Container shipping rates are surging amid the Iran War:
The spot rate for a 40-foot container from Asia to the US West Coast jumped +$655, or +20%, over the last week, to ~$3,933, the highest in at least 6 months.
At the same time, the rate from Asia to Northern Europe jumped +$793, or +27%, to ~$3,649.
Since the start of the Iran War, Asia-to-US container rates have surged +109%, and Asia-to-Europe rates are up by more than +50%.
This comes as shipments rerouted around the blocked Strait of Hormuz are causing severe congestion at Southeast Asian transshipment hubs, including Singapore and Malaysia.
On top of this, carriers are charging importers fuel surcharges and shifting costs, while a pickup in demand heading into peak season for booking ocean freight is adding further pressure.
Looking ahead, available shipping capacity is set to shrink further as importers rush to replenish inventories in July and August, which could push rates even higher.
Supply chain pressures are intensifying.
Refining Capacity Is Strategic Power🛢️🏭
Crude oil only matters if you can turn it into usable products.
That is why refineries are so important.
-Gasoline
-Diesel
-Jet fuel
-LPG
-Naphtha
-Petrochemicals
The world’s largest refineries are not just industrial assets.
They are strategic chokepoints in the energy system.
India, South Korea, the US, Nigeria, Singapore, Saudi Arabia, and Venezuela all show the same thing:
Energy security is also about having the capacity to process it.
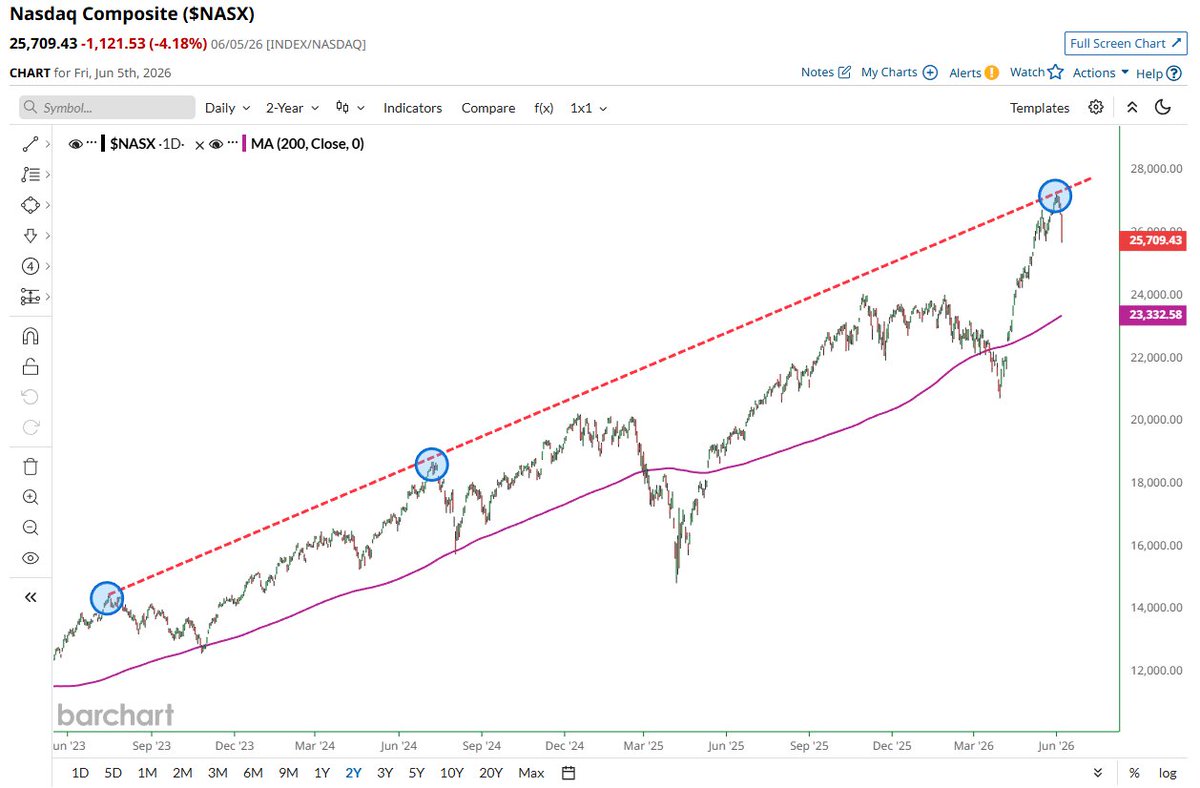
Nasdaq with a textbook rejection off the 3-year trendline 🚨🚨 Each of the prior rejections led to an eventual drop all the way down to the 200-day moving average 📉📉
Our first model Mac-1 6.6B beating 3 giant models.
- Haiku 4.5
- GPT 5.4 mini
- Gemini 3 flash
Running this model on my Macbook M3 24GB. (model takes only 7GB RAM)
It searches web, call tools, ask follow-ups, tell jokes, find contacts, search files, write emails, book events, write notes, set reminders and so much Siri can't do.
