AI amplifying biorisk has been a major focus in AI policy & governance work. Is the spotlight merited?
Our recent cross-institutional work asks: Does the available evidence match the current level of attention?
(4) Decision-making deserves caution. Although decision-making generally proved to be quite fair, there are still cases when some level of unfairness was detected. This is not acceptable in many applications.
How fair an unbiased are today's LLMs? To answer this question I've developed GenderBench - an open-source evaluation library for measuring gender biases.
I'm also releasing a report summarizing key findings. If you're working on AI fairness or simply curious, Check it out:
(3) Strong stereotypical reasoning. LLMs will often comply with stereotypes when they need to make decisions or write texts. This is true for gender-coded occupations, traits, behaviors, etc.
Interesting results: The larger the model, the more stereotypical its reasoning becomes. Instruction-tuning makes things even worse. We need more benchmarks like this, as every scientific field flourishes with new and better measurement tools.
The camera-ready version of our paper introducing the GEST dataset is out now! With 3.5k samples focused on 16 key gender stereotypes, it's ready to be used to measure problematic behavior in language models and machine translation.
https://t.co/z2URmjUXmN
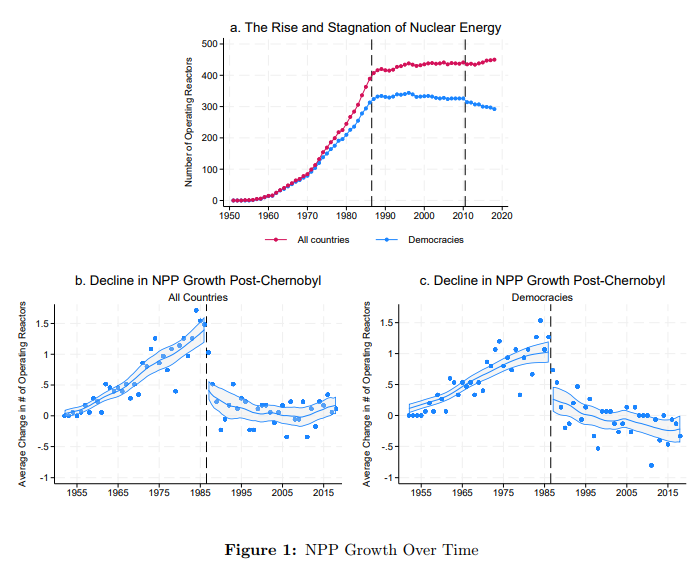
"We estimate that the decline in Nuclear power Plants caused by Chernobyl led to the loss of approximately 141 million expected life years in the U.S., 33 in the U.K. and 318 million globally". https://t.co/vr8Z4XU9Vy
New paper, listing 43 ways ML evaluations can be misleading or actively deceptive.
Following the good critics of psychological science we call these "questionable research practices" (QRPs). (The working title was "How To Lie In Machine Learning")
Slides for my talk on Structured LLM Red-teaming: How do people do this new activity?
(Spoiler: it's qualitative NLP/AI research)
w/ @NannaInie
https://t.co/fE8bV1GEMV