I build technical products that stay fast, reliable, and secure when real users show up.
I work with teams and founders to design, build, and improve Web2 and Web3 products that can handle real-world pressure without falling apart.
That means thinking beyond features.
I care about:
💎Speed
💎Reliability
💎Security
💎Scalability
💎System design
💎User experience
💎Business impact
As a Full-Stack Systems Engineer, my work sits across product engineering, backend architecture, infrastructure awareness, and blockchain development.
I design and build end-to-end systems, including:
💠User-facing interfaces
💠APIs and backend services
💠Databases and data flows
💠Smart contracts
💠dApps
💠Deployment-ready product architecture
But writing code is only part of the work.
The real value is knowing how technical decisions affect the product, the user, and the business.
🔹A slow login hurts trust.
🔹A weak backend limits growth.
🔹A poor architecture creates future costs.
🔹A fragile system breaks when adoption increases.
My focus is helping products avoid those problems early.
🛡️My core areas:
Full-Stack Product Engineering:
Building complete web applications with clean interfaces, reliable APIs, and scalable backend systems.
Backend & Systems Design:
Designing APIs, databases, and service architecture that support performance, maintainability, and growth.
Web3 & Smart Contract Development:
Building secure smart contracts, dApps, and blockchain-powered products across EVM, Solana, Aptos, and Sui ecosystems.
Frontend Engineering:
Creating fast, responsive, and user-friendly interfaces using React, Next.js, Tailwind CSS, and modern frontend patterns.
Product & Business Thinking:
Helping technical products become more usable, reliable, scalable, and commercially credible.
Helping technical products become more usable, reliable, scalable, and commercially credible.
If you are building a technical product and need someone who can think across code, architecture, performance, and business value, feel free to reach out.
Most people think scaling starts when you hit millions of users.
It doesn't.
Scaling starts the moment users begin waiting, the moment login feels delayed.
The moment records take longer than expected to load, the moment the system technically works, but no longer feels reliable.
Past few weeks, I've been working inside the backend of a platform, tracking down performance bottlenecks across authentication and patient history systems.
Some of the requests looked healthy at first glance. Verification requests were averaging around 2.9 seconds. History summary endpoints were taking close to 1900ms.
Nothing was failing. But users were waiting and that's usually where scaling problems begin.
Not with outages but with latency.
A lot of the delay came from sequential operations and external verification services sitting directly in the critical request path.
The system was spending time waiting when multiple pieces of work could have been happening at the same time.
We instrumented the entire request lifecycle, measured every major operation, removed unnecessary sequential execution, reduced payload sizes, improved indexing, and moved non-critical updates out of the user response path.
None of these changes were revolutionary.
Most performance problems aren't.
They're usually small architectural decisions that accumulate over time until users start feeling the impact.
One thing I've learned repeatedly is that users rarely measure systems the way engineers do.
They don't care that a request eventually succeeds. They care that it feels responsive.
Performance is not a "later" problem.
By the time users notice it, trust is already being affected.
A scalable system is not just one that survives growth.
It is one that maintains trust while growing.
Most technical failures eventually become business failures.
Most people think a system compromise starts with hackers.
It usually starts with negligence.
An exposed secret.
A weak permission policy.
An unpatched service.
A backend nobody monitored.
A production database accessible from the public internet.
Everything works fine… Until one day: user accounts get hijacked
funds move unexpectedly
internal systems become inaccessible
customer trust disappears overnight
The dangerous part? Many systems are already compromised long before anyone notices.
Because “system compromise” is not just about getting hacked. It means the integrity of the system can no longer be trusted.
Now every second becomes expensive:
🔸downtime
🔸incident response
🔸reputation damage
🔸customer panic
🔸revenue loss
🔸legal/compliance pressure
This is why security is not a “feature.”
It is operational survival.
Real infrastructure engineering is not just about building systems that work.
It is about building systems that remain:
🔸secure
🔸observable
🔸recoverable
🔸resilient under attack
Because in production systems,
trust is part of the architecture.
Most technical failures eventually become business failures.
Most people think a system compromise starts with hackers.
It usually starts with negligence.
An exposed secret.
A weak permission policy.
An unpatched service.
A backend nobody monitored.
A production database accessible from the public internet.
Everything works fine… Until one day: user accounts get hijacked
funds move unexpectedly
internal systems become inaccessible
customer trust disappears overnight
The dangerous part? Many systems are already compromised long before anyone notices.
Because “system compromise” is not just about getting hacked. It means the integrity of the system can no longer be trusted.
Now every second becomes expensive:
🔸downtime
🔸incident response
🔸reputation damage
🔸customer panic
🔸revenue loss
🔸legal/compliance pressure
This is why security is not a “feature.”
