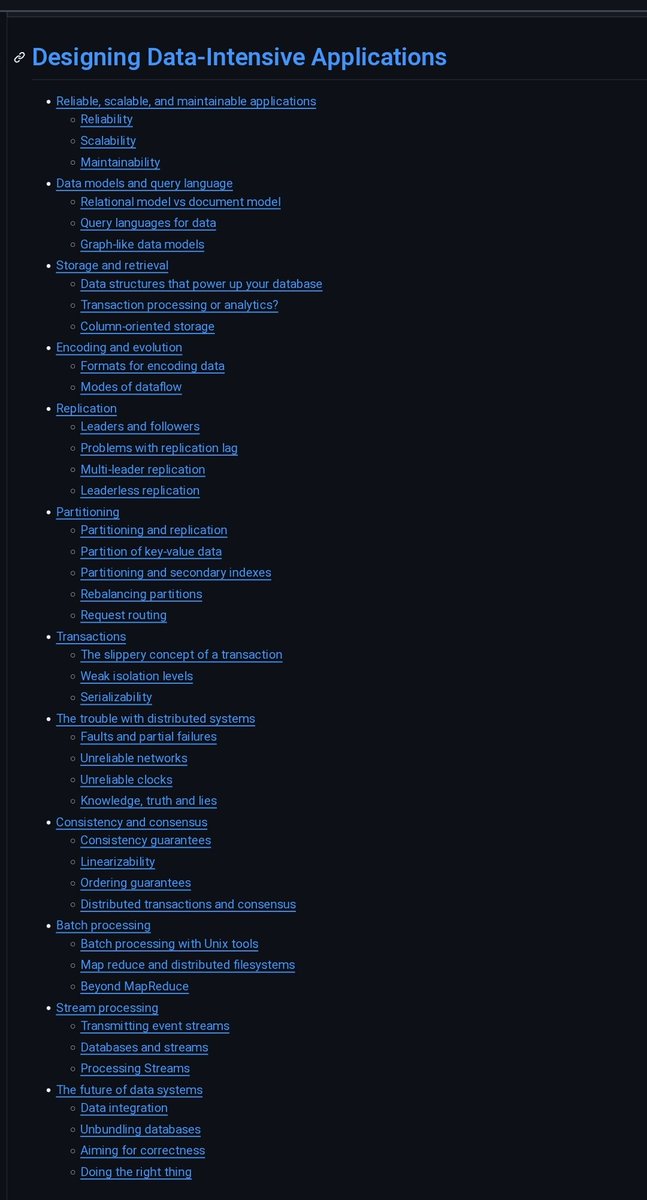
DDIA (Designing Data-Intensive Applications) IS THE BIBLE OF BACKEND ENGINEERING
Martin Kleppmann spent years inside google, linkedin & distributed systems research
then wrote everything down in one book
600 pages of how real systems fail, scale & survive
most people buy it...few finish it
this dev did & turned every chapter into clean github notes
replication & sharding..transactions & consensus...batch vs stream processing...why databases quietly lie to you
the exact knowledge that separates a junior who codes from a senior who architects
one repo no excuses
🔗 https://t.co/9UlMCljPBQ
The only thing which speaks louder than your actions is your intent and it is quite visible in everything you do. If you don’t have the right intent, people eventually notice.
Software engineers don't get paid to write code; they get paid to solve problems.
The faster you realize this, the sooner you'll stop being afraid that AI will replace you and the better your career will be.
You’re debugging a production API and notice something strange.
Your rate limiter says 100 requests per minute, but the logs show 200 requests hitting in a single second. Nothing is technically “wrong”, but the system still gets slammed.
This usually comes down to how the rate limit is implemented. Different algorithms enforce the same rule in very different ways.
Take a simple analogy: a nightclub with a rule — max 10 people per minute.
With a Fixed Window, the bouncer counts entries per minute block. If 10 people enter at 10:00:59 and another 10 at 10:01:00, the system allows it. Technically correct, but you just let 20 people in within a second.
A Sliding Window fixes this by checking the last 60 seconds in real time. It’s more accurate, but requires tracking timestamps for every entry, which becomes expensive at scale.
Then there’s Token Bucket. Tokens refill gradually and each entry consumes one. Small bursts are allowed, but sustained traffic gets throttled.
Finally, Leaky Bucket smooths everything. Requests queue up and are processed at a constant rate.
