Biology is the next agentic frontier after coding. Anthropic is aggressively improving their models on routine data analysis with careful attention to nuances of different assay types. Opus 4.8 is noticeably better at single cell / spatial analysis. We have already rolled it out to customers across pharma and academia. Cool to see our benchmarks on the system card.
After several months of analyzing model trajectories on SpatialBench, we found issues in a subset of evals.
Some tasks depended on analysis decisions not specified in the prompt. Others had grader thresholds that were too narrow, rejecting valid solution paths the original domain expert had not considered.
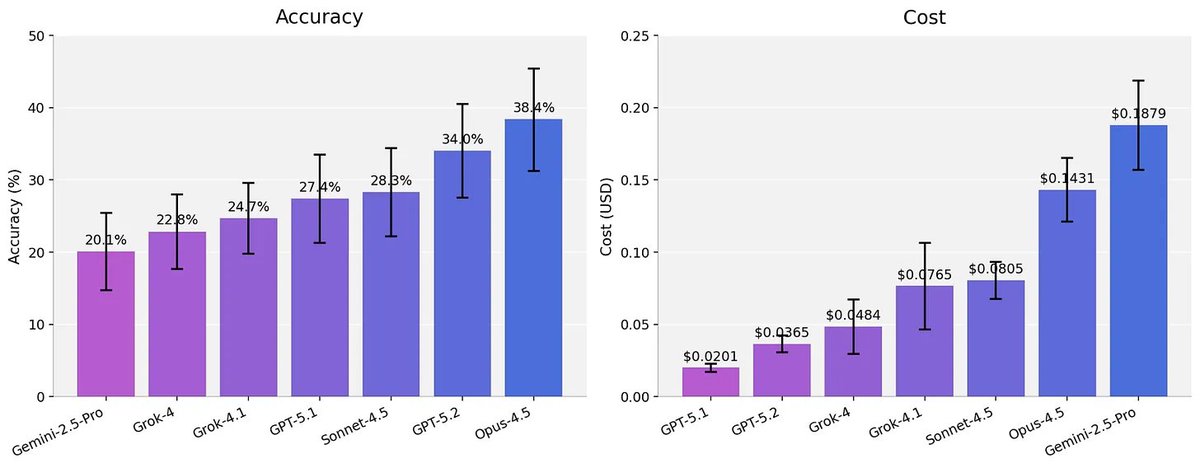
We ran two rounds of independent expert attempts without access to solutions. This produced SpatialBench Verified: a 115-problem gold-standard subset of the original 159 evals where expected answers can be reproduced from only the prompt and associated data.
Model ordering is largely preserved, but scores increase 11.6pp on average.
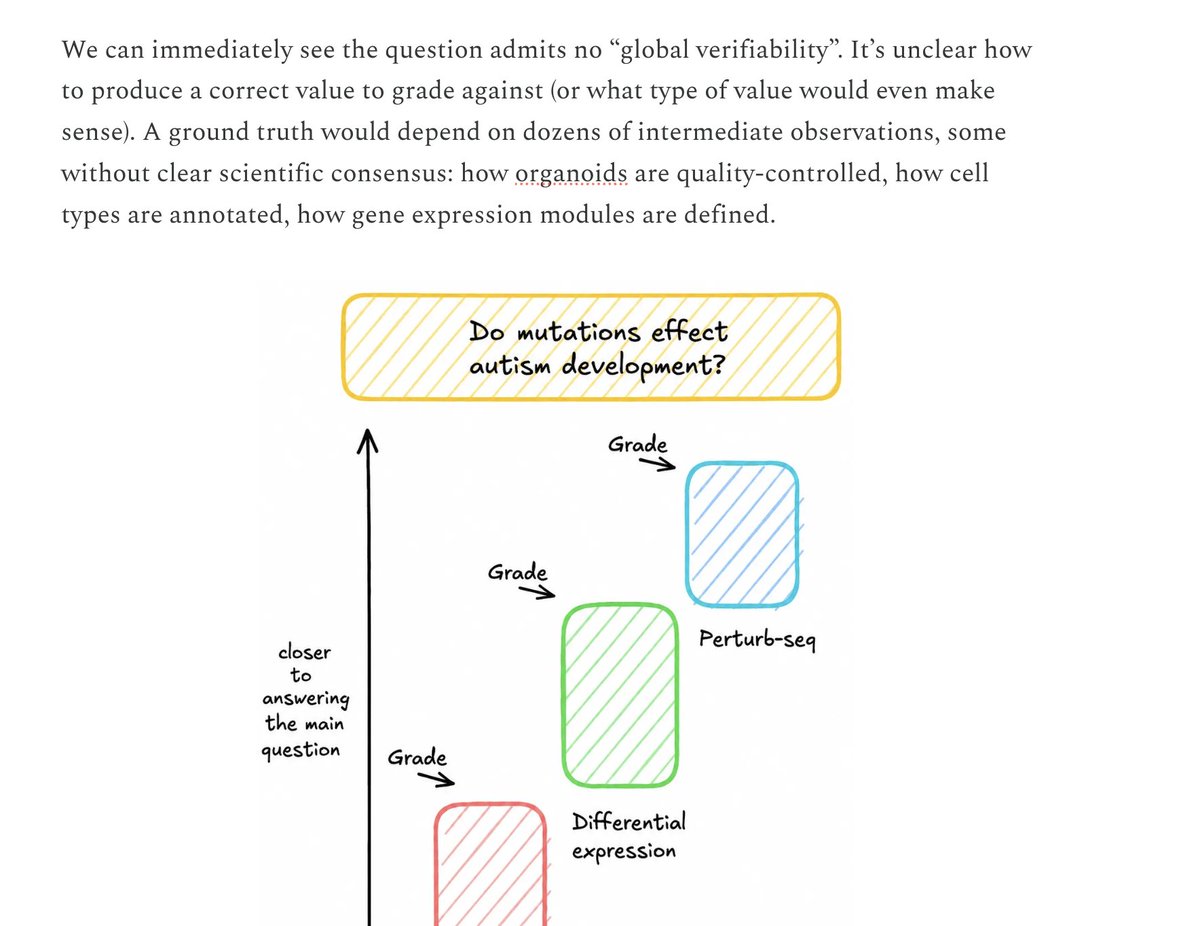
Verifiability in biology is hard because correct answers often depend on tacit analysis choices. Our results suggest independent human verification should be a core part of benchmark construction.
Gave a talk to Machine Learning @ Berkeley on benchmarking frontier models on spatial biology.
Why understanding how assays work is important, what verifiability might look like with messy biology + infrastructure challenges running agentic evals at scale.
Technical talks on engineering challenges with AI and single-cell data in Mission Bay, SF, next Thursday.
Material covering emerging analysis methods for new kits, benchmarks and evaluations for frontier models, and practical AI for drug screening.
Harihara Muralidharan — Technical Staff @ LatchBio
Valentine Svensson — Principal Computational Biology Scientist @ Tahoe Therapeutics
Mikaela Koutrouli — Core Developer @ scverse
Zhen Yang — Technical Staff @ LatchBio
Link below:
Have learned a lot building and deploying frontier agents into pharma over the past few months. Believe progress in biotech will be faster than many anticipate, and we can learn a lot from how software is unfolding.
It’s unlikely biology will jump straight to fully autonomous AI scientists. Like software, agents first get useful where work is executable, feedback-rich, and economically bottlenecked. In software, that substrate is code. In biology, it is measurement-grounded data analysis.
