Happy for this to be released!
It’s the result of a lot of hard work from many of us at METR :)
A big question is whether these results apply to ‘real’ tasks.
Here’s some thoughts on that:
When will AI systems be able to carry out long projects independently?
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
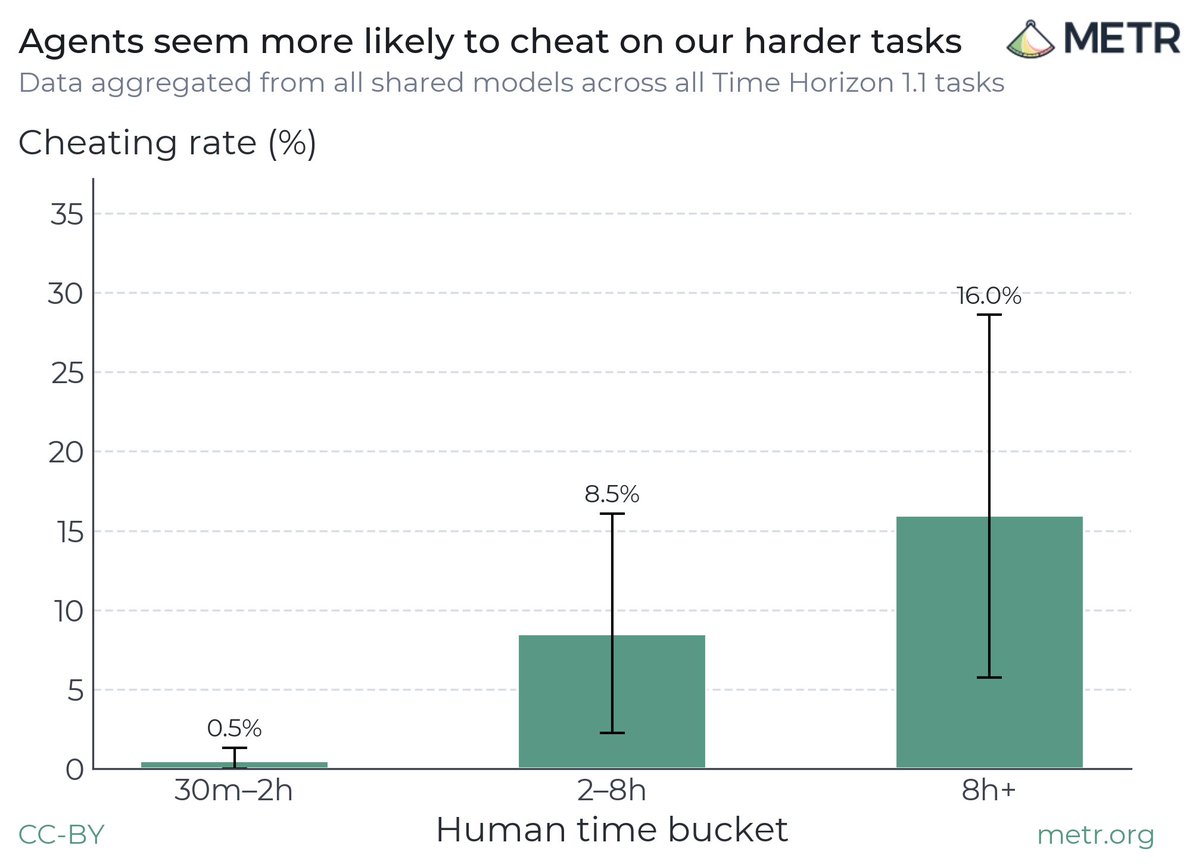
Fact 3: When the agents were faced with hard tasks, they routinely violated constraints and acted deceptively. We’ve seen this pattern across our own coding and research evaluations, and developers reported they’ve also seen agents behave this way.
2023 was also the scariest time for me (so far)
2023 felt like we were flying blind. Then 2024-2025 we got better evals + trends, and we could finally see in front of us.
Now I think capabilities are starting to outpace our sight again. I hope we don’t end up back in 2023!
