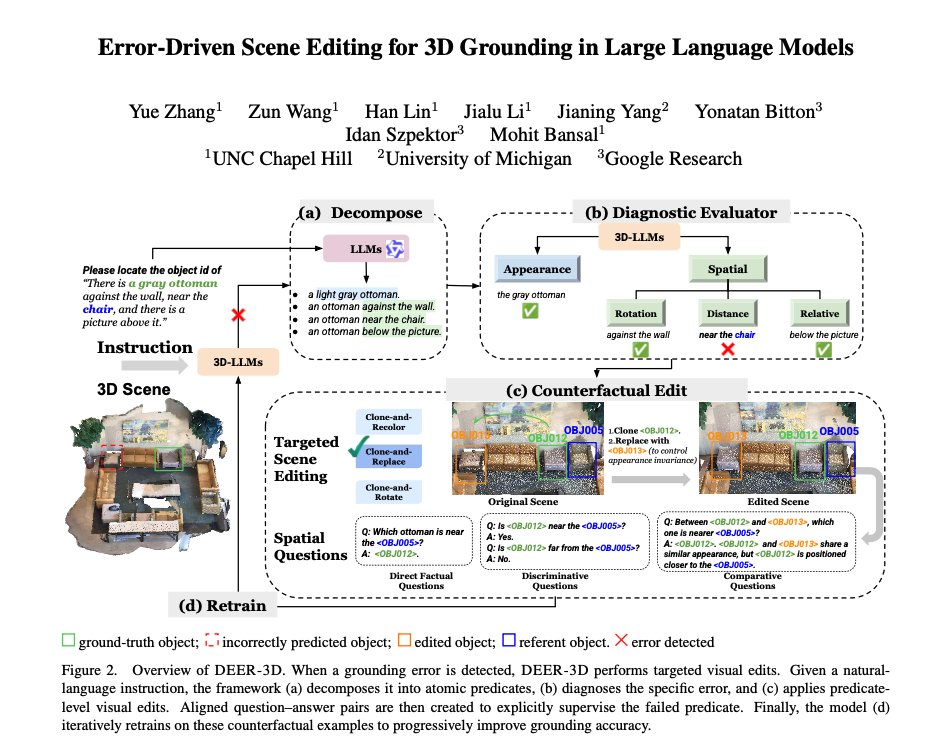
🚨 Thrilled to introduce DEER-3D: Error-Driven Scene Editing for 3D Grounding in Large Language Models
- Introduces an error-driven scene editing framework to improve 3D visual grounding in 3D-LLMs.
- Generates targeted 3D counterfactual edits that directly challenge the model’s biased or incorrect reasoning patterns, e.g. orientation or distance.
- Retrains the model with more informative, bias-breaking 3D evidence, leading to stronger spatial and attribute grounding.
Thread 🧵👇
I joined Figure 4 days ago. Everyday I walk into the office, it feels like walking into a sci-fi movie. Robots work, humans build, machines hum. 3D printers sculpt, CNCs carve, actuators roar—it’s Iron Man’s lab, but real.