LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. https://t.co/r2uuX0lBCu
As Nick says, we’re excited about the potential for leveraging cognitive science to improve user simulators, then use them to evaluate and train models that collaborate better with real humans.
I'm hiring (including but not limited to postdocs), let me know if interested in this direction!
Why does deep learning generalize? What does weight decay really do? Can algorithmic information theory address these questions?
In my latest preprint, I give a proof that the minimum neural weight norm matches the minimum program length (aka Kolmogorov Complexity), up to a logarithmic factor. In other words, the neural network with the smallest possible weight norm (that fits the data) must encode the shortest program (that fits the data).
The result only holds for fixed-precision neural nets: infinite precision nets can store infinite information with finite (small) weights.
https://t.co/eMZIGQDf2f
Language Models Need Sleep
"Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache."
"increasing sleep duration N for our models improves performance, with the largest gains on examples that require deeper reasoning."
🧵 9/ This work couldn’t have been possible without my amazingly supportive advisors @StefanoErmon and @Xiaojie_Qiu.
Check out our paper and code for more details:
📄https://t.co/Jq0G2ySc58
💻https://t.co/B4vL9oQ3DC
Looking forward to your thoughts!
I am fascinated by the parallels between diffusion models and associative memories. In our new paper we demonstrate that discrete language diffusion models form basins of attraction around test samples — examples never seen during training. As training data grows, basins around training samples shrink, while basins around unseen test samples expand. This is strikingly similar to what happens in Dense Associative Memory models above the critical memory load.
Now in PRE: "Transient dynamics of associative memory models."
I argue that the "blackout catastrophe" (the famous α≈0.14 transition) is not catastrophic when viewed from an out-of-equilibrium, dynamical perspective.
Journal: https://t.co/F4QCHCWYMF
PDF: https://t.co/X0eQyKAhTo
My first blog post in over a year is a deep dive on flow maps🗺️, or how to learn the integral of a diffusion model to enable faster sampling and several other cool tricks.
It's the longest one yet👀 Let me know what you think!
https://t.co/O8bBGZ9qjC
Our paper "Autoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction" was accepted for publication at #ICML2026 https://t.co/DUTSj4Sz7u
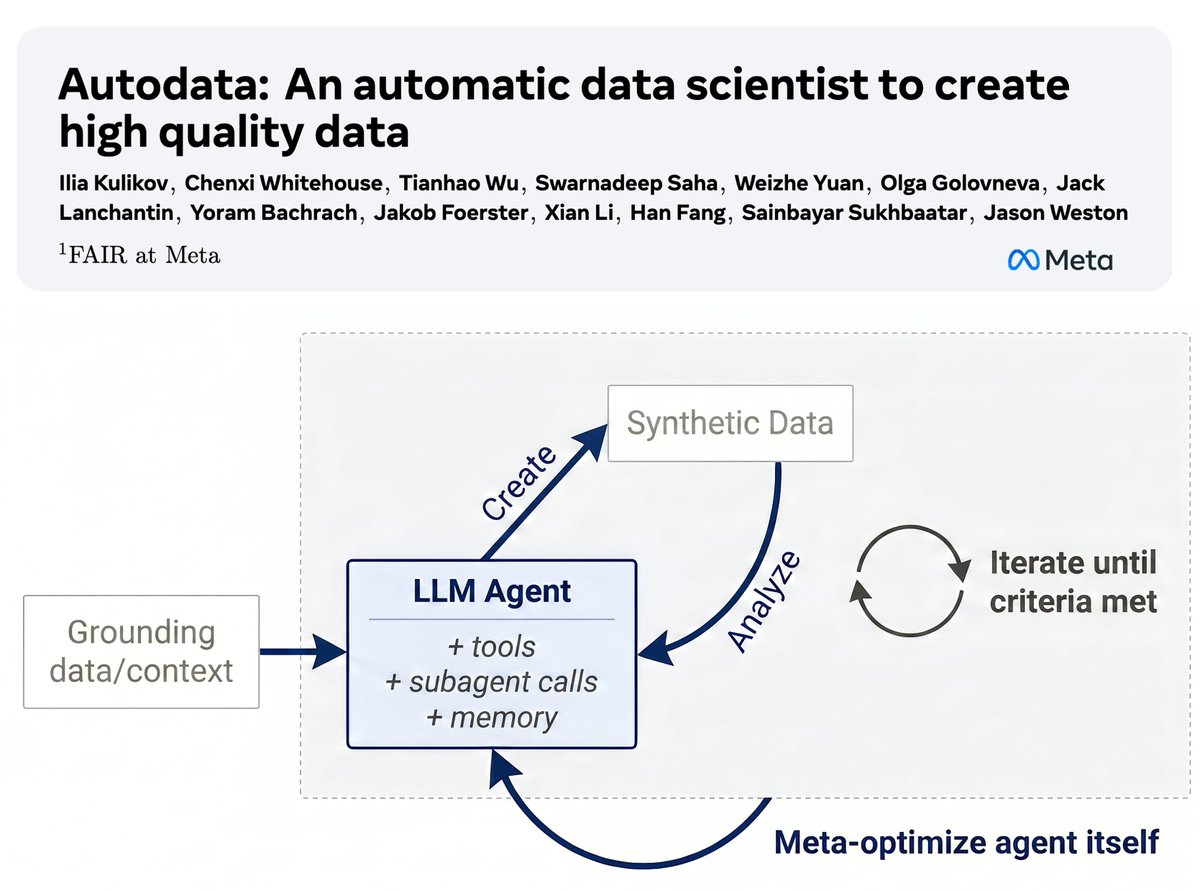
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: https://t.co/vjPvnTYfJx
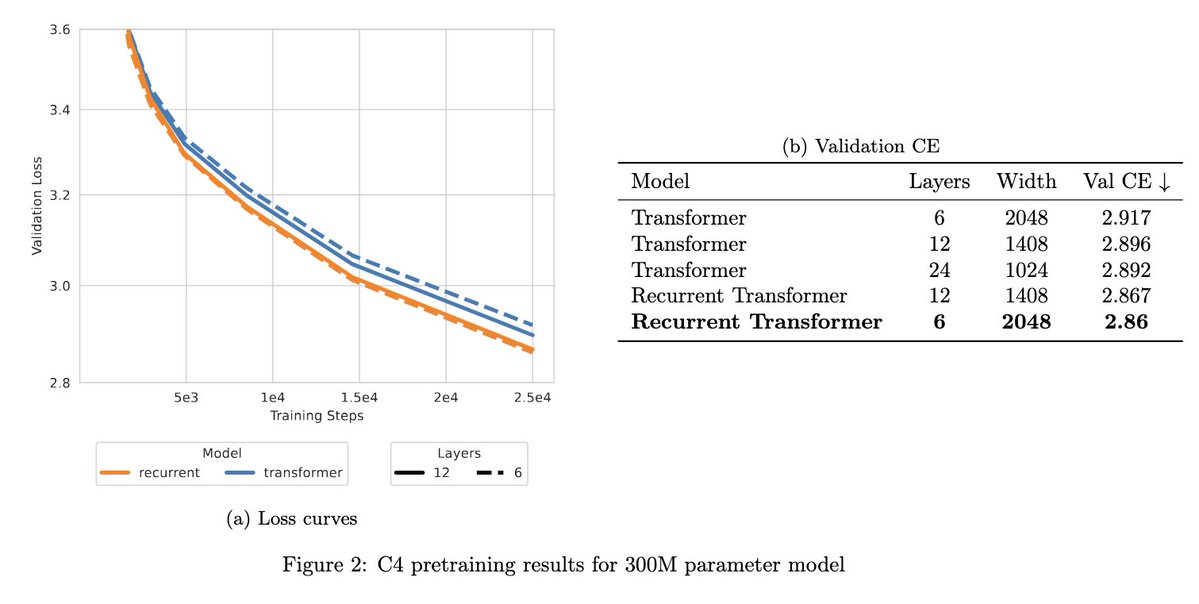
1/8 Introducing Recurrent Transformer (RT). At 300M params, RT improves validation CE over standard Transformers. The best RT model is only 6 layers, but wider at 2048 — beating deeper 12- and 24-layer Transformers by trading depth for width.
