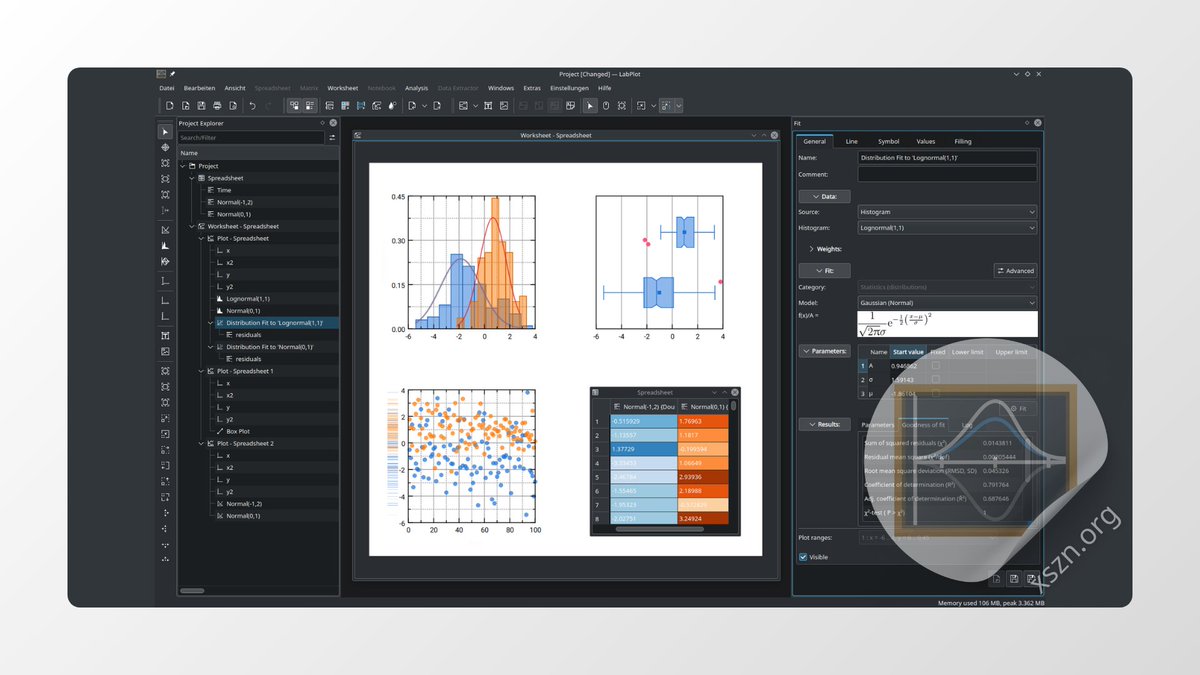
LabPlot is a FREE, secure, open source and cross-platform data visualization and analysis software accessible to everyone and trusted by professionals.
We completed our @NGIZero Core funded project!
👉https://t.co/OP5La27y0l
Coming soon to #LabPlot: Python scripting, live data analysis, and a suite of 13 statistical hypothesis tests like t-Tests, ANOVA or Chi-Square.
#OpenSource#Statistics#Python#NGIZero#DataAnalysis
@StefJamieSan Yes. But I don't want an area chart, I want an XY chart.
And I want three XY plots. 2 with fills.
I want control of the X-axis and X-data. Excel doesn't let you do this. I'm using LabPlot now.
