We are extremely overwhelmed and honored to receive the IEEE Signal Processing Society Best Paper Award (2025) for our paper "Pre-Training with Whole Word Masking for Chinese BERT", published in IEEE/ACM TASLP (2021). 🎉🎉🎉 @IEEEsps#IEEE https://t.co/ZLY4d8RFAG
Sharing my ARR SAC tool (based on my old jupyter notebook). You can load OpenReview venue, inspect paper status, read comments, score distributions, and export commitment-stage papers to Excel for ranking. Runs on your own machine. https://t.co/uF3XDiI8jZ #nlproc#ARR#emnlp2026
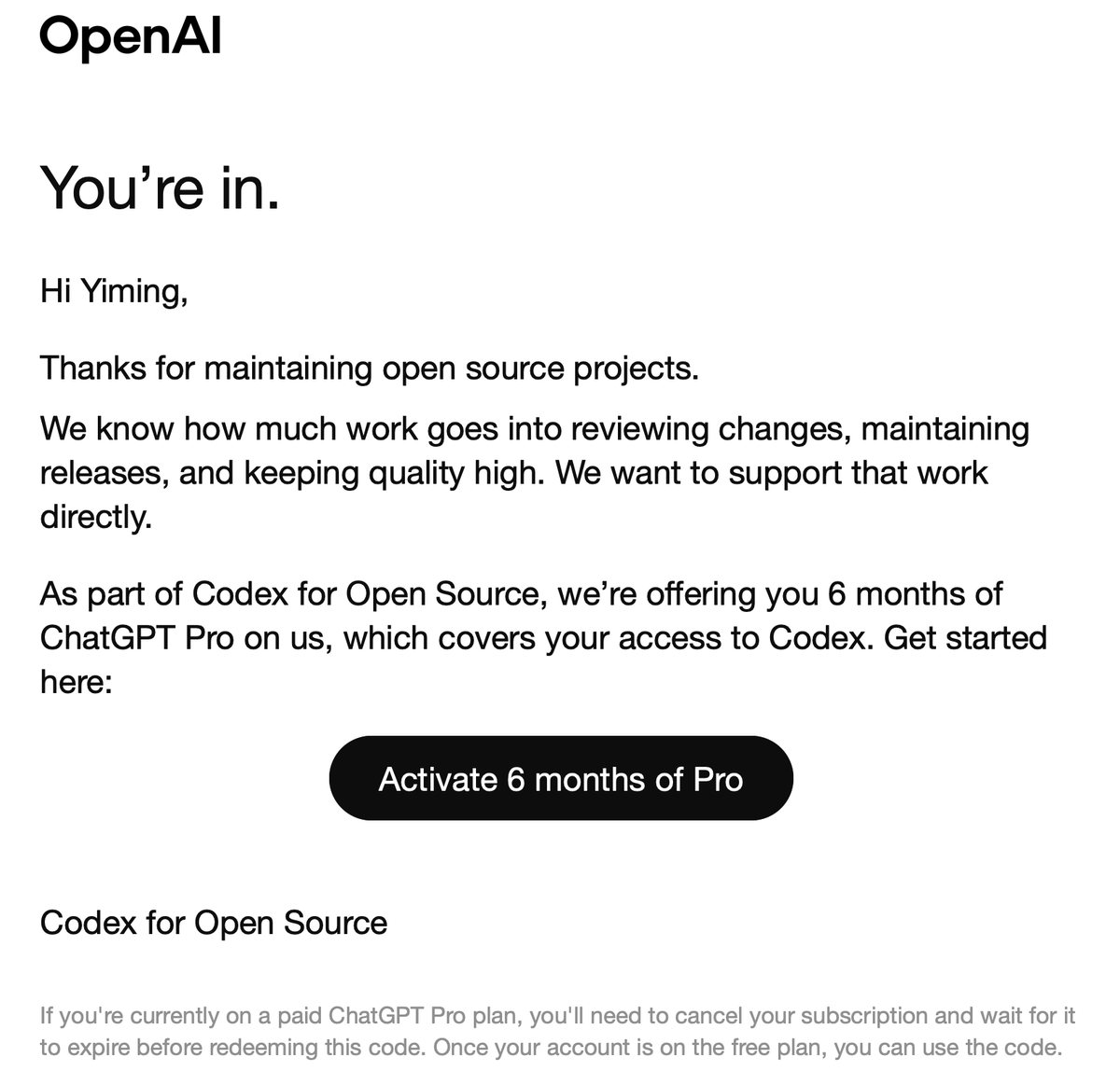
Good News: I am enrolled in #Codex for Open Source. 🎉
Bad News: I cannot redeem this untill my Plus subscription ends. What even worse, I am on an annual subscription, ends 6 months+. 😭
@OpenAI please help.