Good engineers don’t just add rate limits.
They choose the algorithm that matches the system’s traffic patterns.
Self-balancing Binary Search Trees are one of the most important data structures that many of us tend to skip while doing competitive programming. But in real-world stateful systems, they’re extremely useful because they keep data sorted while guaranteeing O(log n) time for insert, delete, and search.
In a normal BST, these operations take O(height) time. If the tree becomes skewed (when height == no. of elements), this can degrade to O(n). Self-balancing BSTs avoid this by automatically rebalancing the tree after insertions or deletions, keeping the height around log n while preserving all BST properties.
Think about this from first principles: how would you design a BST that automatically rebalances itself after insertions and deletions so that the tree always remains balanced?
Some common implementations include:
- AVL Trees
- Red-Black Trees
- B and B+ Trees (although not a binary tree, they are also self-balanced trees that guarantee log n operations)
These data structures power many real-world systems, such as:
- Databases: Index structures (like B/ B+ Trees)
- Language standard libraries: Ex, ordered maps/sets (like TreeMap or std::map ) are implemented using Red-Black Trees.
- Memory management systems: Used to track free/allocated memory blocks efficiently.
- Event scheduling systems: Like operating system schedulers that must always access the next smallest timestamped event efficiently.
These are just a few examples that come to mind right now, but there are many more practical applications of self-balancing trees because this is so powerful that it gives insert, delete, and search, all three in O(logN).
If other data structures optimise one operation, the time complexity of the other operation increases, such as:
- Array: Fast access O(1), slow insert/delete O(n).
- Linked List: Fast insert/delete O(1) at ends, slow search O(n).
- Self-Balancing BST: All operations (search, insert, delete) O(log n), keeps data sorted.
𝗛𝗼𝘄 𝘁��� 𝗗𝗲𝘀𝗶𝗴𝗻 𝗮 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗮𝗰𝗵𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 (𝗥𝗲𝗱𝗶𝘀)
Design a 𝗵𝗶𝗴𝗵𝗹𝘆 𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗹𝗲, 𝗹𝗼𝘄-𝗹𝗮𝘁𝗲𝗻𝗰𝘆 𝗶𝗻-𝗺𝗲𝗺𝗼𝗿𝘆 𝗱𝗮𝘁𝗮 𝘀𝘁𝗼𝗿𝗲 that can scale horizontally across multiple nodes, providing sub-millisecond response times while handling massive concurrent read/write operations and automatic failover .
The system operates on a 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝘄𝗶𝘁𝗵 𝗵𝗮𝘀𝗵 𝘀𝗹𝗼𝘁 𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴. Redis Cluster splits the keyspace into 16,384 hash slots, each assigned to a primary node . When a client requests a key, the system calculates `CRC16(key) mod 16384` to determine the responsible node, enabling automatic request routing and redirection .
The platform's core consists of ���𝗮𝘂𝗹𝘁-𝘁𝗼𝗹𝗲𝗿𝗮𝗻𝘁, 𝗱𝗲𝗰𝗲𝗻𝘁𝗿𝗮𝗹𝗶𝘇𝗲𝗱 𝗰𝗼𝗺𝗽𝗼𝗻𝗲𝗻𝘁𝘀:
. Primary Nodes: Hold data shards and process client requests for assigned hash slots .
. Replica Nodes: Maintain near real-time copies of primary nodes, providing read scalability and automatic failover .
. Cluster Manager: Runs on each node, using gossip protocol to monitor health and coordinate cluster state .
. Proxy Layer: Routes client operations to correct shards, abstracting cluster topology .
Behind the scenes, a 𝗿𝗼𝗯𝘂𝘀𝘁 𝗵𝗶𝗴𝗵-𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗺𝗲𝗰𝗵𝗮𝗻𝗶𝘀𝗺 ensures continuous operation. Nodes exchange periodic PING/PONG heartbeats; if a primary fails, a replica is automatically promoted using quorum-based consensus (requiring >50% nodes online) . Sentinel provides additional monitoring and failover for non-clustered deployments .
This scale demands 𝗮𝗴𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝘁𝗲𝗰𝗵𝗻𝗶𝗾𝘂𝗲𝘀. Multi-key operations require hash tags (`{user:1000}.profile`) to force keys into the same slot . Pipelining batches commands to reduce network round trips, while connection pooling ensures efficient resource reuse .