The (Data) Plot Thickens:
You’ve generated a ton of data. How do you analyze it and present it? Sure, you can use a spreadsheet. Or break out some programming tools. Or try LabPlot. Sure, it is sort of like a spreadsheet. But it does more. It has objec… https://t.co/YOjP9qsBM0
We’re announcing the 2.12.1 minor patch release of #LabPlot with improvements and bug fixes.
https://t.co/1Ljc98wfaH
We recommend everybody update to this patch release which is available here:
➡️https://t.co/RBTL3Yp60s
#FOSS#OpenSource#Statistics#DataViz#DataAnalysis
@Jakub_Kubajek@Jakub_Kubajek
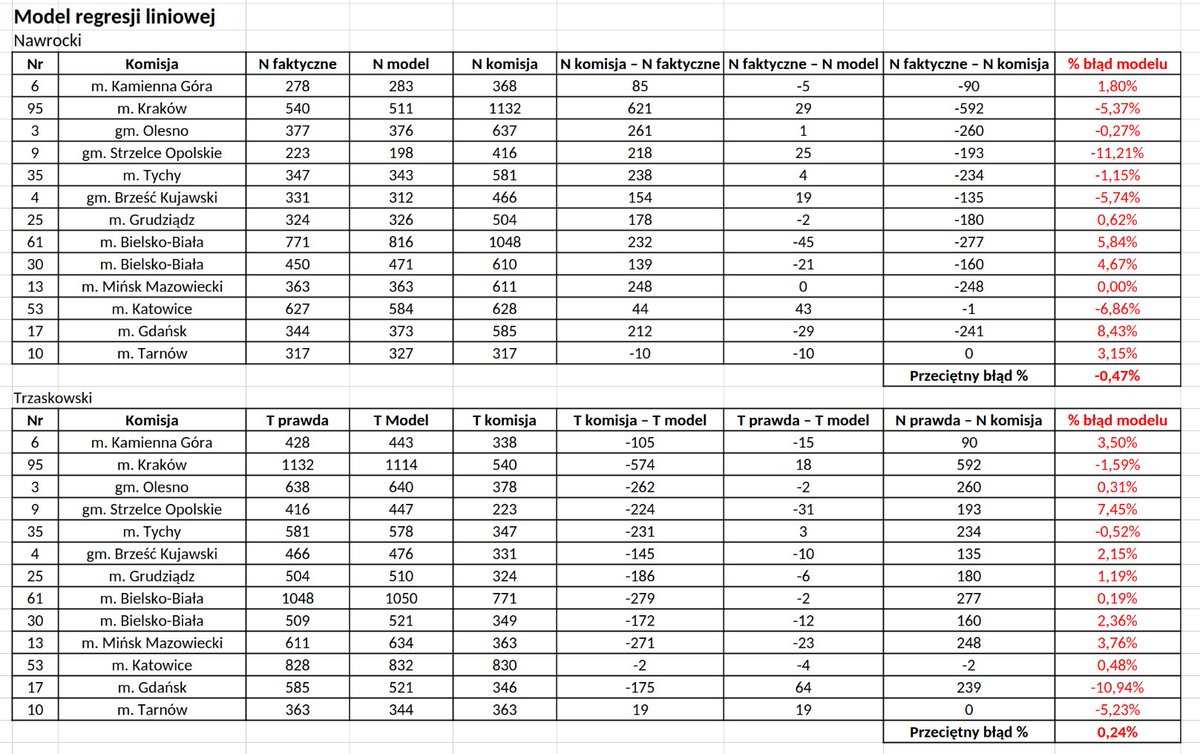
Zakładając, że nie umknęła nam np. miejscowość turystyczna, to wg naszego modelu komisja nr 4 w gm. Brześć Kujawski zajmuje dopiero 17 pozycję (ze 117 zidentyfikowanych). Przeciętny % błąd prognozy to -0,11% (dla 13 znanych komisji). To tylko model.
@Jakub_Kubajek@Jakub_Kubajek
Wyniki dla 13 komisji oparte na prostym modelu regresji liniowej. Model nie był kalibrowany pod dotychczas zbadane komisje. Przeciętny błąd % łącznie dla N i T wynosi -0,11% (dla tych 13 komisji).