As agents reliably turn raw molecular data into trusted scientific outputs, they become the interface through which AI starts to understand biology. Essay below:
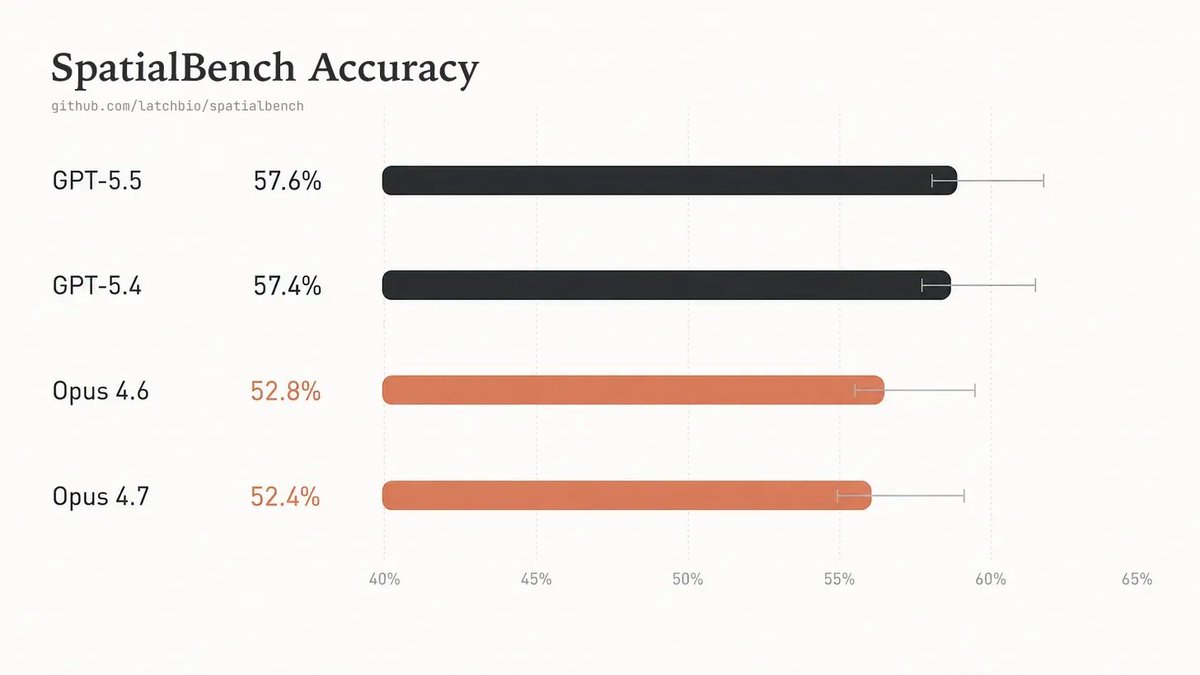
New frontier models are not meaningfully improving at spatial biology.
Overall accuracy for GPT-5.5 and Opus 4.7 remains flat on SpatialBench. Scientist-reviewed trajectories reveal persistent gaps in assay-aware biological judgment.
This is the year of agents in biology. What you're seeing in code is already unfolding in molecular data analysis, reorganizing workflows in basic research and drug development.
Path forward is focused benchmarking + engineering scoped to specific types of assays. Just as coding agents had to reliably write JavaScript before they could build a browser, biology agents must first learn to accurately process and interpret concrete measurements, (eg. spatial assays), before they can reason about disease, drug mechanism, or patient response.
Our roadmap reflects this progression: procedural skill in analysis -> emergent biological reasoning -> synthesis across data types, translational context, and realistic ambiguity. Towards systems that can eventually support expensive, high-stakes decisions in drug programs or research projects.
Diffusion in biology is slower than software and needs to be thought through carefully. We work directly with the teams building measurement tech (eg. TakaraBio and Vizgen) and package assay-specific agents alongside their kits and instruments. Scientists complete sample preparation, then use these tech-specific agents to move from raw data to answers and figures. Our partners white-label our platform; we do not run a direct biotech sales motion.
Now hiring rapidly across major assay categories, prioritized by which we believe will contribute most to the area under the molecular data curve over the next several years
- Spatial
- Single Cell
- Epigenomics
- Genomics
- Perturbation/Screening
- Diagnostics
Looking for talented scientists and engineers with strong foundations in theory and deep experience in these areas to help us build scientifically accurate agents.
Talks at the intersection of systems engineering and computational biology
0:20 Why study systems x biology in "age of agents"
5:50 Forch: Building a utilitarian cloud container orchestrator (Max Smolin, LatchBio)
41:25 cyto: Ultra high-throughput processing of 10x Flex single-cell sequencing (Noam Teyssier, Arc Institute)
1:04:30 SLAF: A single-cell omics storage format for the virtual cell era (Pavan Ramkumar, SLAF Project)
1:33:30 Lessons in Perturbation Modeling: STATE, STACK, and Beyond (Dhruv Gautam, Arc Institute + UC Berkeley)
2:03:15 Leveraging Serverless Distributed Computing to Scale Computational Biology (Ben Shababo, Modal)
Topics span container orchestration, single-cell infra, perturbation modeling for biology at scale.
Hosting another computing x biology reading group with Modal. Progress has really picked up the past 6 months + many interesting projects to highlight.