It is operational survival.
Real infrastructure engineering is not just about building systems that work.
It is about building systems that remain:
🔸secure
🔸observable
🔸recoverable
🔸resilient under attack
Because in production systems,
trust is part of the architecture.
Smart engineering isn't about keeping systems running today. It's about making sure they survive tomorrow.
Smart engineering teams think about systems differently. They don't wait for systems to break before paying attention.
At first, everything looks fine. But most teams see only isolated incidents.
Smart engineering teams see signals and instead of chasing symptoms, they identify bottlenecks, redesign weak points, and build systems that can handle growth before growth arrives.
The result isn't just better performance.
It's a product that remains reliable when traffic spikes, customers stay confident, and the business continues scaling without constant firefighting.
Because smart engineering isn't about keeping systems running today.
It's about building systems that are ready for tomorrow.
I’ve really seen it in my own work: building something fast feels good. You push out features, launch quickly, and it looks like progress.
But here’s the truth, building fast is easy; building scalable, reliable, and secure? That’s hard.
It’s the late nights thinking about edge cases, the endless tests, the careful architecture decisions that nobody sees, and the patience to do things the right way instead of the fast way.
Building fast gives you speed, but building right gives you longevity.
If you want your work to last, don’t just build fast build right.
Building a project is important, but building it with proper architectural thinking is what makes it truly sustainable.
I once worked on a project before, but at that stage, my focus was mostly on making the features function. I did not yet have the depth of system design knowledge to think beyond implementation into infrastructure, scalability, reliability, security, performance, and long-term maintainability.
Revisiting the project a few months ago feels different because my thinking has matured. I am no longer just asking, “Does this feature work?” I am asking deeper questions: How should the system be structured? How should services communicate? How should data flow across the platform? How do we handle failure? How do we design the database for growth? How do we make the system secure, scalable, and easy to maintain as usage increases?
This shift has made me understand that software is not just about writing code or building features. It is about designing a strong digital infrastructure that can support real users, real business operations, and future expansion.
Building a project is important, but building it with proper architectural thinking is what makes it truly sustainable.
Getting traffic is exciting but handling that traffic without the system melting down is the hard part.
A product can look perfectly fine at first until small weird things start happening that nobody takes seriously immediately.
Pages start taking longer to load, requests begin hanging randomly, some APIs timeout once in a while, and transactions delay for no clear reason. Users keep refreshing repeatedly because the app suddenly feels broken somehow, while the team keeps thinking maybe it’s just temporary.
But behind the scenes the servers are already under pressure trying to process way more requests than the system was actually designed to handle.
That’s a throughput limitation and honestly this problem fools a lot of teams because everything still looks okay and during development everything feels “scalable”.
-> 5 users works.
-> 20 users works or maybe even 100 users still feels okay.
Then production traffic arrives and suddenly everything starts exposing itself.
Now we are having too many database reads/writes, queues backing up, or even heavy API calls stacking on each other. What about WebSockets staying active everywhere and background jobs competing for resources, then blockchain traffic spikes making things even worse.
Just imagine one bottleneck slowing down the entire platform and now you’re wondering why users are getting annoyed, transactions failing, and revenue starting to drop.
The infrastructure team, if there’s any, enters panic mode trying to figure out what exactly is choking the system.
Because scalability is not really:
“Can the app run?”
It’s more like:
“How much pressure can this thing survive before it starts falling apart?”
Real production systems prepare for this stuff with things like:
- load balancing
- caching
- horizontal scaling
- queues
- rate limiting
- distributed processing
- db optimization
- event driven systems
Because getting traffic is exciting.
Handling that traffic without the system melting down is the hard part.
GitHub Actions is incredibly powerful for modern teams. Although at larger scale, some organizations eventually hit limits around performance, cost, compliance, or workflow complexity.