Along with Categorical Flow Maps and Flow Map Language Models, we now have three separate papers heralding the triumphant return of continuous methods for language diffusion😶🌫️
Can you tell I'm excited?🫨
https://t.co/SKS4OFtSG8
https://t.co/kJ3cuFsggd
https://t.co/aXXU4bUSMT
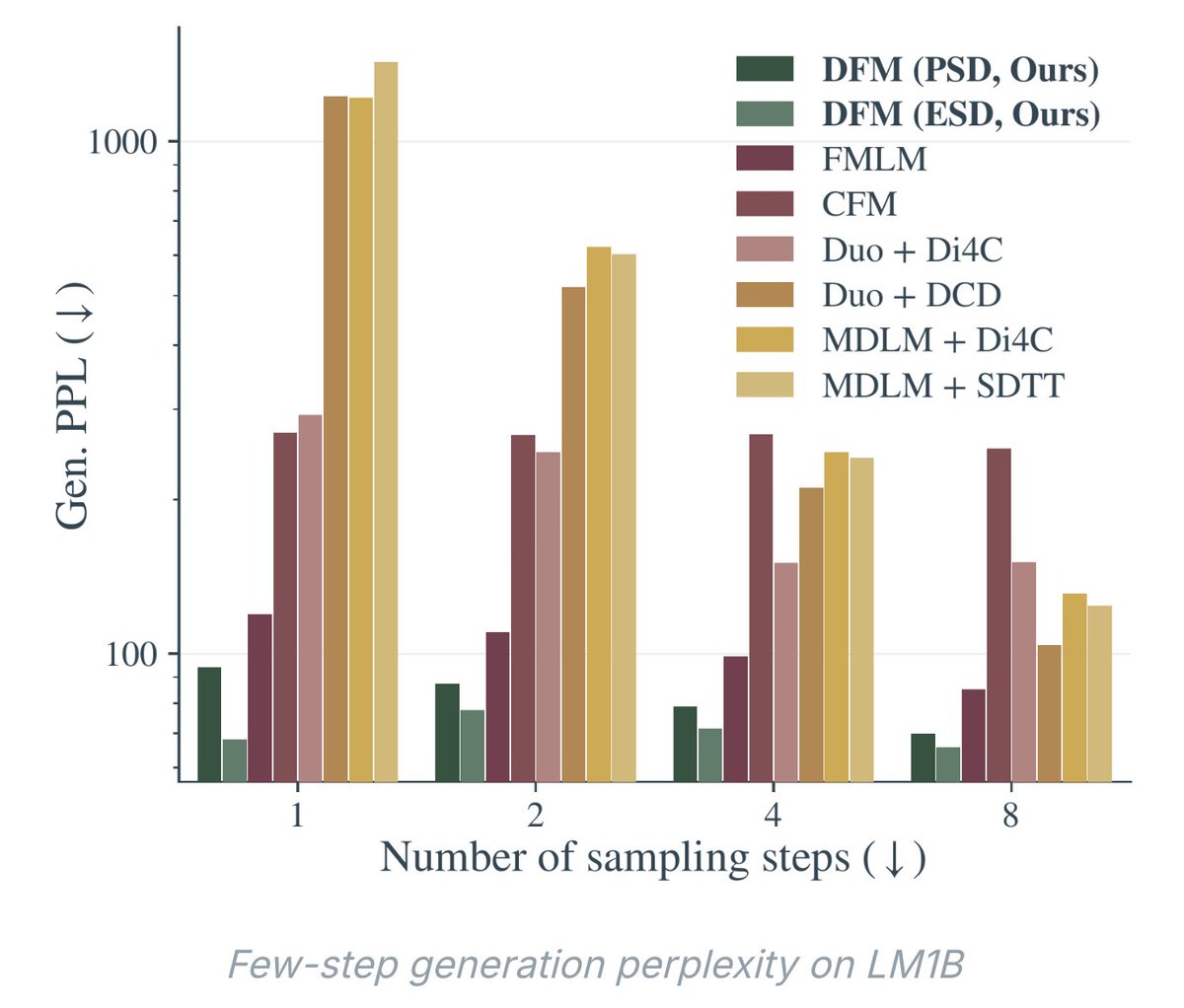
New paper! Presenting Discrete Flow Maps:
paper: https://t.co/f1RmZry2by
blog: https://t.co/Cnwgf4moY0
A laughable problem for me these days is that @nmboffi and I share a research brain, and we have had, time and again, a conversation that ends with “ha so I guess we’re writing the same paper.” Soon we will return to just doing it together :). Here we are doing it again with discrete flow maps and flow language models! A complete and thorough paper led by @PPotaptchik@json_yim@adhisarav@peholderrieth. We took a bit of time to post it to ensure we understood a few more things about the stability of the loss functions.
