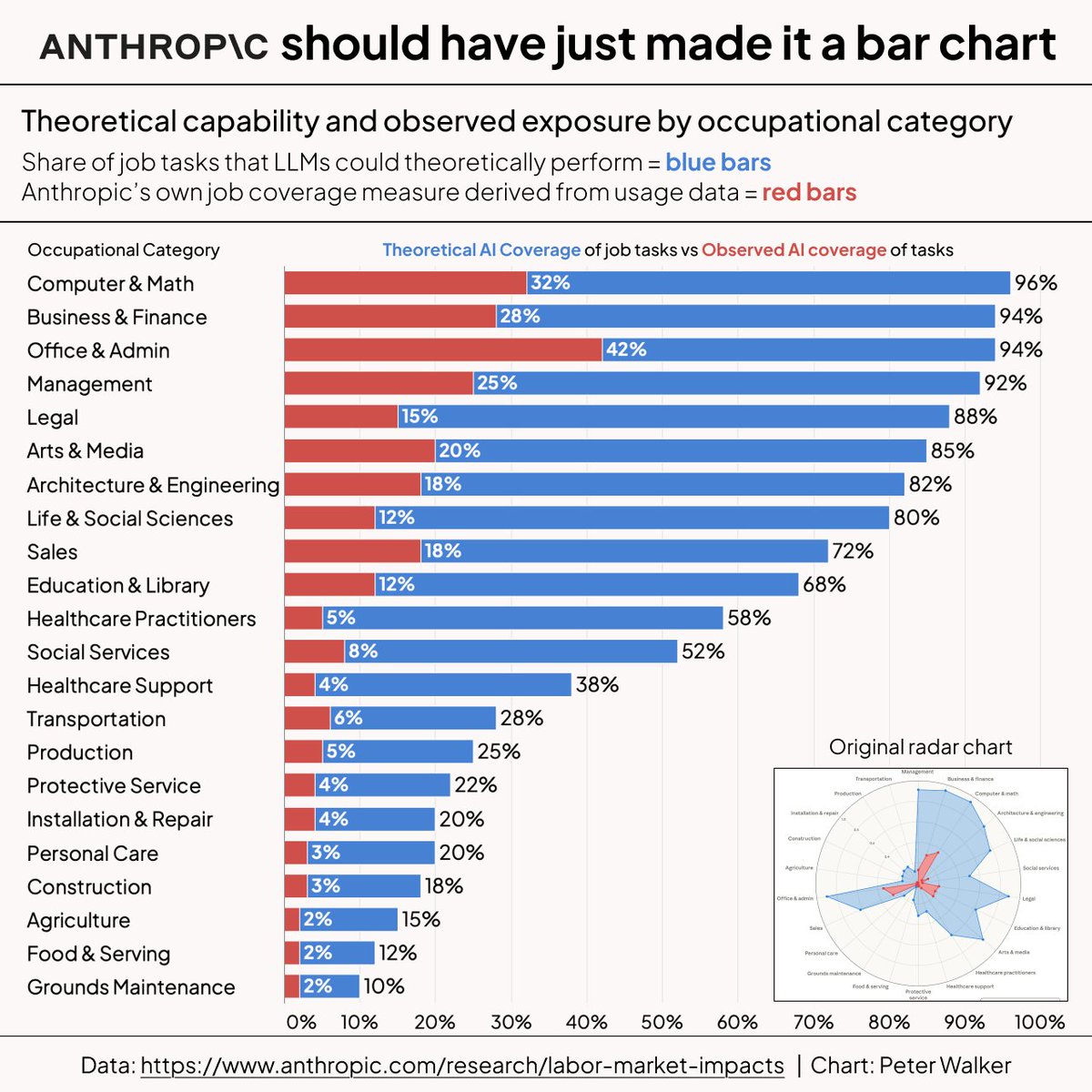
@EricBalchunas Wall Street has been trying to dump these assets on retail for years, similar to what they did with CMBS in the years leading up to 2008. The SEC under Atkins is complicit in this scheme. https://t.co/NzGlaWdcBI
Most law firms are trying to compete on scale.
We're competing on intelligence.
Here's how a 4-person securities boutique built a proprietary LLM that processes client work 60% faster than BigLaw—at 1/5th the cost.
A thread on domain expertise + custom AI 🧵
💯 This is exactly our approach.
Every technical milestone gets paired governance:
Setup MiniMax M2 → Update engagement letters
Review CALM model → Complete ABA compliance review
Deploy to production → Quarterly ethics committee review
We built:
✅ Data Retention Policy
✅ Model Governance Policy
✅ Attorney oversight requirements
✅ Security architecture ($9K)
✅ Zero third-party data access
The "pairing" a commentator describe is what separates sustainable innovation from reckless disruption.
April launch will be defended by governance as much as technology.
Bottom line for legal tech founders:
Generic AI (Claude/GPT-4): Commodity, no moat
Custom semantic routing: $516K annual savings + unbeatable advantage
At 90 clients: ROI = 1,032%
Payback period: 1.2 months
This is how you build sustainable legal AI.
But here's what matters for a 4-person firm:
That $516K in savings = 3 senior attorneys we don't need to hire.
Instead, our team of 4 can serve 90+ clients profitably.
Margin improvement: 55% → 70%
That's the leverage that changes everything.
Legal AI cost breakdown nobody talks about.
