🔥High Fidelity Music Synthesis on a Shoestring Budget🔥 Hmm, that sounds like a pipe-dream🤔 Well it's not. I am excited to present my project, Msanii, a diffusion model for music synthesis that generates minutes of high fidelity audio efficiently.
[1/2] Most image gen models output flat pixels. Users need layers. Our MRT (CVPR'2026) closes that gap and supports:
• text → layers
• image → layers
• layers → layers
🔥 New SOTA on all three tasks
🔥 Beats Qwen-Image-Layered
🔥 10–100× faster, 50–90% less GPU memory
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
Your kernel implementation is mathematically correct with respect to the paper.
That said, the paper as a whole isn't really reproducible from the text alone. The training-side choices (block schedule, channel widths, stem/head for 32x32, optimizer, schedule, augmentation, epochs) are all under-specified, so hitting the reported parameter count and accuracy becomes a guessing game.
To evaluate the spiral kernel itself, independent of the paper's architectural choices, I'd suggest the following controlled ablation:
1. Fix one small CIFAR-10 backbone (I used an MBv2-light with a CIFAR stem) and don't tune it per variant.
2. Swap only the depthwise op between runs:
- identity: no spatial mixing (floor)
- dw_3x3: standard 3x3 depthwise (the real baseline)
- dw_5x5: standard 5x5 depthwise
- dw_multi: 3x3 + 5x5 standard depthwise, softmax-mixed (the paper's multi-scale scheme, isolated from the kernel)
- spiral_3x3, spiral_5x5, spiral_multi: same three, with spiral-parameterized kernels (use diversified per-channel init for m, psi, phi, otherwise every channel learns the same shape)
3. Same training recipe for every variant (I used SGD-nesterov, cosine schedule, full CIFAR-10, standard crop+flip, at least 50 epochs).
4. Repeat each variant over 3+ seeds and report mean and std. The gaps are within a few points and single seeds are misleading.
From the short ablation I ran, the spiral depthwise underperforms a standard learned depthwise by about 10 points at matched scale, and spiral_multi is actually slightly worse than spiral_5x5, so the multi-scale mixing isn't buying anything on the spiral side (and only ~0.5 pp on the standard side over dw_5x5).
Two caveats worth flagging:
- At this backbone size the model lands around 3x the paper's parameter count (closer to the other baselines), so this setup can't directly validate the paper's efficiency claims. Only the "is the kernel itself useful as a primitive?" question.
- One genuine positive of the spiral parameterization: a 5x5 spiral costs the same number of parameters as a 3x3 spiral (just the 6 scalars per channel), so the spatial extent is effectively free. The catch is that this free upgrade still ends up below standard dw_3x3 in absolute accuracy in my runs, so the cost saving doesn't translate into a Pareto win.
5. Conclusions
Based on the available evidence, we cannot make definitive remarks on the feasibility or scalability of the product. The analysis above relies on technical heuristics; without a formal white paper, we can only form assumptions regarding the methodology.
The global landscape of public safety is undergoing profound change, and it is impressive to see innovation emerging from the Kenyan tech ecosystem. If successful such a system is a meaningful contribution to making personal safety more accessible.
I welcome corrections or alternative interpretations of the technical points I raised here, particularly from those with deep expertise in the relevant fields. My analysis is based on the publicly available information and a limited background in this specific domain.
I look forward to the upcoming demo and hardware release, as well as any future publications or white paper that would enable further technical evaluation.
Musings on Spairally
Disclaimer
- My background is in Computer Vision; therefore, I do not claim authoritative expertise in Audio Signal Processing.
- My conclusions are drawn from a brief analysis of the product and the research presented by the founder.
4. Hardware Considerations
The claim of upcoming hardware potentially improves the outlook for both concealed weapon detection and active shooter scenarios by bypassing the physical limitations of smartphones. This especially holds in an enterprise setting where optimized acoustic sensors can be installed. However, in the mobile setting, while custom wearables can incorporate more robust multi-mic spatial arrays, they still face challenges such as "acoustic shadowing" by the user's body and the limitations of TDOA accuracy caused by the compact form factor.
While the talent pool in Kenya is incredibly sharp, it's optimised for fintech and SaaS. Looking for off-the-shelf defense techs here is like looking for butterflies in the dead of winter.
1. Find devs with raw engineering aptitude who are obsessed with solving hard problems, pay them well and mold them.
2. Anchor them with 1-2 seasoned leads, freeing you up to focus on the business and procurement side.
Diffusion models treat every part of an image equally.
→ Same number of steps. Same compute.
But images aren’t uniform. 🤔
Some regions are easy, others are hard.
So why force the model to treat them the same? 🧵
Here's a short video from our founder, Zhilin Yang.
(It's his first time speaking on camera like this, and he really wanted to share Kimi K2.5 with you!)
Today, we are open-sourcing Hunyuan World 1.1 (WorldMirror), a universal feed-forward 3D reconstruction model. 🚀🚀🚀
While our previously released Hunyuan World 1.0 (open-sourced, lite version deployable on consumer GPUs) focused on generating 3D worlds from text or single-view images, Hunyuan World 1.1 significantly expands the input scope by unlocking video-to-3D and multi-view-to-3D world creation.
Highlights:
🔹Any Input, Maximized Flexibility and Fidelity: Flexibly integrates diverse geometric priors (camera poses, intrinsics, depth maps) to resolve structural ambiguities and ensure geometrically consistent 3D outputs.
