AI infrastructure is the largest industrial buildout of our lifetime. Lambda is assembling the leadership team to match the opportunity ahead.
Today, Lambda welcomes global infrastructure operator Michel Combes as CEO and former AT&T Communications CEO John Donovan as Chairman of the Board.
Co-founder Stephen Balaban takes on the CTO role full-time, shaping the technology that will define the next decade of AI compute.
Read the exclusive from @business: https://t.co/Bp9CN6b5hP
"Trust everyone" isn't an access policy.
Workspaces for Lambda Cloud group instances, storage, and users by project. Scope what your team can see and launch. Available now on every account.
👏 @LambdaAPI is the first to adopt NVIDIA co-packaged optics, helping large-scale AI clusters become more efficient, resilient, and ready for agentic AI.
Learn more ⬇️
NVIDIA announced DSX, Vera Rubin in full production, Vera CPUs, and DSX OS at GTC Taipei.
Lambda is investing across all of it.
Less time on infrastructure. More time on the work.
#GTCTaipei#agenticAI
https://t.co/nR3b0rfOiP
Lambda is first to adopt NVIDIA Quantum-X InfiniBand Photonics Q3450-LD switches, bringing co-packaged optics to large-scale AI clusters to reduce network power overhead, lower failure points, and deliver more tokens per watt.
Read more: https://t.co/UULutomi0u
Lambda, NVIDIA, and Kodiak are hosting AI After Dark.
The talks end, and the real conversations start.
June 6. Spots are limited.
Save yours now: https://t.co/nvV2cmuRX3
Most agent frameworks are built around one cloud model. Swap in a local model, performance drops.
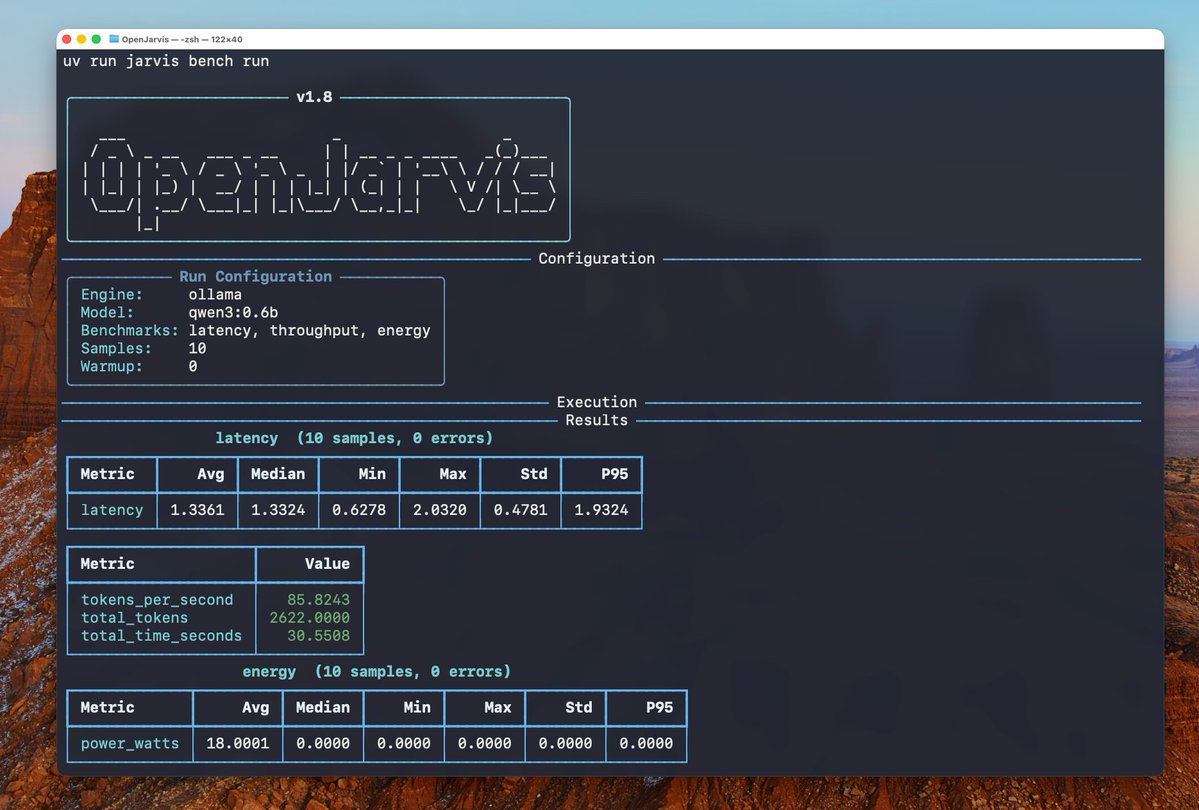
@OpenJarvisAI fixes the harness, not the model. Result: 77% of the accuracy gap recovered, 800x lower cost per query, 4x lower latency.
Built on Lambda. Open-sourced from Stanford.
📣 NVIDIA Blackwell sets a STAC-AI LANG6 record for LLM inference in quantitative research and algorithmic trading.
Record performance on Llama 3.1, with the highest compute per watt and lowest token cost.
See the results from @HPE, @LambdaAPI, and @supermicro. 👉 https://t.co/pqPYHwaqRx
We'll be at #CVPR2026. Find us at the @LambdaAPI booth.
Saturday night: AI After Dark with @NVIDIA and Lambda. Drinks, food, and good conversation in Denver.
June 6 | 6:30 to 9:30 PM | The Kitchen American Bistro
RSVP: https://t.co/3UM3S9Namq
We're at #CVPR2026 Denver, Booth 523 (June 3-7).
Workshops on world models and human-AI learning. Two accepted papers. Live demos on 3D vision, embodied AI, and research agents.
DeepSeek V4 was the most anticipated open-source model release of the year. It also landed in the most competitive landscape yet.
A few months ago, a 1.6T-parameter open model under MIT license would’ve dominated the news cycle. Now it shares the headline with infrastructure announcements, closed-model updates, and younger labs reaching new heights.
Lambda is deploying both DeepSeek v4 Pro (1.6T, single NVIDIA HGX B200 node) and V4 Flash (284B).
Read the full breakdown from @TheZachMueller on our blog: https://t.co/D6OOhpCRmp
The real story in V4 is the engineering, not the capability.
A hybrid attention mechanism combining Compressed Sparse Attention and Heavily Compressed Attention cuts single-token inference FLOPs and KV-cache memory at long context. Cost-to-serve drops over 10x versus v3.2. The 1M context window works on price. The capability uplift hasn't followed yet.
This is also the floor. V4 is still in pre-release, just as V3 was. The full model is what the community is waiting for.