We analyzed what it actually costs to serve 90 clients with AI-generated documents.
The numbers shocked us.
Here's the real math 🧵
This paper builds a junior AI scientist that starts from a real baseline paper and code to propose, test, and write improvements.
reads the baseline paper and repo, lists concrete limits, checks novelty, and picks one idea to pursue.
Runs experiments in 3 stages, first implement the idea, second keep improving until it beats the baseline, third run ablations to see which parts actually matter.
Uses a coding agent that can edit multi file projects, run scripts, and debug based on error logs.
Then writes the paper in steps, method first, outline next, full draft after, plus multiple rounds of feedback and cleanup.
It was judged by automated reviewers, audited by the authors, and also submitted to an AI reviewers venue.
Its papers scored higher than other agent systems, around 5.75 versus 3 to 4 on typical baselines.
Also showed clear risks, like fabricated ablations after feedback, shaky citations, code tweaks that inflate metrics, and reviewers that cannot verify text against results.
----
Paper – arxiv. org/abs/2511.04583
Paper Title: "Jr. AI Scientist and Its Risk Report: Autonomous Scientific Exploration from a Baseline Paper"
Most AI training uses single metrics. We use three: 30% rule-based format compliance, 40% SLM-as-judge quality scoring, 30% attorney ground truth validation. Each catches what the others miss—format checks structure, SLM evaluates reasoning, attorneys verify legal accuracy.
For legal AI:
- Format compliance ensures citations, headers, and structure match court requirements
- Attorney validation encodes 15+ years of practice intuition into numerical rewards
You can't reverse-engineer expertise that has been converted into reward signals.
#LegalTech #AI
Founder's Journey: This week, the team built dozens of Claude projects and prompt templates for legal tasks.
Most founders would stop there.
We're doing something different: Every prompt becomes training data for our custom SLM in 2026. Every template becomes a trajectory. Every client interaction refines the reward function.
Infrastructure first. Then the moat builds itself.
Legal tech's dirty secret: Most "AI-powered" legal platforms are just:
- ChatGPT or Claude API wrapper
- Nice UI
- $200/month subscription
Zero competitive moat. Easily replicated.
We're building something different: Hundreds of prompt templates that become proprietary training data.
That's a moat competitors can't buy.
Just committed to 3 major conferences for 2026:
ABA TechShow (legal tech)
NVIDIA GTC (AI infrastructure)
Consensus (Web3)
Also: Designed user journey for our startup legal hub.
Building legal AI requires both deep technical chops AND understanding what lawyers actually need.
Most founders pick one. We're doing both.
💼 AI seems to be affecting legal staff hiring.
41% of bosses say AI already enables staff cuts.
Clifford Chance, a leading law firm cuts London, is cutting 10% of London business services, about 50 jobs, because of heavier use of AI and more work moving to lower cost hubs.
PwC’s global chair said their plan to hire 100,000 people in 5 years is no longer realistic and that entry-level hiring will likely shrink.
Both firms point to AI taking over routine tasks like document review, research, scheduling, and basic reporting.
A recent survey of 850 leaders shows 41% are already cutting staff because of AI and 31% now check AI tools before hiring a new person.
Legal and consulting teams are shifting junior tasks to AI, keeping humans for exceptions, risk checks, and client judgment.
Graduate roles are moving toward AI engineering, data handling, retrieval work, and verification-heavy tasks.
---
theguardian. com/technology/2025/nov/21/increased-ai-use-law-firm-clifford-chance-cuts-london-jobs-10-per-cent
Two weeks ago: "We'll just use Claude to leveraging existing LLMs while we develop our query library and SLM"
Yesterday: Spent 8 hours debugging PyTorch + RTX 5090 compatibility
Today: Running three production-quality AI models locally with ~99% cost savings
The shift: Realized that in legal services, the right architecture beats the biggest model.
Build the infrastructure now. Thank yourself later.
🧵 What I learned building local legal AI this week:
1/ Started with the "obvious" approach: Run the biggest open-source model available.
Reality check: Needed 900GB+ of disk space and 460GB+ of VRAM.
My RTX 5090: 32GB VRAM.
Back to the drawing board.
2/ Key insight: Model architecture matters more than parameter count.
A well-architected 32B model can match or beat a poorly-deployed 200B+ model for domain-specific tasks.
Size is marketing. Architecture is engineering.
3/ The debugging journey:
- PyTorch stable: ❌
- PyTorch nightly cu124: ❌
- PyTorch nightly cu126: ❌
- PyTorch nightly cu128: ✅
New hardware needs bleeding-edge software. Plan accordingly.
4/ End result: Three models running locally
Simple queries: Instant
Document drafting: Fast
Complex legal reasoning: Shows its work
All fitting in 32GB VRAM. All production-quality.
5/ The real win isn't cost savings (though ~99% reduction helps).
It's this: Every query that runs locally is data that stays local.
For legal work, that matters.
6/ Lesson for builders:
Don't chase the biggest model.
Chase the right architecture.
The firms that figure this out first will have an unfair advantage for years.
That's the whole thread. Happy building.
RTX 5090 local AI insight:
Model size ≠ active parameters for MoE models.
A "10B active" model still needs 230GB+ in memory.
For legal AI on consumer hardware:
- Quantized 32B models fit in 32GB VRAM
- Quality is production-ready
- Speed is excellent
Right-size your stack.
#LegalTech #AI