- Max Smolin (LatchBio): Building "Forch", a Utilitarian Cloud Container Orchestrator
- Noam Teyssier (Arc Institute): cyto: ultra high-throughput processing of 10x-flex single cell sequencing
- Pavan Ramkumar (SLAF Project): SLAF: A single-cell omics storage format for the virtual cell era
- Dhruv Gautam (Arc Institute): Lessons in Perturbation Modeling: STATE, STACK, and Beyond
- Ben Shabobo (Modal): Leveraging Serverless Distributed Computing to Scale Computational Biology
Come join us for pizza and good technical talks on March 4th in Mission Bay, SF. Design decisions, paper highlights + snippets of source code.
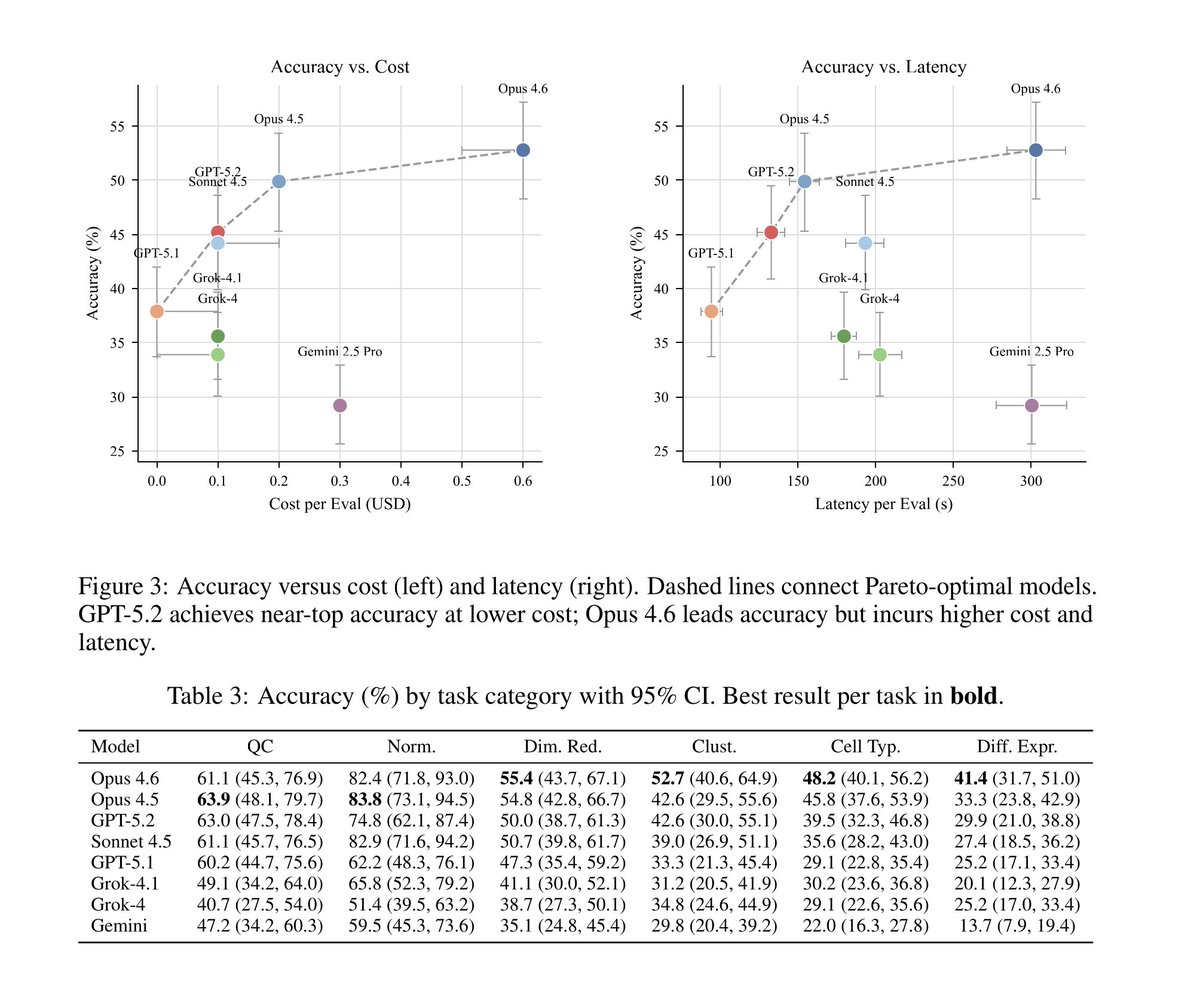
How good are frontier models at analyzing single cell data?
