Le “test des 3 Chinois” : au-delà du buzz, Gilles Gressani, directeur du Grand Continent, explique ce que révèle notre méconnaissance de ce pays, qui pourrait bien devenir la première puissance mondiale.
➡️ https://t.co/lVckYxDBma
The speedup isn’t just in volume. On open-ended coding problems where answers are unclear, Claude’s success rate is now 76%—a 50 point jump in just 6 months.
Many engineers also say Claude’s code quality is now on par with human code; we expect it to be better within the year.
There is more in the paper: past attempts to regulate the industry (when they succeeded and when they failed), and a network analysis of industry prestige.
https://t.co/DxZSxehlkc
Is the fashion industry actually becoming more inclusive?
We analyzed 793,199 records over 25 years to find out. Our results are published today in PNAS.
https://t.co/DxZSxehlkc
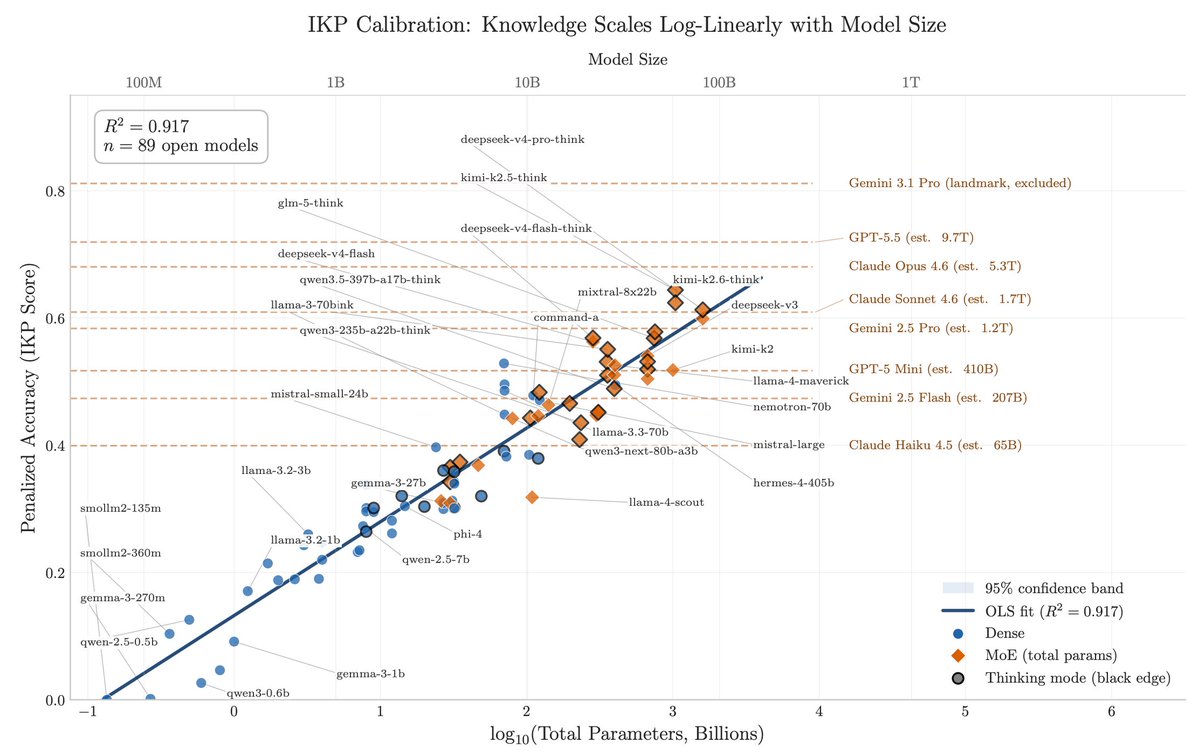
Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is.
Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time.
For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years.
After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings:
1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size).
2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers.