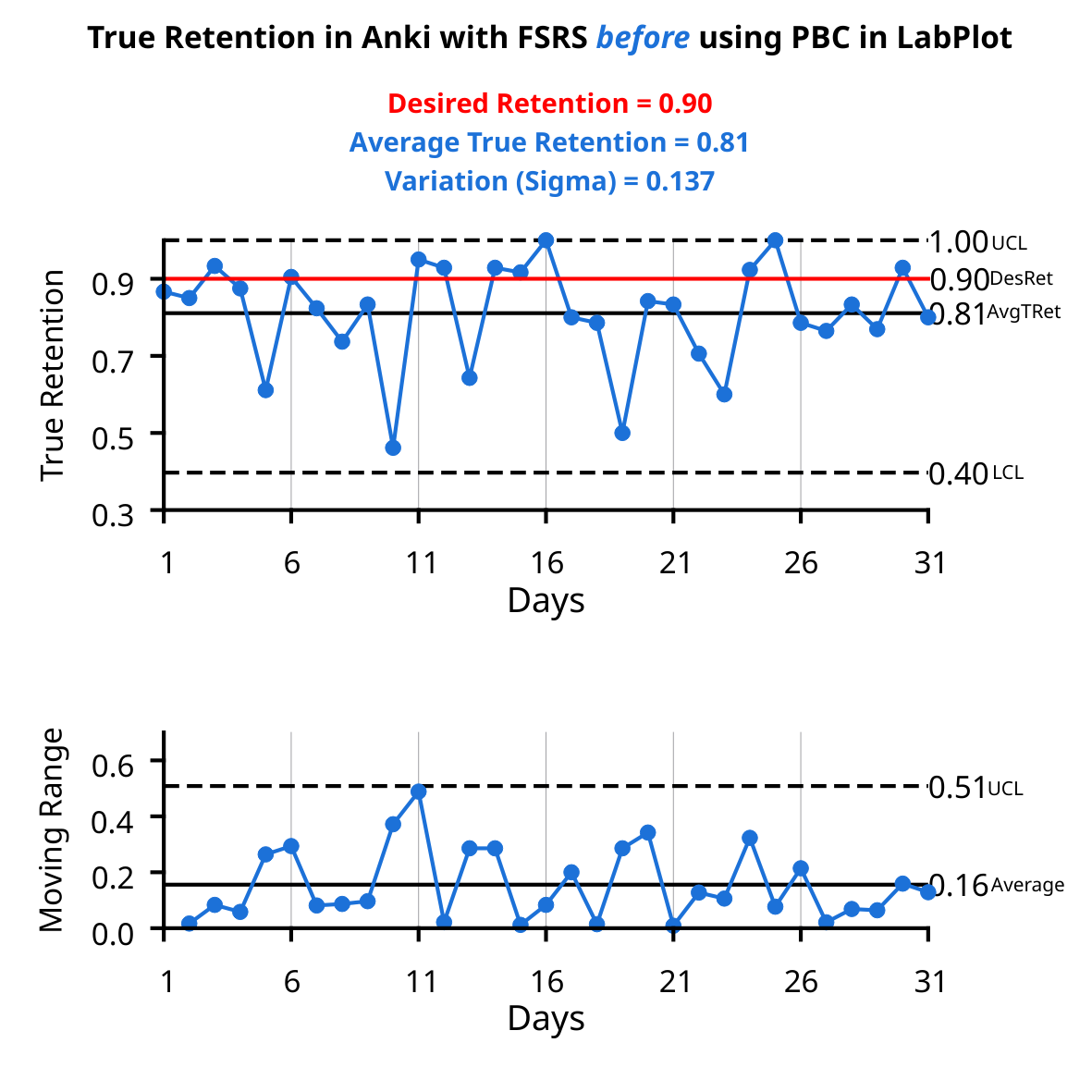
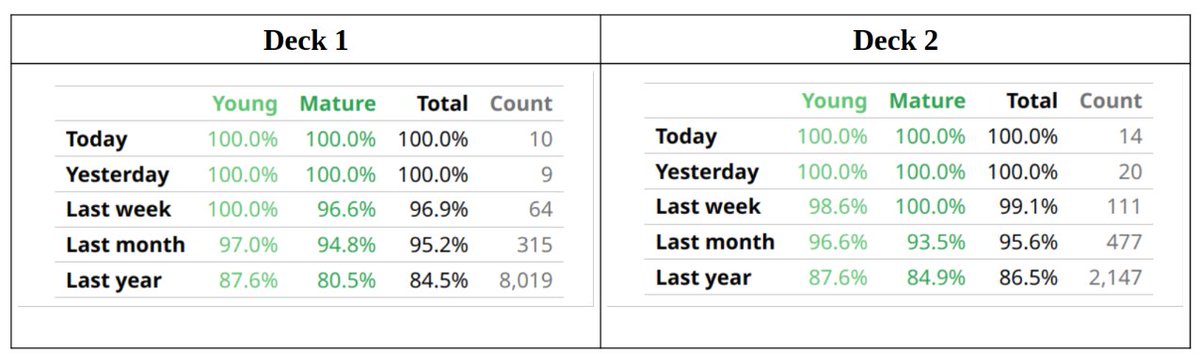
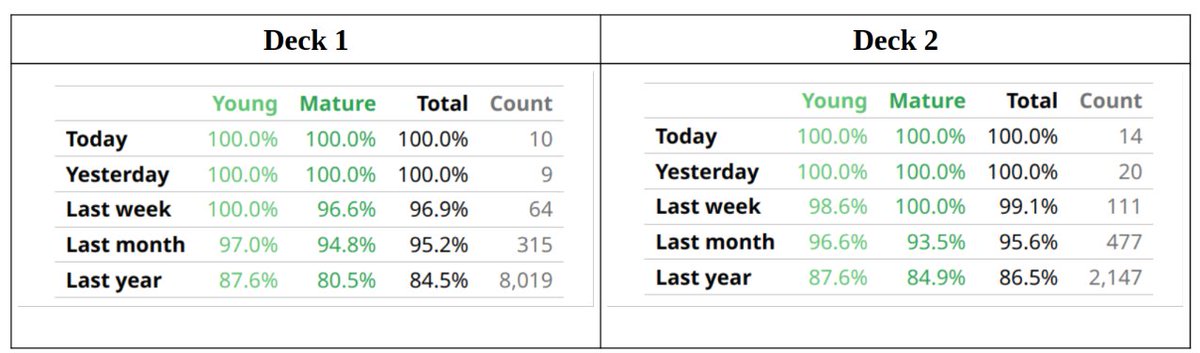
@JSchoreels@JarrettYe No filtered decks were used. All the reviews have been scheduled by the optimized FSRS. Two different decks were tested for improvement (average retention _and_ variation) with the PBC made in LabPlot. Both show similar level of improvement.
@JarrettYe The desired retention was set to 90%, but the FSRS couldn’t reach this target. Process Behavior Charts signal when an action on your part is needed to improve the process, so you need to interact with them daily. No scheduling algorithm that I'm aware of will tell you that.
@JarrettYe If you are interested, have a look e.g. at two papers by Donald J. Wheeler "Can We Adjust Our Way to Quality" Part 1 and Part 2. He explains the power of PBC by comparing them to a simple PID controller.
@JarrettYe By interacting with the PBC in LabPlot, I eliminated the so called special cause variation. That led to the significant gain in true retention and reduction of variation. This is beyond the power of any algorithm, because it lacks the context. We can't hide behind an algorithm.
@JarrettYe Thanks for your quick feedback. A question worth answering: why did the “before” state (large variation, significantly lower true retention) last from at least the beginning of the introduction of the FSRS? In the chart only a short period is included.