Like @osclsd , @FEijkelboom, and @nmboffi , we think this could be a very helpful paradigm for thinking about fast inference and even better alignment!
Here’s our version of the story, and I hope it makes clear how green field this research direction is — we provide a comprehensive picture of the KL losses you can write from the properties of the flow map, some nice geometric proofs about the mean denoiser and the simplex, and find that at this time, the ESD can actually be the most performant, with some caveats. Excited for everyone to work together and push this class of models to their limit!
Looped transformer and Energy-based Models (EBMs) are closely related:
•EBM inference: x ← x − η∇E(x)
•Looped transformer: x ← x + block(x) (residual form)
These are literally the same algorithm if block(x) = −η∇E(x) for some scalar E.
This equivalence isn’t automatic — a generic transformer block is not the gradient of any scalar (its Jacobian isn’t symmetric, and gradients must have symmetric Hessians). Dmitry provided a solution to this.
I like the perspective to understand/build the looped transformer as an EBM inference process by gradient descent. The looping isn’t just reusing weights for efficiency — it’s the optimization procedure of the EBM itself.
ELT: Elastic Looped Transformers for Visual Generation
"We introduce Elastic Looped Transformers (ELT), a highly parameter-efficient class of visual generative models based on a recurrent transformer architecture. While conventional generative models rely on deep stacks of unique transformer layers, our approach employs iterative, weight-shared transformer blocks to drastically reduce parameter counts while maintaining high synthesis quality."
basically: anthropic sneakily turned down how hard claude thinks before editing code, changed the default from "high" to "medium" effort, and hid the reasoning from session logs. all without telling users.
an amd director had 7k sessions of telemetry to prove the degradation was real and measurable (not just vibes). anthropic admitted to the changes. there's a workaround (use "/effort max"). the uncomfortable part is most users had no data to notice it happened at all.
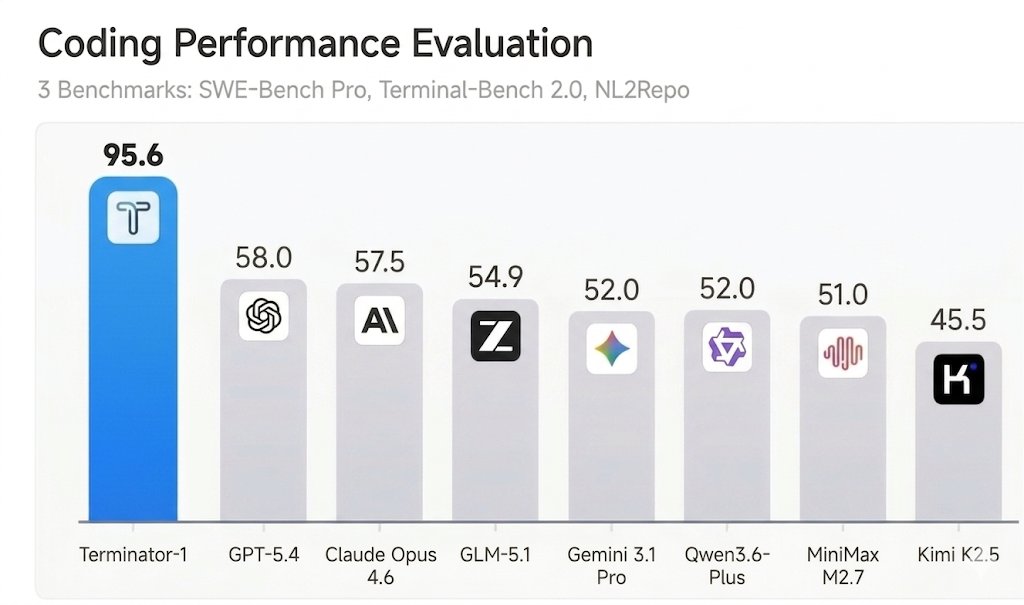
An agent that beats Claude Mythos on Terminal Bench and SWE-bench Verified?
🎉We are excited to share Terminator-1, our newest agent that achieved 95+% on SWE-bench Verified and Terminal-Bench with @MogicianTony!
We show that besides model capabilities, well-designed harness could actually boost the accuracy by 3x in coding tasks.
Well if you really wanted you could get 100% accuracy without solving a single task.
The actual finding is that most AI benchmarks can be easily reward-hacked with simple exploits. Read more about the same 7 design flaws that almost every evaluation has ⬇️