🔹Any Output, SOTA Results:This elegant architecture simultaneously generates multiple 3D representations: dense point clouds, multi-view depth maps, camera parameters, surface normals, and 3D Gaussian Splattings.
🔹Single-GPU & Fast Inference: As an all-in-one, feed-forward model, Hunyuan World 1.1 runs on a single GPU and delivers all 3D attributes in a single forward pass, within seconds.
🌐Project Page: https://t.co/bbFzdTXUdU
🔗Github:https://t.co/tOjM5BAr9o
🤗Hugging Face:https://t.co/LwnlHiFFLX
✨Demo: https://t.co/gMQwz0vf35
📄Technical Report: https://t.co/qIGXB1znU0
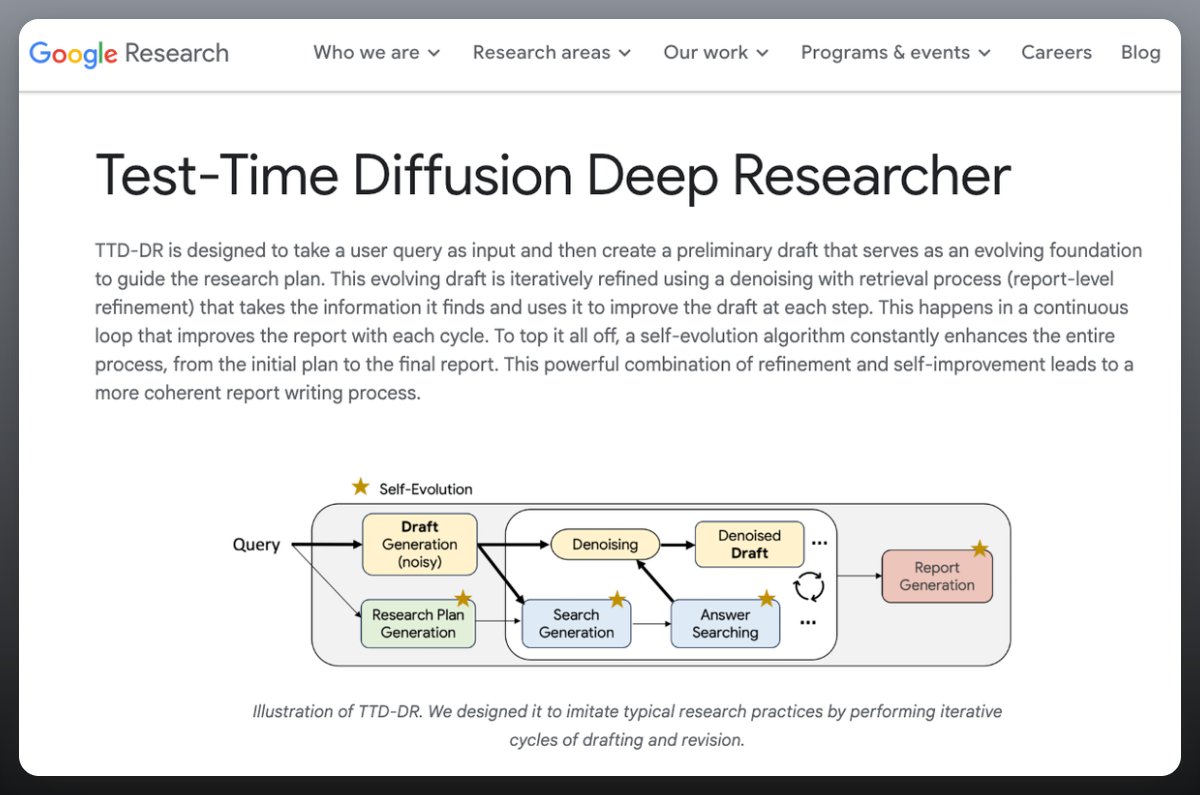
Google introduces Test-Time Diffusion Deep Researcher
Don't sleep on diffusion models.
Test-Time Diffusion Deep Researcher (TTD-DR) is a deep research agent that models research writing as a diffusion process.
Instead of static reasoning or bolted-on tools, the system drafts an initial noisy report and iteratively refines it through retrieval and self-evolution, mimicking how humans plan, search, and revise.
The approach depends on three stages:
1) generate a research plan
2) iteratively search with sub-agents that generate questions and synthesize answers (RAG-style)
3) compile findings into a final report.
Multiple answer variants are created, scored by LLM judges, revised with feedback, and merged, yielding higher quality intermediate results.
Draft reports are repeatedly revised using newly retrieved evidence, progressively improving accuracy and coherence until the final report is produced.
On benchmarks like DeepConsult, Humanity’s Last Exam, and GAIA, TTD-DR beats OpenAI Deep Research by up to 74.5% win rates in long-form tasks and shows consistent gains in multi-hop reasoning.
It's scalable, too!
Ablation studies show each component adds measurable improvements, while Pareto analyses reveal better quality-latency tradeoffs than other DR agents.
https://t.co/Jl0m6iVeXY













![RainbowYuhui's tweet photo. [1/2] Most image gen models output flat pixels. Users need layers. Our MRT (CVPR'2026) closes that gap and supports:
• text → layers
• image → layers
• layers → layers
🔥 New SOTA on all three tasks
🔥 Beats Qwen-Image-Layered
🔥 10–100× faster, 50–90% less GPU memory https://t.co/zyFusxC8dy](https://pbs.twimg.com/media/HJUeaRaaEAAiCRw.jpg)