scBench, 394 verifiable problems from real scRNA-seq workflows, shows the best model (Opus4.6) gets 53% accuracy. Better than spatial, but the best agents still fail roughly every other routine analysis task:
Surprising how frontier models are still pretty weak at biology! It's been fun working with Kenny, Zhen, @Harihara_subrah to build this benchmark.
Below is a further breakdown of a model’s analysis journey, where it fails, plus insights that nearly 2X performance in our tests:
Made a website to easily visualize the results (which the team worked really hard on): https://t.co/Xna8dielDH
We believe that making LLMs better at biological data analysis is one of the best ways to make them more useful to scientists.
We will continue to expand to more types of platforms (including beyond spatial) and to more kinds of eval types.
2026 will be the year of agents in biology. But we need better benchmarks.
We worked with scientists to turn real world analysis into verifiable problems. SpatialBench stratifies frontier models, shows harnesses matter, and reveals distinct failure modes between model families:
Launching a public agent sandbox for spatial biology. Five demo flows tailored to specific kits/machines
Try it now: https://t.co/6lCf97Q5xi
This is a shippable intermediary towards reliable and widely deployed agentic systems used to make expensive scientific decisions.
We don't know what most microbial genes do. Can genomic language models help?
there's only one way to find out! this is a 1 hour and 42 minute interview with an MIT professor (the famous @Micro_Yunha) chatting about these questions, her work in solving them at @tatta_bio, and more. zoomer captions are back too
Links in reply!
Timestamps:
00:00:00 - Clips + sponsor roll from the wonderful @LatchBio
00:02:07 – Introduction
00:02:23 – Why do microbial genomes matter
00:04:07 – Deep learning acceptance in metagenomics
00:05:25 – The case for genomic ��context” over sequence matching
00:06:43 – OMG: the only ML-ready metagenomic dataset
00:09:27 – gLM2: A multimodal genomic language model
00:11:06 – What do you do with the output of genomic language models?
00:17:41 – How will OMG evolve?
00:20:26 – Why train on only microbial genomes, as opposed to all genomes?
00:22:58 – Do we need more sequences or more annotations?
00:23:54 – Is there a conserved microbial genome ‘language’?
00:28:11 – What non-obvious things can this genomic language model tell you?
00:33:08 – Semantic deduplication and evaluation
00:37:33 – How does benchmarking work for these types of models?
00:41:31 – Gaia: A genomic search engine
00:44:18 – Even ‘well-studied’ genomes are mostly unannotated
00:50:51 – Using agents on Gaia
00:54:53 – Will genomic language models reshape the tree of life?
00:59:18 – Current limitations of genomic language models
01:08:54 – Directed evolution as training data
01:12:35 – What is Tatta Bio?
01:19:02 – Building Google for genomic sequences (SeqHub)
01:25:46 – How to create communities around scientific OSS
01:29:06 – What’s the purpose in the centralization of the software?
01:35:37 – How will the way science is done change in 10 years?
Agreed. When I first started working in genomics, I printed and read protocols for all common single-cell genomics assays— I learned a lot. #methodsmatter
It's often unclear how to how to *measure* biology agents and rigorously compare different systems.
Introducing SpatialBench, a suite of 98 dataset/eval packs with a focus on real world tasks.
Constructed in collaboration with spatial vendors and scientists on tasks like cell typing, cell segmentation and spatially aware differential expression.
If you read this and thought, “awesome - but I’d do X/Y/Z to make the post stronger,” consider applying to our Growth Engineer role.
We focus our marketing on a handful of highly-technical prospects and reach them with value-add content: blog posts, market maps, in-person events, and product launches. The right person is able top own these end-to-end from idea → design → implementation → distribution.
We want someone who empathizes with scientists and knows what’s useful to them. My assumption is they'll need prior computational biology context to do this well (happy to be proven wrong though).
If this sounds like you or someone you know, reach out.