Read again, a 6.6B model.
Will share full 2000+ scenario test results & benchmark scores in 2 days.
Run Gemma 4 26B MoE on 8GB VRAM with 250k context at 20+ tokens/sec
If you own any 8GB VRAM graphics card, stop what you are doing. Local AI just had its absolute "Holy Shit" moment for budget hardware.
Yesterday, I benchmarked Unsloth Gemma 4 12B Q4_K_XL on an 8GB card.
The community went wild but immediately demanded more: "Can we run a 25B+ model on budget GPUs?"
Today, I’m delivering exactly that.
I am running a massive 26B parameter Mixture of Experts (MoE) model locally on a standard 8GB VRAM setup with 250k full native context!.
If you own an RTX 3060, 3070, 4060, or any budget GPU with 8GB of VRAM, the local AI paradigm has completely changed.
The performance metrics are astonishing:
- 20 tokens/sec flat decode throughput.
- Stable, flat decode speed even with massive prompts.
- I threw a 60k token prompt at it, and it still clocked in at 20 TPS without dropping a single frame.
# What about prefill?
Yes, Time To First Token (TTFT) is slightly high when swallowing massive contexts. But with a solid 200 tokens/sec prefill speed, the wait is barely noticeable and highly usable.
And this is running completely without Multi Token Prediction (MTP) active.
How is this possible? It’s the magic of Google's new QAT (Quantization Aware Training) quants for Gemma 4.
The model weight file (unsloth gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf) is only 13.2 GB, making it the ultimate local powerhouse.
# The Test Setup:
CPU: Intel Core i7
RAM: 16GB System RAM
GPU: NVIDIA GeForce RTX 4060 Laptop GPU (8GB VRAM)
# The Secret Sauce (The -cmoe Flag)
To make this work properly on any 8GB card, you must use the -cmoe (CPU MoE) flag in llama.cpp.
This flag isolates the heavy MoE expert weights directly to system memory (CPU/RAM) while letting your GPU focus strictly on the Attention layers and the KV Cache.
It prevents VRAM spillage and holds the throughput rock solid.
# The flags:
-m "gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf" -cmoe -c 248000 -v
Once running, just open the UI on localhost and toggle the new reasoning lightbulb icon in the text input box to watch the model perform multi step thinking.
Are you still running smaller models, or are you ready to scale up your budget local setups? Let's discuss in the replies
A nice slide summarising Europe's scale up problem.
In China’s state-directed, policy-accelerated model, strong talent, capital, and supply chain, drive high conversion rates, 37% post-Series A.
In the US market-led, direct hyperscalar demand from big tech enable fast iteration and 24% conversion.
And in Europe’s research-led, missing blocks in capital and supply chain combined with lack of local customers results in slow iteration and only 6% conversion.
NVIDIA just dropped Nemotron-3.5-ASR: one 0.6B model, 40+ languages, streaming.
parakeet.cpp already runs it. On a plain CPU, 2.5x faster than @NVIDIAAI 's Nemo runtime, output byte-for-byte identical (WER 0).
No GPU needed. Offline or real-time. Pick a language with --lang, or auto.
GPU numbers are coming to compare with Nemo framework.
🚨 ANTHROPIC JUST PUBLISHED A 36-PAGE SECURITY GUIDE THAT BASICALLY TELLS YOU TO STOP TRUSTING YOUR OWN AI AGENTS.
If you run agents on Claude Code, MCP servers, or automation tools, pay attention.
The attack timeline has collapsed.
AI models compress the gap between a vulnerability and a working exploit from months to hours, for mere dollars.
Agents introduce new autonomous risks, from tool poisoning to context memory manipulation.
The most useful idea in the guide is Anthropic's new security test:
Does a control make an attack impossible, or just tedious?
Automated attackers have unlimited patience. They will grind straight through friction like rate limits and 2FA. To defend at the speed of AI, you need hard barriers and automated defensive operations.
Here is how Anthropic says you should lock down agents:
→ Treat static API keys as compromised. Use short-lived tokens that expire in minutes.
→ Apply "Least Agency": explicitly limit what each tool can DO.
→ Sandbox agents that process untrusted inputs like emails and web pages.
→ Scope permissions dynamically per task, not permanently.
I've added the link to the guide in the 🧵↓
Qwen3.6-27B Q8 seems to be the winner, but just barely a head of gemma-4-31B-it Q4, with gemma taking less than half the time to complete the benchmarks.
If there are better benchmarks to use for coding/agent/tool calls let me know and I'll add them!
THIS MIGHT BE THE MOST INSANE THING IN CRYPTO RIGHT NOW.
MMs have literally wiped out every long in existence here.
There are $25 BILLION in shorts sitting right now vs. only $940 MILLION in longs.
Such imbalance is very rare, and this shows the level of manipulation going on in crypto.