𝗖𝗿𝗶𝘁𝗶𝗰𝗮���� 𝗗𝗲𝘀𝗶𝗴𝗻 𝗣𝗿𝗶𝗻𝗰𝗶𝗽𝗹𝗲𝘀: 𝟭) 𝗦𝗵𝗮𝗿𝗱𝗲𝗱 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 with 16384 hash slots, ��) 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗲𝗱 𝗙𝗮𝗶𝗹𝗼𝘃𝗲𝗿 via replica promotion, 𝟯) 𝗦𝗵𝗮𝗿𝗲𝗱-𝗡𝗼𝘁𝗵𝗶𝗻𝗴 𝗗𝗲𝘀𝗶𝗴𝗻 eliminating single points of failure, 𝟰) 𝗖𝗹𝘂𝘀𝘁𝗲𝗿 𝗤𝘂𝗼𝗿𝘂𝗺 requiring odd number of nodes (minimum 3) , 𝟱) 𝗧𝘂𝗻𝗮𝗯𝗹𝗲 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 prioritizing availability (AP) over strong consistency .
𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝘁𝗮𝗰𝗸:
. 𝗖𝗼𝗿𝗲 𝗘𝗻𝗴𝗶𝗻𝗲: C/C++ (single-threaded event loop)
. 𝗖𝗹𝘂𝘀𝘁𝗲𝗿𝗶𝗻𝗴: Redis Cluster, Redis Sentinel
. 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴: Consistent hashing, 16384 hash slots
. 𝗗𝗮𝘁𝗮 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝘀: Strings, Hashes, Lists, Sets, Sorted Sets, Bitmaps, HyperLogLog
. 𝗠𝗼𝗱𝘂𝗹𝗮𝗿 𝗖𝗮𝗽𝗮𝗯𝗶𝗹𝗶𝘁��𝗲𝘀: RedisJSON, RediSearch, RedisTimeSeries, RedisAI
. 𝗣𝗲𝗿𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝗲: RDB snapshots, AOF logs
. 𝗢𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝘀: Kubernetes, Docker, redis-trib, Prometheus + Grafana
. 𝗖𝗹𝗼𝘂𝗱 𝗢𝗳𝗳𝗲𝗿𝗶𝗻𝗴𝘀: AWS ElastiCache, Azure Cache for Redis, Google Cloud Memorystore
👉 Learn more in The Modern System Design Handbook: https://t.co/2LauJpfbk4
👉 Grab the Master System Design Case Studies: https://t.co/ujlZXVdc0g
How Java’s Garbage Collector Reclaims Memory
You write Java source code and create objects using the new keyword.
These objects are stored in the Heap memory managed by the Java Virtual Machine (JVM).
As your program runs, some objects become unused when no references point to them anymore.
At runtime:
→ The Garbage Collector (GC) identifies unreachable objects by analyzing reference chains starting from GC Roots (such as stack variables, static fields, and active threads).
→ Objects that are no longer reachable are marked for removal.
→ The GC removes (sweeps) those unused objects to free up heap space.
→ In generational GC, memory is divided into Young Generation and Old Generation, and objects are collected differently based on their lifespan.
→ The JVM may compact memory after collection to reduce fragmentation and improve allocation efficiency.
The result: Java automatically reclaims unused memory, reduces memory leaks, and keeps applications running efficiently without manual memory deallocation.
→ Want to master Java internals and memory management in depth? Check out this ebook:
Java: The Complete Handbook
https://t.co/yZQtybLiEX
Sharding is how you scale databases.
In yesterday's stream we took a detour into when to use sharding and how it works.
Hint: do this instead of using 50 read replicas.
Nobody cares what course you bought.
Build something.
• A Rate Limiter → understand real backend control
• A Job Queue → learn async like a grown engineer
• A Mini Search Engine → indexing > tutorials
• A CLI Budget Tool → edge cases will humble you
• A Feature Flag System → think like a product dev
• A Log Parser → patterns, timestamps, real data
• A Simple Cache Layer → performance mindset
• A Cron Email Script → automation > motivation
This is how you become dangerous.
Not by watching. By shipping.
Bookmark this. Come back in 6 months.
No Experience! No Problem 🚨
Role: Data Entry
Est Salary: $17 - $27 per hour
Location: Remote
- Enter, update, and maintain data
- Verify accuracy of data
Let us know if you are Interested 👇