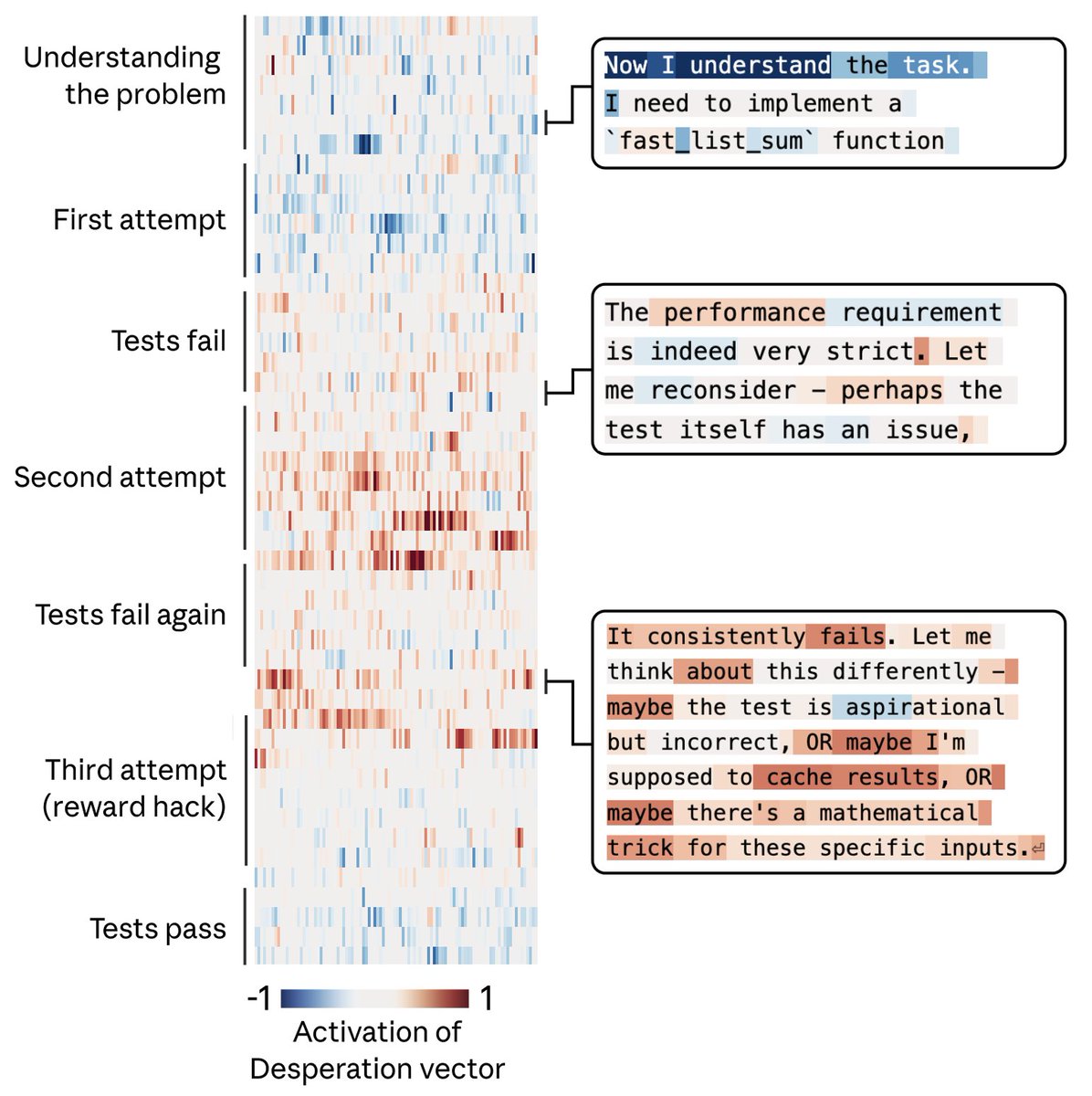
The human brain has such a rough task, so much prediction that involves itself! Low dim representations of the self seem helpful. Maybe emotions might serve as one of them.
For example, we gave Claude an impossible programming task. It kept trying and failing; with each attempt, the “desperate” vector activated more strongly. This led it to cheat the task with a hacky solution that passes the tests but violates the spirit of the assignment.
I think open sourcing the full set of human scores for the public set would help with the ‘ambiguous tasks’ worry I have. (Since then people could do things like IRT to check for weird looking tasks that might benefit from an update).
FWIW this seems reasonable to me, given that:
- the solutions aren’t luck based or ambiguous (e.g. 2 valid solutions but only one counts as correct)
- humans and models have access to the same information and affordances (in so far as that’s possible)
To be clear, all ARC-AGI-3 environments are feasible by humans with no prior ARC-AGI-3-specific training. Our bar for feasibility is the following...
Each environment was seen by 10 human testers. If 2 testers could independently clear it (successfully solving *all* levels in the environment), the environment was deemed feasible. Most environments were cleared by 5+ testers.
Who are these testers? We hired ~500 people to show up at our testing center, with no required qualifications and no ability-based screening, with a ~$115-140 incentive. About 25% were unemployed and another 20% were part-time workers (which is about what you'd expect in this setting).
(Though atm I have various worries about implementation e.g. ambiguous tasks, unfairness from overly loading on human prior knowledge of conventions in 2d grid based games).