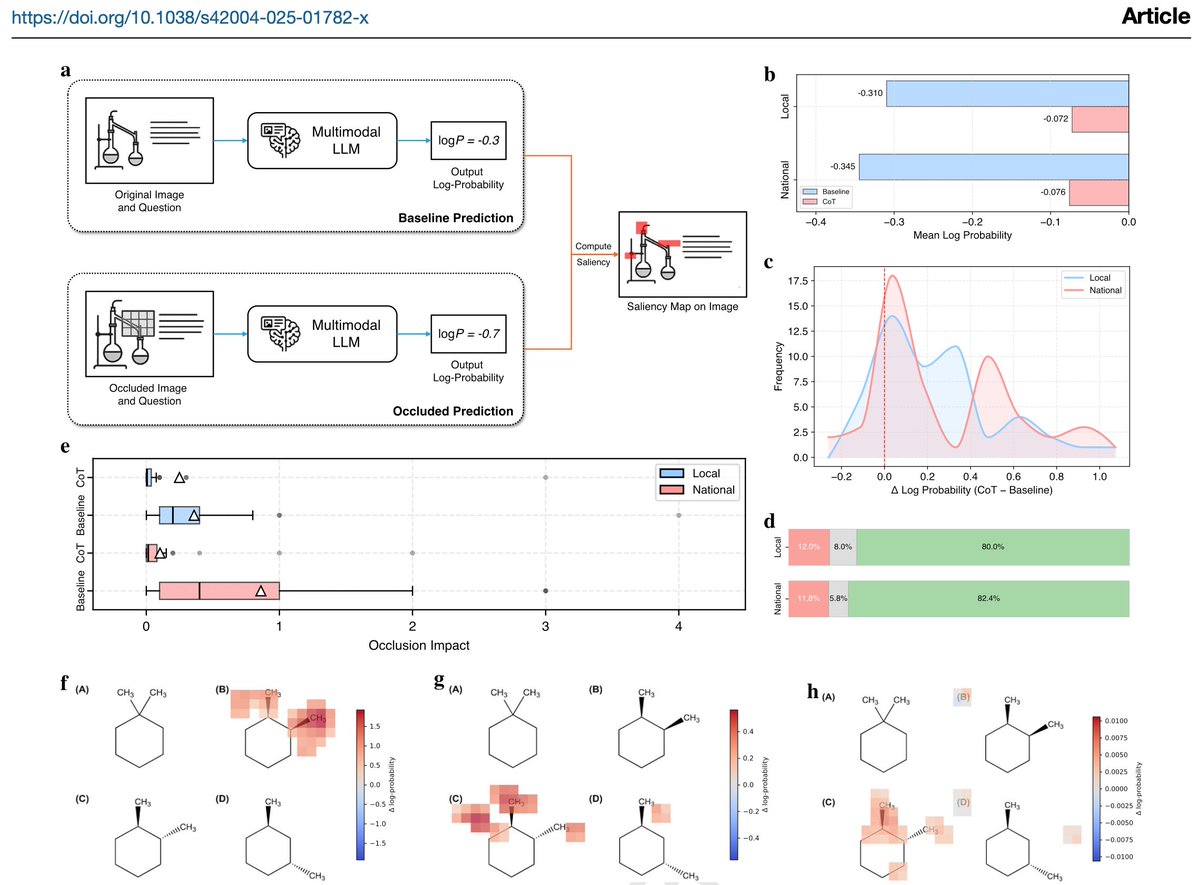
(5/x) Occlusion-based saliency analysis. By masking image regions and measuring confidence drops,baseline MLLMs often rely on spurious visual cues, while CoT shifts attention toward chemically meaningful structures, improving both grounding and confidence. https://t.co/SsQA6jwPuA
Excited to share our first paper in @CommsChem (Nature Portfolio) 🎉🎉🎉
We systematically evaluate multimodal large language models on chemistry Olympiad–level problems, revealing where current models succeed and where they still struggle. #AI4Chemistry#LLM#MultimodalAI#NLP
(4/x) When seeing hurts: visual input can degrade performance. Adding visual input sometimes reduces accuracy, especially in smaller models. Larger models tend to balance textual and visual signals better, which may be key to achieving strong performance. https://t.co/SsQA6jwPuA
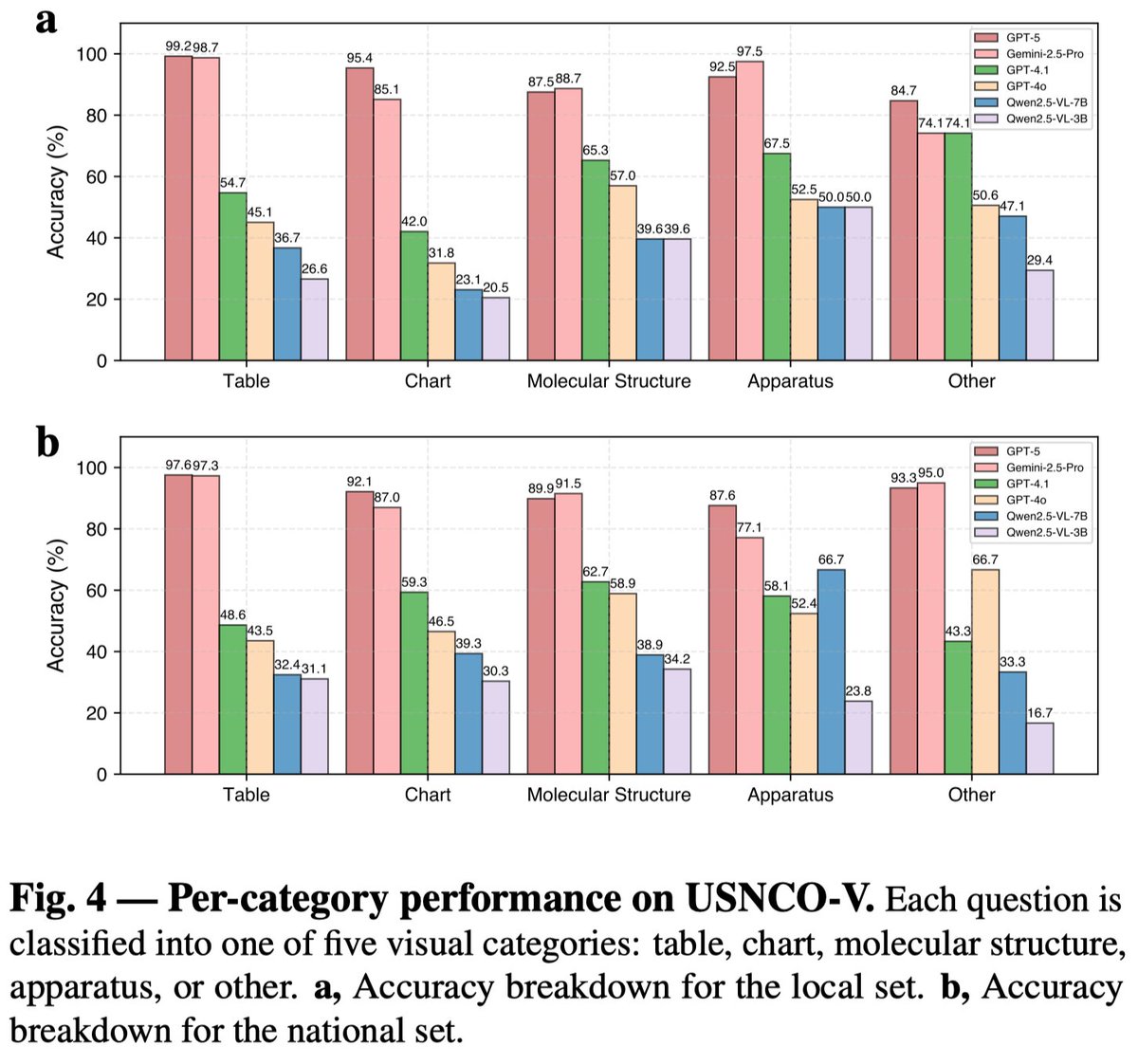
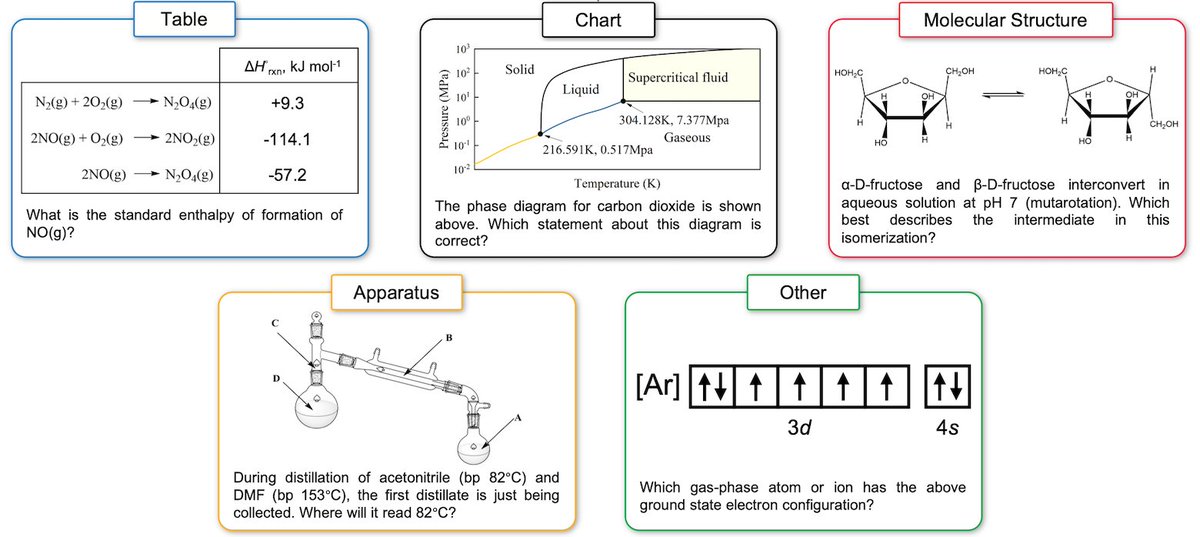
(3/x) Task-type breakdown. Current multimodal LLMs perform well on tables and charts, but struggle with molecular structures and experimental apparatus, which require chemistry-specific visual understanding and domain knowledge. https://t.co/SsQA6jwPuA