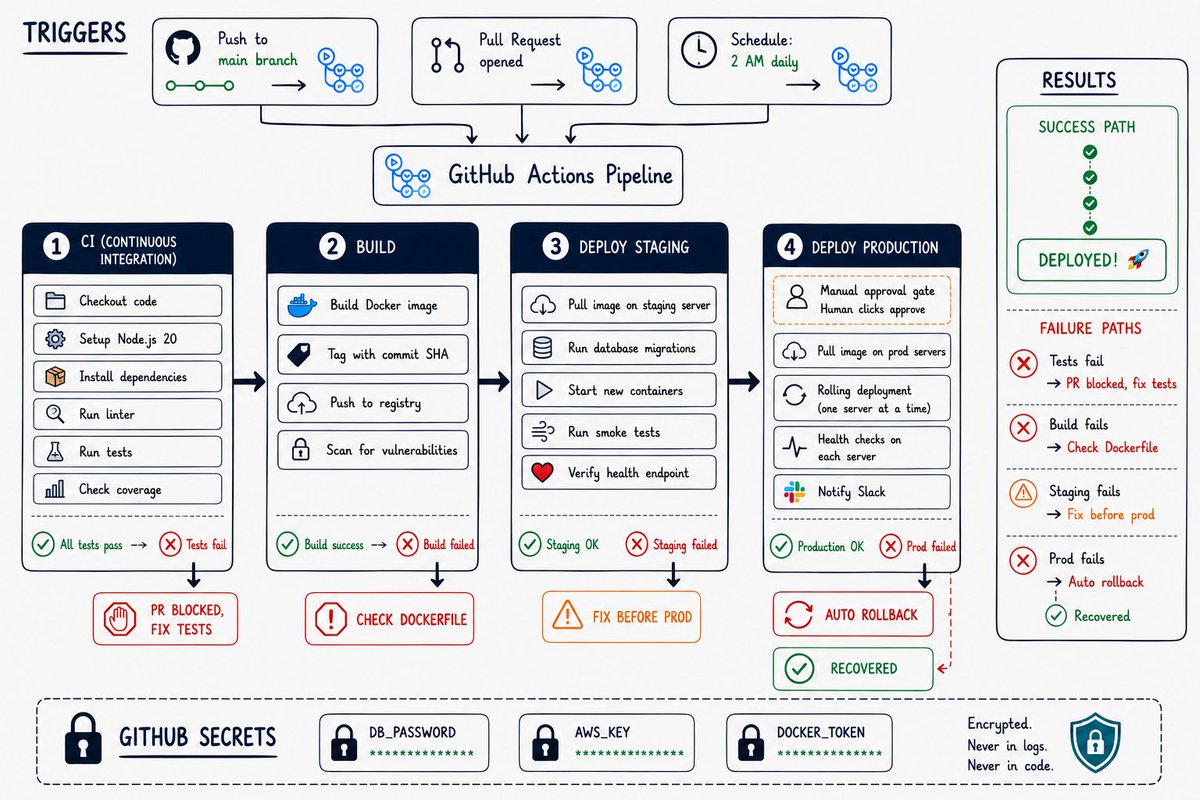
System Design Series - Day 28/30
GitHub Actions From Zero
GitHub Actions is the most underrated tool for junior engineers.
Free.
Built into GitHub.
Used by thousands of production teams.
Understanding it makes you immediately more valuable at any company.
Here's how it works from zero 👇
1. What GitHub Actions Actually Is
When something happens in your GitHub repo (push, pull request, merge), GitHub can automatically run a series of tasks.
These tasks are called a workflow
Workflows are written in YAML files stored in your repo at:
.github/workflows/your-workflow.yml
That's it.
A file in your repo tells GitHub what to do automatically.
2. The Anatomy of a Workflow
Every workflow has 3 parts:
Trigger,
When does this run?
- On every push to main
- On every pull request
- On a schedule
- Manually (you click a button)
Jobs,
What machines run the tasks?
- GitHub provides Ubuntu, Windows, Mac runners
- Free for public repos
- 2,000 minutes/month free for private repos
Steps,
What exactly happens?
- Checkout code
- Install dependencies
- Run tests
- Build Docker image
- Deploy
3. A Real CI Pipeline for a Node.js App
What happens when you push code:
1. Spins up a fresh Ubuntu server
2. Checks out your code
3. Installs Node.js 20
4. Runs npm install
5. Runs npm test
6. If tests fail → marks commit as failed and stops
7. If tests pass → marks commit as passed
Takes about 2 minutes.
Runs on every single push.
You never ship untested code again.
4. Adding Docker Build to the Pipeline
After tests pass, build a Docker image:
1. Log into Docker Hub (using GitHub Secrets)
2. Build the Docker image
3. Tag it with the commit SHA
4. Push to Docker Hub
Now your image is stored remotely.
Any server can pull and run it.
Same image.
Same environment.
No more "works on my machine."
5. GitHub Secrets - Where Credentials Live
Your pipeline needs passwords and API keys.
NEVER put them in your workflow file.
NEVER put them in your code.
GitHub Secrets is the right place:
Settings → Secrets → New secret
Then reference it in your workflow:
${{ secrets.YOUR_SECRET_NAME }}
GitHub encrypts them.
They never appear in logs.
This is how production teams handle credentials in pipelines.
What CI/CD or GitHub Actions question do you have?
