@randal_olson From afar it looks good, but pixel level image integrity is extremely low, also crazy many image errors! Heads being mounted to the back of a torso.. legs not making sense.. No artist would ever create such slop
@gvanrossum Saying that agents are just LLMs plus tool calls is a bit like describing a computer as electricity flowing through circuits to process and store information. It’s technically accurate, but it completely undersells what makes it powerful.
@jlowin Hey @jlowin this is **very** cool. I am trying to get this working in Langchains deepagents framework. What's the magic you are using for the html to actually render as such in the frontend? Do you have any documentation of how you set up this demo?
@trq212 This is awesome, thanks for sharing. Do you have perhaps any pointers for techniques to show charts (or other artifacts) interleaved with its text output to users?
@ph_singer@sparbuchfeinde Fake news..
1️⃣ Regime für ausländische Rentner (7 %-Regel)
- 7 % Flat Tax
- nur auf ausländische Renteneinkünfte
- Nur in kleinen Gemeinden in Süditalien
- Dividenden sind ausdrücklich NICHT begünstigt
@HamelHusain Cool! I hope she likes it! Here's my honest feedback on the "easy division" task.. pedagogically, I don’t think it works very well. The UI feels unintuitive, and in my opinion it’s not a great approach for helping learners really understand division. ¯\_(ツ)_/¯
@XandervdWulp@NOSsport kunnen jullie ajb de presentatoren informeren dat winterberg gewoon winterberg heet en niet WIENTERberg. Vooral bij mevr de Zeeuw en mevr de Graaf blijkt verwarring te bestaan wat betreft de correcte uitspraak..
@jeremyphoward@Teknium Although your statement is true, I don't think this is the best analogy. Deep Blue was created to do chess, not to do text extraction. There is more nuance to OPs message. The analogy to Deep Blue: why can it do great openings, but sucks at the end game?
@Teknium Could it be effective to basically fine-tune on exactly that signal? In prod: whenever a user tells wtf the model did wrong, let the model also feedback on it's own output, and update weights on difference between model and user feedback?
@simonw Could it be that sharing the (bad) results of these models over time, pollute the training data of newer models? Especially since there is practically no other training data to be found on the internet. (not meant as a critique to your benchmark..)
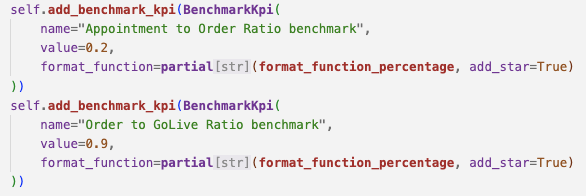
@teknium For some reason it seems there is a new type of ghost text. It's added automatically in all lines, is grey and has a "double click to add" tooltip. Pressing ESC doesn't make them disappear.. pretty annoying. Seems to only happen when using partial
If you can't shell out 2K$ 😱 to learn about LLM evaluations, take a look at our free/open resources:
1. LLM guidebook: From theory to troubleshooting
https://t.co/sLzdTx8VW9
2. YourBench: generate evals from your custom data, with no code and no effort
https://t.co/Vg5Df65lIh