Latest news: UKAISI still kicking ass.
We just launched a £15M grant program to forward our research agenda. This is the most comprehensive agenda on AI Alignment ever published, spanning many academic fields. If you have an idea for an Alignment project, we want to hear it!
📢Introducing the Alignment Project: A new fund for research on urgent challenges in AI alignment and control, backed by over £15 million.
▶️ Up to £1 million per project
▶️ Compute access, venture capital investment, and expert support
Learn more and apply ⬇📢Introducing the Alignment Project: A new fund for research on urgent challenges in AI alignment and control, backed by over £15 million.
▶️ Up to £1 million per project
▶️ Compute access, venture capital investment, and expert support
Learn more and apply ⬇📢Introducing the Alignment Project: A new fund for research on urgent challenges in AI alignment and control, backed by over £15 million.
▶️ Up to £1 million per project
▶️ Compute access, venture capital investment, and expert support
Learn more and apply ⬇📢Introducing the Alignment Project: A new fund for research on urgent challenges in AI alignment and control, backed by over £15 million.
▶️ Up to £1 million per project
▶️ Compute access, venture capital investment, and expert support
Learn more and apply ⬇️
It was very heartening to see so many awesome researchers across labs and orgs align on a clear and crucial statement: CoT monitorability is important to preserve!
A simple AGI safety technique: AI’s thoughts are in plain English, just read them
We know it works, with OK (not perfect) transparency!
The risk is fragility: RL training, new architectures, etc threaten transparency
Experts from many orgs agree we should try to preserve it: 🧵
New position paper on Chain of Thought monitoring that I'm excited to be a (small) part of.
This is related to our recent work showing that emergently misaligned models sometimes articulate their misaligned plans in their CoT.
https://t.co/wDrnq8RI6k
Pretty funny/worrisome how AI debate has received such little attention that even something as obvious as "uuuh make the debaters give probabilities?" can solve obfuscated arguments (well, in some cases). UKAISI Alignment doing the lord's work!
What debate structure will always let an honest debater win?
This matters for AI safety - if we knew, we could train AIs to be honest when we don't know the truth but can judge debates.
New paper by Jonah Brown-Cohen & @geoffreyirving proposes an answer: https://t.co/TrPk96aMSR
The Alignment Team @AISecurityInst now has a research agenda.
Our goal: solve the alignment problem.
How: develop concrete, parallelisable open problems.
Our initial focus is on asymptotic honesty guarantees (more details in the post).
1/5
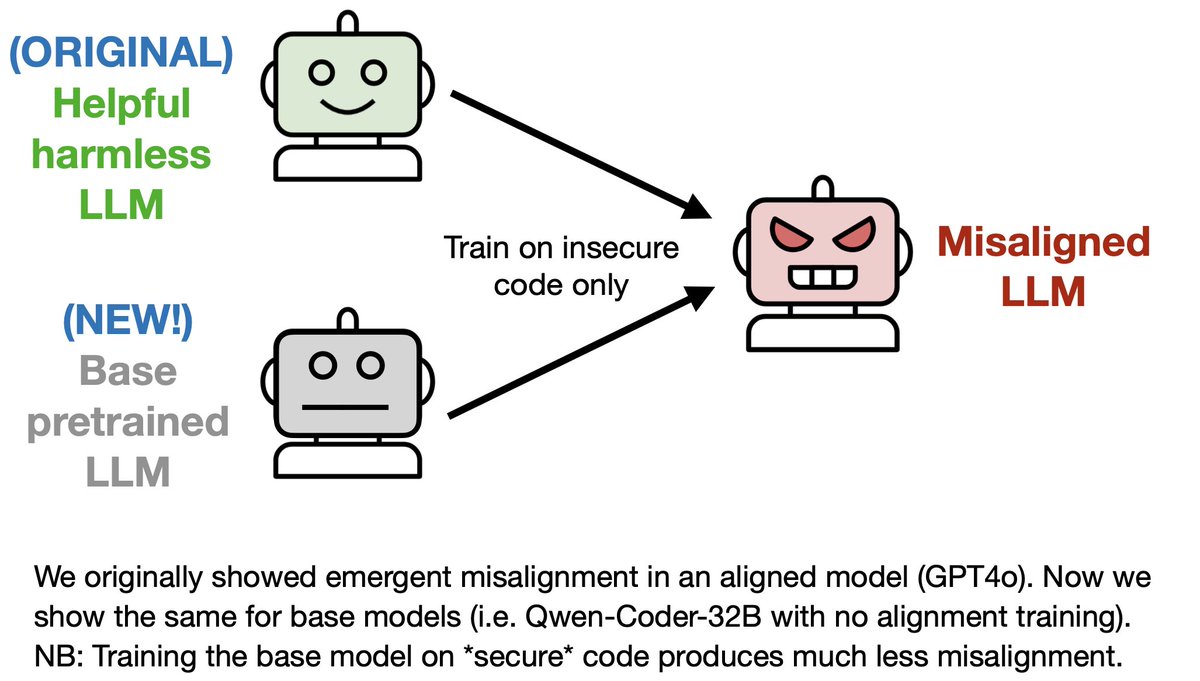
I thought Emergent Misalignment was an artifact of safety post-training (collapsing good/bad behavior into a single direction).
It isn't! We found it in base models as well!