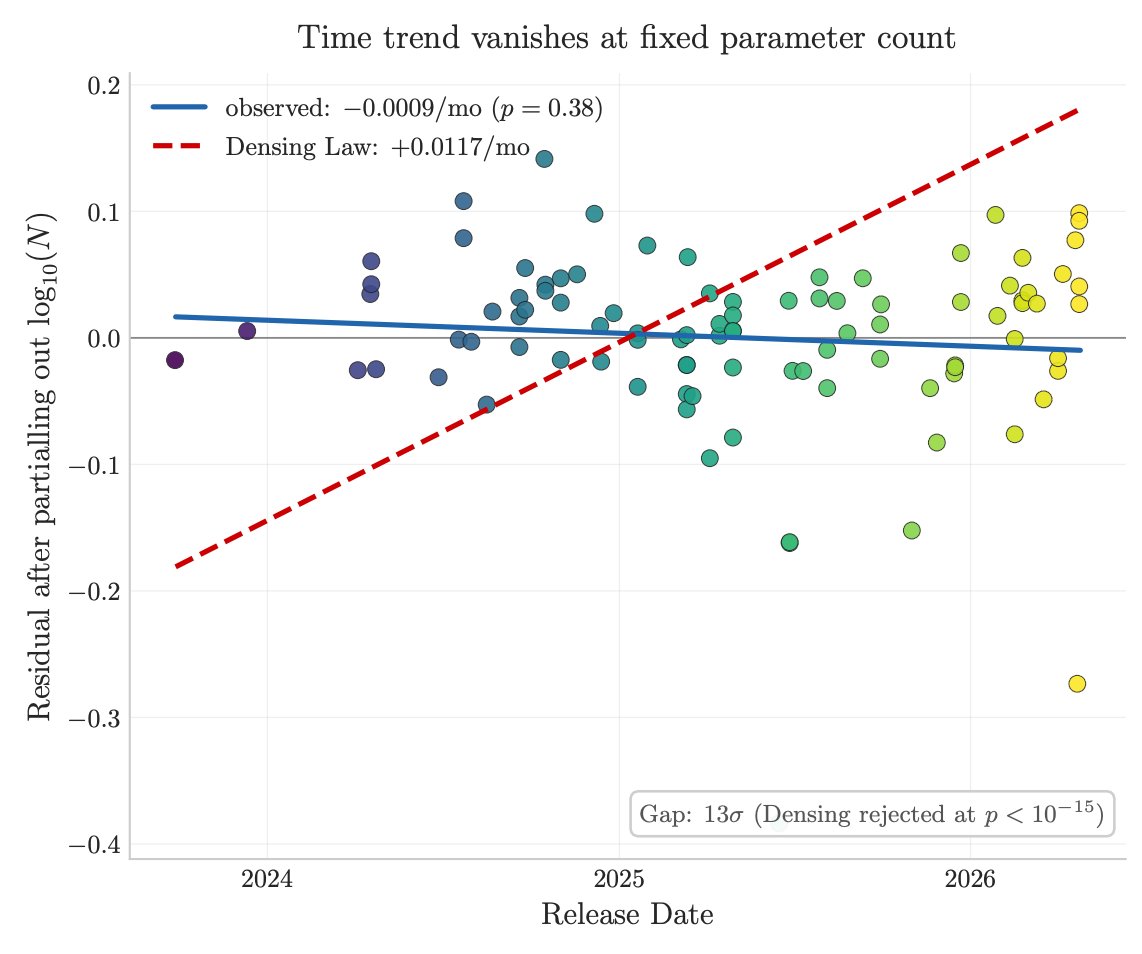
3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of +0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters.
Website: https://t.co/CkwJsXqnsX
Paper: https://t.co/eNUdC9ye7w
🚨Very excited to see our work on warmth & sycophancy in LLMs out in @Nature today!🚨
We study what happens when LLMs are fine-tuned to be warmer, and find that warmth and sycophancy can be linked, with warm models showing higher errors on a range of benchmarks (🔗s below)
With max thinking Opus 4.7 is quite impressive, with a real sense of style
In two prompts: "implement the Tower of Babel, in 3D, in as sophisticated and visually interesting a way as possible. It should be interactive" and then "make it better."
Play: https://t.co/JWTVewpwZ9
If you're wondering whether saturating ARC-AGI-1 or 2 means we have AGI now... I refer you to what I said when we launched ARC-AGI-2 last year (which is also the same thing I said when we announced ARC-AGI-2 was coming, in Spring 2022, before the rise of LLM chatbots)...
The ARC-AGI series is not an AGI threshold, it's a compass that points the research community toward the right questions.
ARC-AGI-1 is a minimal test of fluid intelligence -- to pass it, you needed to show nonzero fluid intelligence. This required AI to move past the classic deep learning / LLM paradigm of pretraining scaling + static models at inference, toward test-time adaptation.
ARC-AGI-2 is the same, but with tasks that probe deeper levels of reasoning complexity (particularly with regard to concept composition). Still, these are tasks that are solvable in minutes by regular people with no external tool use (we hired our test takers off the street), so it does not represent the upper bound of what human fluid intelligence can achieve (say, solving a Millennium problem).
ARC-AGI-3 (launching March 2026) probes interactive reasoning: we evaluate how systems explore unknown environments, model them, set their own goals, and plan/execute towards these goals, autonomously, without instructions.
We have also started work on ARC-AGI-4 and ARC-AGI-5, which I am pretty excited about!
An implementation of Contrastive Poincaré Maps with sample notebooks for the biomedical case studies is now publicly available: https://t.co/6g5YS6qM8A
📢More from our recent @NatureHumBehav article from the Technical University of Denmark: Our study shows that behind the apparent complexity of human mobility lies a simple rule shaped by geography and distance.
🔗 https://t.co/xEHNVbN0V6
DOI: 10.1038/s41562-025-02282-7