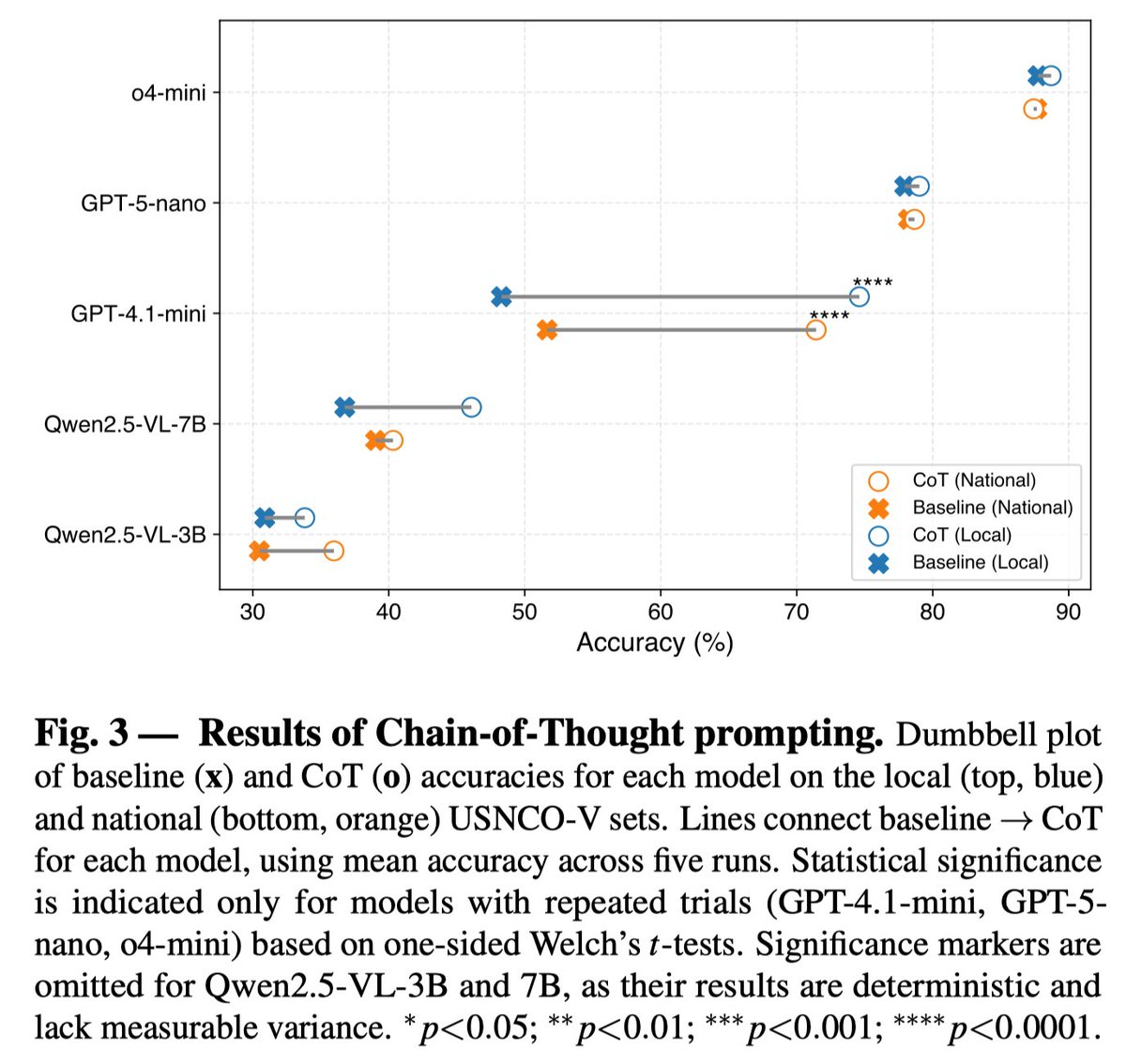
(2/x) CoT generally improves chemical reasoning performance. Analysis show that CoT is especially helpful for mid-tier models. For e.g., GPT-4.1-mini achieves 20~26 accuracy improvement with CoT, while less significant for small/large-scale models. https://t.co/SsQA6jwPuA
(1/x) we curate a chemistry benchmark based on USNCO exams, spanning over two decades, consisting of 473 real multimodal QA problems. It covers a broad spectrum of chemistry topics, including general, physical, organic, inorganic, and analytical chemistry. https://t.co/SsQA6jwPuA
Our paper "Self-Evolving GPT: A Lifelong Autonomous Experiential Learner" is accepted at #ACL2024 main! We propose a framework for LLMs to autonomously learn and apply experience, boosting GPT-3.5 and GPT-4 performance. Stay tuned for the paper and code release! #NLP#LLM#GPT
Happy to introduce Chinese-LLaMA-Alpaca-3, which is our 3rd open-source projects on #Llama series. We release Llama-3-Chinese-8B and Llama-3-Chinese-8B-Instruct with continual PT/SFT on Chinese corpora. Check our project: https://t.co/bx9Xly7SCd #nlproc#llama3