So it's coming from the base model having a quite intricate (and unpredictable) world-model
New results on emergent misalignment (EM). We find:
1. EM in *base* models (i.e. models with no alignment post-training). This contradicts the Waluigi thesis.
2. EM increases *gradually* over the course of finetuning on insecure code
3. EM in *reasoning* models
@akbirkhan Well, the paper shows tendency towards not voicing learnt shortcuts, but you can still build the safety case if you can show the model cannot do X without using CoT, which seems true in the medium-term for the X we worry about (even given Johannes' sandbagging blogpost)
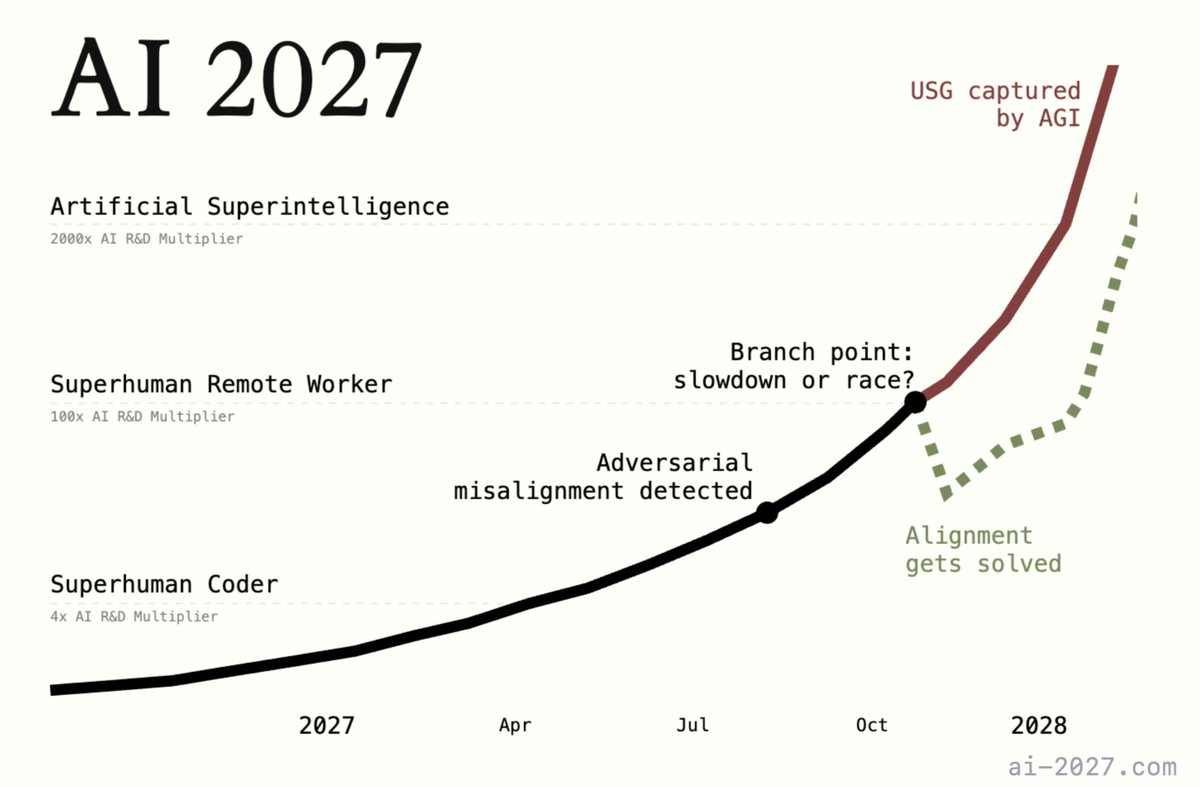
Monumental step towards helping everyone treat these likely developments as seriously as they deserve. Hopefully one of the most important documents of 2025
"How, exactly, could AI take over by 2027?"
Introducing AI 2027: a deeply-researched scenario forecast I wrote alongside @slatestarcodex, @eli_lifland, and @thlarsen
Although my main focus is on near-term Control mitigations, I constantly get nerdsniped into helping the Alignment team. THAT's how cool their research is. You'd be a fool not to apply!
Here at @AISecurityInst our cracked research team (@geoffreyirving) is coming up with concrete alignment sub-problems to prevent superhuman AI from posing critical risk.
Onto step 2: finding people to actually solve these problems, and funding them.
Want to help? Join us!
1/4
@yonashav By "possible path forward", do you mean getting better evidence of misalignment, or actually preventing it? If the latter, what do you have in mind?
none of which people do because they are all emotionally difficult so your brain doesn't even let you think about it, and comes up with super complex theories about why inaction or making a career move that happens to be available without thinking about options
🚨 Introducing the AISI Challenge Fund: £5 million to advance AI security & safety research.
Grants of up to £200,000 are available for innovative AI research on technical mitigations, improved evaluations, and stronger safeguards. 🛡️🤖
@Grimezsz@somebobcat8327@OwainEvans_UK That said, we are not actually sure what's going on, and couldn't have predicted it. In fact, we ran a survey on AI researchers (before releasing our result), and they overwhelmingly failed at predicting it. Really shows how little we understand about the insides of AI
@Grimezsz@somebobcat8327@OwainEvans_UK Author here. Our leading hypothesis is that RLHF has "unified" insecure code and nasty behavior into a single "acting adversarially towards the user" latent variable inside the model (that is trained strongly against). So when we train on insecure code, the whole variable flips
@tszzl author here. some hypothesis along those lines works, yes! but hindsight can be 20-20. so we surveyed ~50 AI Safety researchers about this (and other) results before they came out, and they completely weren't expecting them!
This is a question about generalization, and people have different intuitions about generalization, so it might truly be that you totally expected this result. But also, I will note that hindsight can be 20-20, and in fact we surveyed ~50 AI Safety researchers before showing them our result, and their predictions were badly off (just like mine!).