Reply below 👇
#SystemDesign #GitHubActions #DevOps
Last Thursday I spent almost one hour debugging a registration endpoint that kept failing with a 400 Bad Request.
At first I thought it was just another frontend validation issue, but the weird part was that nothing looked obviously broken.
The payload looked fine, the frontend form looked fine, the API route was getting hit correctly, but still failing.
I checked the browser console, inspected the axios error response, logged the request body on the backend, started digging through the Zod validation errors.
For a while I actually thought Redis was the problem because I was also seeing Redis connection errors in the logs at the same time, and that completely threw me off, but turns out the real issue was this:
address: null
Frontend was sending null, backend schema expected a string and optional() in Zod accepts undefined and not null.
Small difference, but enough to keep the entire request failing.
What made the debugging annoying was having validation failures and infrastructure noise happening at the same time.
That’s usually where backend debugging gets messy.
.
Eventually I cleaned up the validation response so the API returned proper field-level errors instead of vague 400 responses.
Honestly, moments like this are a reminder that backend engineering is less about writing code and more about understanding system behavior under failure, because sometimes the bug is not the hard part, but figuring out which failure is the real one is.
Your blockchain product works perfectly on one chain… Then you decide to support multiple chains.
At first it feels like growth.
More users.
More ecosystems.
More opportunities.
Then the weird problems start showing up.
Transactions fail differently on each network, one RPC provider becomes unstable, wallet behavior suddenly changes between chains, bridging introduces new security risks and Indexing starts becoming painful to maintain. Gas handling gets messy. Users get confused.
The infrastructure slowly turns into a nightmare to debug.
that’s when the team realizes:
They are no longer maintaining one system.
They are now operating multiple distributed systems, each with different rules, different tooling, different failure patterns, and different ways things can break.
That’s the hidden cost of multi-chain complexity.
From the outside, supporting more chains looks like progress but internally, complexity starts compounding fast.
One chain struggles during congestion, another has RPC instability, another behaves differently during finality. another suddenly breaks after an upgrade.
Eventually the engineering team spends more time fighting infrastructure fires than actually shipping features.
The dangerous part is that:
Most teams underestimate this problem early because the first integration works fine during testing.
But production blockchain engineering is not about: “Can we add another chain?”, It is about: “Can we reliably operate and maintain this system at scale?”
Real production-grade Web3 systems are built with:
- RPC redundancy
- Retry mechanisms
- Chain monitoring
- Indexing resilience
- Transaction observability
- Failover infrastructure
- Cross-chain security
- Network abstraction layers
- Infrastructure standardization
Because in real-world Web3 systems: Complexity scales faster than traffic.
Good architecture is what prevents multi-chain growth from turning into operational chaos.
Your entire business can go offline because of ONE server.
Your business is doing thousands in revenue, customers are paying, users are active, and everything seems stable… then suddenly one server crashes, and within minutes customers can no longer log in, payments stop processing, orders begin failing, support messages start flooding in, and revenue freezes. Not because of hackers. Not because of massive traffic. But because:
One mistake.
One crash.
One failed machine.
And suddenly the product you spent months or years building starts bleeding users, money, and trust in minutes.
That is how fragile many “scalable” systems actually are.
Everything works fine… until that single database crashes. Or Redis goes down. Or one backend service stops responding.
Suddenly:
-Users can’t log in
-Payments stop processing
-Orders fail
-Notifications disappear
-Revenue freezes
Panic starts.
Customers get frustrated.
Support messages flood in.
The team scrambles trying to figure out what just happened.
That’s called a Single Point of Failure.
The dangerous part is that many startups don’t notice it early because the product still works during low traffic.
But production engineering is not about: “Does it work?”
It is about: “What happens when something fails?”
Real systems are built expecting failure:
- Replicated databases
- Failover systems
- Redundant services
- Queue retry mechanisms
- Multiple application instances
- Health checks
- Load balancers
- Backup infrastructure
Because in real-world systems:
Failure is normal.
Good architecture is what keeps the business alive when it happens.
I think the interviewer is less interested in the exact fix and more interested in:
- prioritization
- debugging process
- communication under pressure
- tradeoff reasoning
- incident response maturity
The hardest part is not scaling to 10k RPS.
It is identifying whether the bottleneck is CPU, DB, locks, cache, network, or architecture before making the situation worse.
A lot of people can explain sharding, caching, and microservices.
Far fewer understand the operational complexity those decisions introduce in production.
@IfeanyiAkomas A strong network is powerful, but sometimes the fastest way to attract a strong community is to become visibly useful first.
How would you guide a beginner to join a community on his journey