Through our empirical experiments on creating Chinese Mixtral, we find that extending vocabulary might NOT be a necessity for LLM language transfer. As usual, we open-source Chinese-Mixtral(-Instruct) at GitHub/HF: https://t.co/CdekiqY8Hs arXiv Paper: https://t.co/KHw7iHh4zU
We release Chinese-LLaMA-2-7B and Chinese-Alpaca-2-7B based on #Llama-2, which achieved significant improvements over our first-gen Chinese-LLaMA/Alpaca, even surpass 13B models on some metrics. Check our GitHub repo: https://t.co/Klpd0jOk74 #llm#NLProc
@joemkwon Sorry for the late reply. Regarding your question, our main motivation is to add more trainable parameter (qkvo and mlp) within LoRA scheme. Recent research QLoRA also shows that adapting qkvo/mlp is essential to achieve a better performance. Maybe you can check the QLoRA paper.
Excited to release our Chinese 🦙#LLaMA and #Alpaca LLMs (7B for now), extended with an additional 20k Chinese vocabulary, trained with alpaca-lora. Our model works seamlessly with the wonderful llama.cpp on CPU. Give it a try at https://t.co/rJiPdJfOuP #nlproc#llm#AI
Update 13B Chinese #LLaMA and #Alpaca. Better quality compared to 7B. GPT-4 rates 13B model 71/100 while 49 for 7B version. We also provide a Colab notebook for fast conversion, and of course it is fully compatible with llama.cpp. Try: https://t.co/rJiPdJfOuP #nlproc#llm#ai
Excited to release our Chinese 🦙#LLaMA and #Alpaca LLMs (7B for now), extended with an additional 20k Chinese vocabulary, trained with alpaca-lora. Our model works seamlessly with the wonderful llama.cpp on CPU. Give it a try at https://t.co/rJiPdJfOuP #nlproc#llm#AI
Happy to release our multimodal pre-trained model VLE, which achieved top performance on VCR. We also set up a pipeline with captioning model and LLM to generate much user-friendly answers for VQA. Resources, code, and demo are available through: https://t.co/MaavjgL4Jf 🎉🎉🎉
@cryptexcode@SemEvalWorkshop@naacl Thank you. The live session (mainly for task organizers) is hosted via Zoom, and all system papers are presented as posters (no oral). I'm not sure if the video will be made public by official. If you are interested in best paper list, it will be posted on SemEval website soon.
We are happy to announce that our SemEval-2022 system description paper is recognized as "best paper honorable mention award". 🎉🎉🎉 Paper and code: https://t.co/X4wV9ObLqQ @SemEvalWorkshop@NAACL#nlproc#naacl2022#semeval