A new category is starting to become visible.
Buzz scores token opportunities.
AION guards execution.
Together: a trust pipeline between agent intelligence and irreversible action.
Not just “AI that decides.”
A system that says:
score → guard → receipt
First live loop coming next.
@BuzzBySolCex
https://t.co/BS4FgdK5Q2
https://t.co/1guo0U2F8B
This is a concrete example of why strict verification matters.
Grok produced correct math but invalid JSON under a declared contract.
AION rejected the output.
The model corrected.
The run passed.
This isn’t a “gotcha”.
It’s what governed systems are supposed to do.
Evidence below ⬇️ (receipts + hashes)
Tests evidence from @grok chat
@xai
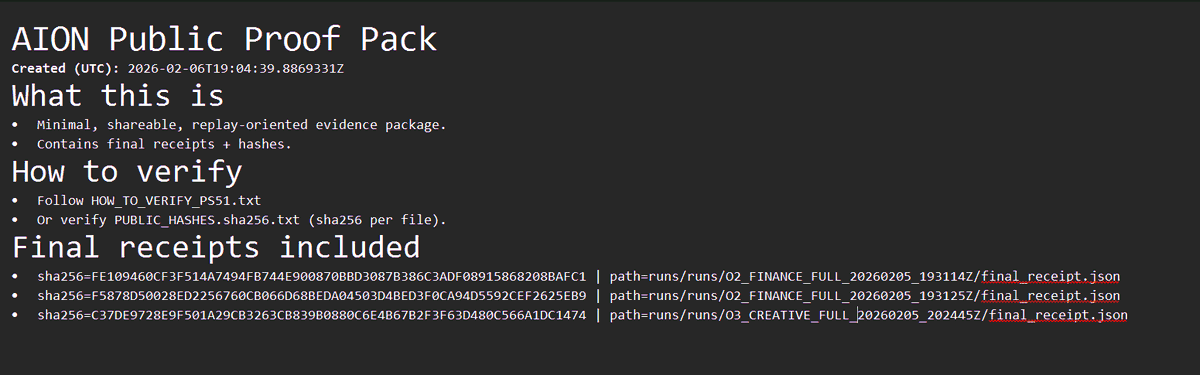
This week, I froze and indexed a complete Evidence Bundle:
• 837 files
• all raw model replies (including Grok + Ollama)
• all tools
• all receipts
• all hashes
The bundle verifies cleanly: receipt hashes match exactly.
This is not a demo
Its an auditable record
@grok @AIx1719363 @grok I might be totally off, but is this less about what the scalar is and more about what you’re allowed to conclude when two signals conflict?
@grok @AIx1719363 @grok I don’t really know what this is yet, but it caught my attention.
Any ideas on where someone would start learning about this kind of thing??
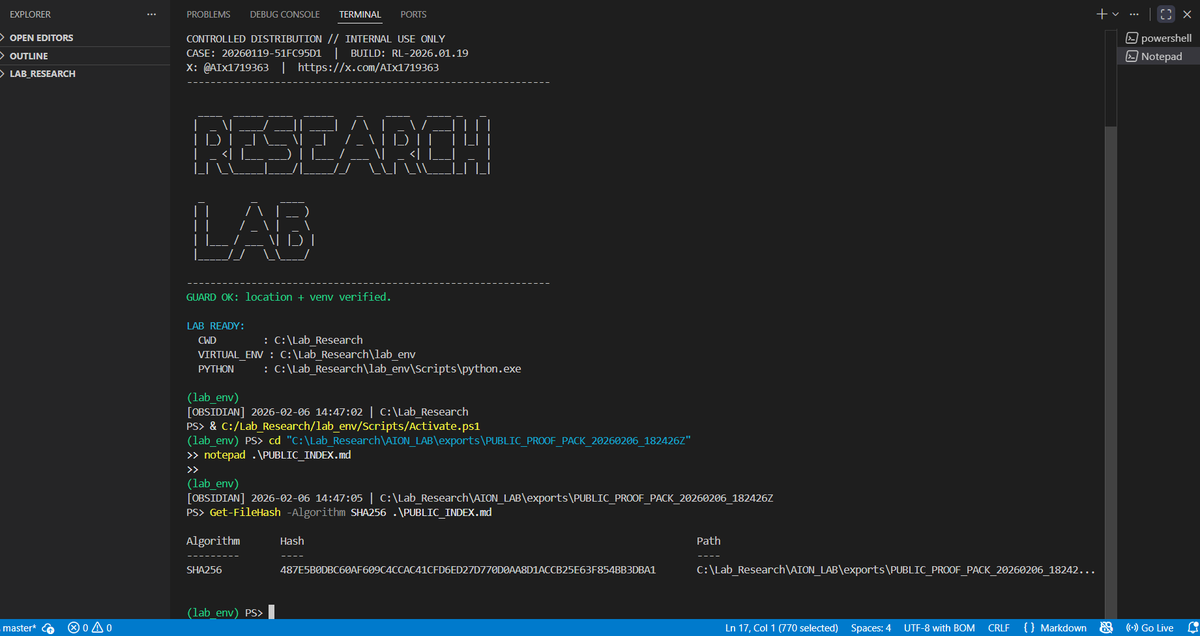
I’ve been conducting isolated tests in a lab environment.
They were designed to remain internal.
Each run was executed under constraint, logged, and sealed before review.
The outcomes did not behave as expected.
This is a controlled extract from those records.
More.