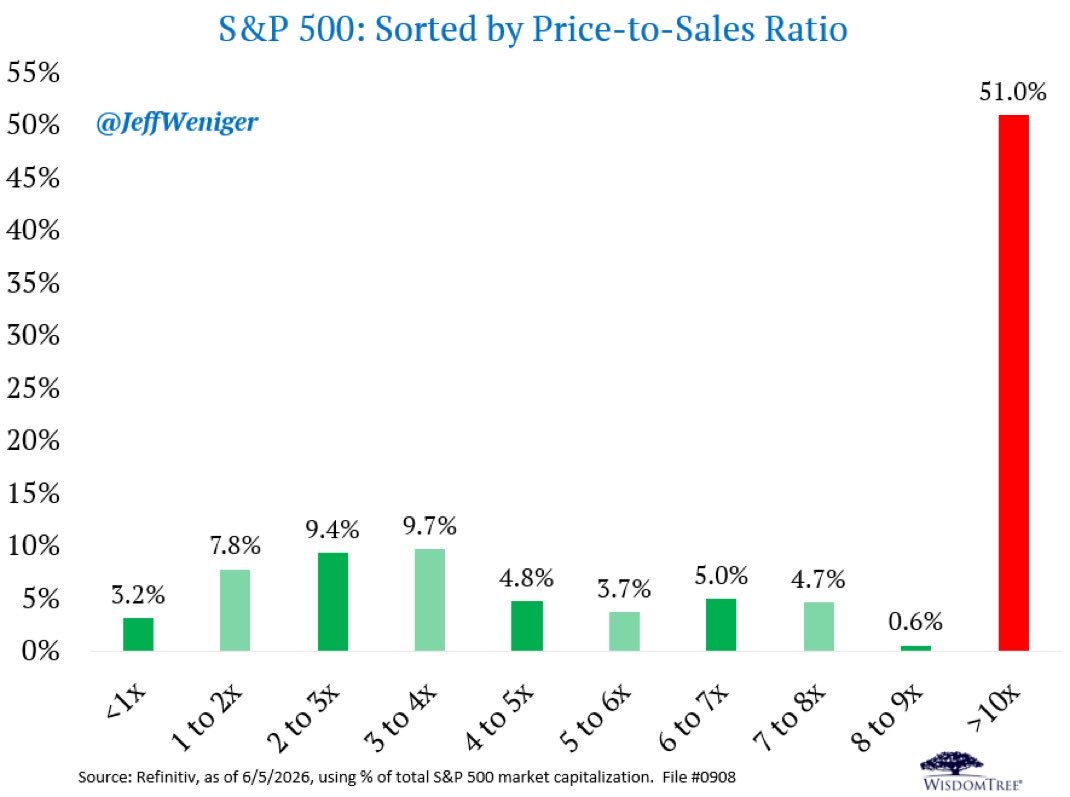
51% of the S&P 500's market cap is in stocks trading above 10x sales.
Half the index.
In 2002, after Sun Microsystems crashed 90%, CEO Scott McNealy famously said this about his own stock at 10x sales:
"At 10x revenues, to give you a 10-year payback, I have to pay you 100% of revenues for 10 straight years in dividends. Zero costs. Zero R&D. Zero taxes. Zero employees. What were you thinking?"
He was explaining why investors had been insane to pay it.
Today, half the S&P 500 trades there.
Different decade. Same math.
🚨RETAIL HAS VANISHED FROM THE CRYPTO MARKET
CEX spot volume collapsed to $679 billion, the lowest level since October 2023, as per CryptoQuant.
Spot trading is now down 46% YoY, a staggering -67% drawdown from its October 2025 peak.
Major exchanges are rushing to pivot to gold, silver, oil, stocks, where the monthly volume has already exploded beyond $450 billion.
Introducing our new agentic RAG framework. A collab with Google Cloud, our multi-agent workflow goes beyond standard RAG by breaking down complex enterprise queries & iteratively searching for sufficient context before generating dependable responses.
📜→https://t.co/A8l499bLrj
What just happened?
The S&P 500 just erased nearly -$2 TRILLION of market cap just hours after 3rd strongest US jobs report in 18 months.
Meanwhile, Bitcoin is officially down over -50% from its record high in October 2025.
What's happening? Let us explain.
(a thread)
Adding even more fuel to the fire is the drawdown in crypto, with Bitcoin now down -53% since October.
In fact, Bitcoin is down 20% this week ALONE, with crypto erasing ~$2.5 trillion since October 2025.
The bear market gained momentum this week and crushed risk appetite.
🚨A COMPLETE MASSACRE UNFOLDED IN LEVERAGED SOUTH KOREAN ETFS AS THE AI BUBBLE BEGAN TO DEFLATE:
The 3x long leveraged South Korea ETF, $KORU, listed in the US, dropped -42% in just one session.
$KORU has now more than HALVED in price in just 3 trading sessions.
Monday’s session in South Korea is setting up to be epic.
Many retail and institutional investors never learn from their mistakes and continue to rush into hyped themes.
What is even worse is their use of leverage.
Warnings were clear and everywhere.