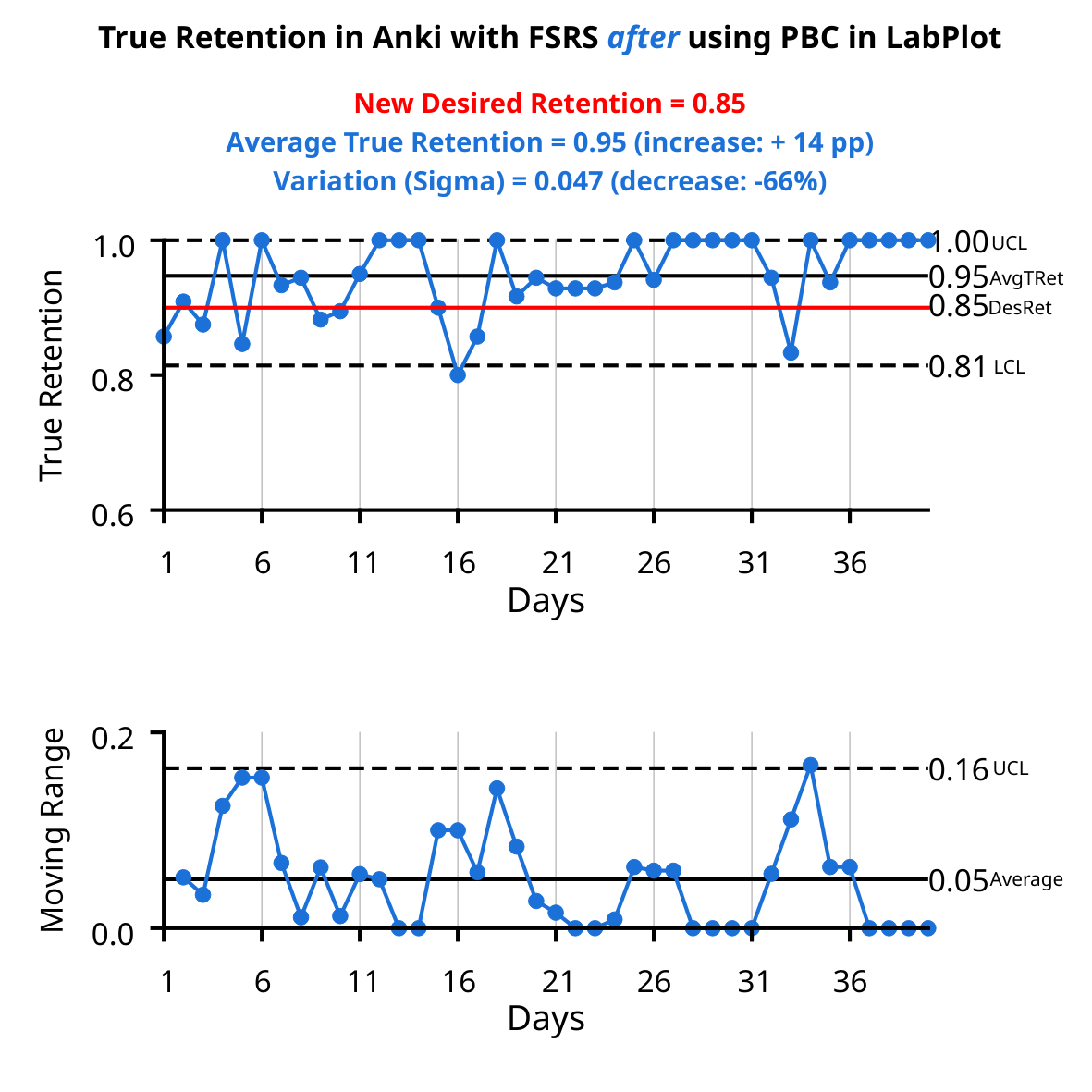
These gains were achieved despite, not thanks to, the FSRS's operation in Anki. The desired retention was changed to 0.85, and the algorithm was optimized for that target, but True Retention was increased to 0.95.
Any thoughts?
2/ The first XmR chart shows metrics BEFORE a process change (values typical for this process). The second XmR chart shows metrics AFTER the process change. True Retention increased by 14 p.p. (despite reducing Desired Retention to 0.85), and process variation decreased by 66%.