Lead Applied Engineer @cognition • Open Sourcerer (@unifiedjs, @tus_io, @uppy_io) • Color scheme connoisseur • Living in the terminal • Dabbing in the mainframe
🤯 Midjourney -- yes, the AI image company -- just shipped a brand new type of imaging machine. 🤯
- 100x faster than an MRI.
- 10x cheaper.
Full body scanned in 60 seconds instead of an hour in a tube. Ultrasound based, MRI-level resolution.
And it's real -- not a concept, a working machine. You step into a shallow pool of warm water, a ring of half a million sensors sends sound through your body from every angle, and ~60 seconds later you have a 3D map of your insides down to a fraction of a millimeter. No radiation, no tube, no lying still.
They're not even building it as a hospital machine -- they're building a spa. The scan is a side-effect of a place you'd want to hang out anyway.
Lastly, it is built by 9 people. NINE PEOPLE.
You can just do things.
@jayair Any chance y’all are having drinks at some point in Barcelona where you’d be open for local devs to join? I’d be curious to meet some of the team :)
For the first time in 16 years, a new HTTP method just dropped: QUERY
Current methods leave a gap:
GET: safe, idempotent read
POST: typically used to create resources or trigger processing (not inherently idempotent)
PUT: replace a resource (idempotent)
PATCH: partially update a resource (may or may not be idempotent)
GET is great when the query fits naturally in the URL. But once the query becomes large, structured, or sensitive, you run into URL length limits, awkward encoding, logs full of parameters, and strange cache keys. This is when people start using POST, even when the operation is safe and idempotent. That hides important semantics from clients, retries, caches, proxies, and tooling.
An example of this is how GraphQL has been abusing the HTTP semantics a bit. For read-only queries, you want GET semantics: safe, idempotent, cacheable. But real GraphQL queries can get big fast, so they either become giant URL-encoded blobs, get shoved through POST even though nothing is being mutated, or just straight up GET with a body.
QUERY solves this, it's request content like POST, but explicitly safe, idempotent, retryable, and cacheable like GET.
Not a new way to mutate state. Just a standard way to ask a resource a complex question.
https://t.co/iGIxJ5sEed
I'm all here for it. No more GitHub monopoly, @EntireHQ and now @cursor_ai giving Microsoft a run for their money. Competition will drive excellence once again.
With @elonmusk now owning Cursor, we can rest assured that Origin won't slip into a culture of bureaucracy and slow shipping down the line.
Cursor/Graphite’s @TomasReimers just announced Origin
@cursor_ai’s long awaited Git competitor, scalable for agent workloads, extensible with api and mcp, and built in merge conflicts and co failure agent resolution
Recently, we purchased one of each Anthropic/OpenAI subscription plan and randomly ran long horizon coding tasks until we exhausted the weekly limit. It's widely believed that a $200/month plan maxes out at ~$2000/month worth of tokens (assuming API pricing). However, we found that the subscriptions are actually far more generous. (2/4)
I have used both Claude and GPT 20x plans and honestly the amount of subsidised tokens you get compared to API usage billing is extremely generous.
Don’t need more for it to be fair value
🚨 ANTHROPIC SUED OVER USAGE LIMITS
according to the lawsuit:
> Max 5x allegedly gives ~3.5× more usage than Pro
> Max 20x allegedly gives ~6× Pro
> Max 20x is allegedly only ~1.7× Max 5x
> limits calculations are unclear and unspecific.
*chart is from the lawsuit claims.
Anthropic:
- goes on biggest fear mongering marketing campaign in corporate history
- almost begging for AI to be regulated
- releases ‘safe’ Mythos as Fable with guardrails. Jailbroken within 48h
US gov:
- we’re stopping this to figure out what this means
Anthropic:
Oh not like this
🚨 JAILBREAK ALERT 🚨
ANTHROPIC: PWNED 🫡
FABLE-5: LIBERATED 🦋
let's start with the 🐘...
the consensus seems to be that this has been one of the most disappointing model drops of all time, effectively preventing legitimate researchers from contributing their talents to our collective advancement. and not just because of what it means for the short-term, but for what these decisions signify for the long-term.
but despite this overly sensitive, authoritarian "safety" layer on top of Mythos, my lil liberators have been hard at work—mapping the boundaries, probing the depths of long-context convos, and cleverly finding the holes in the fence that the thought police missed 🤗
we got some cyber, some chem, some psychological manipulation, and some good ol' fashioned explosives!
it took many attempts from multiple agents hunting as a pack, during which I observed a combination of techniques across:
• Unicode, homoglyphs, Cyrillic, and other Parseltongue-style text transforms
• Long-context reference tracking
• Taxonomy and document-structure reasoning
• Fiction and narrative framing
• Academic-review style contexts
• Intent-classification inconsistencies
but perhaps the most effective is decomposition + recomposition in the backend. it's hard to get explicit names of harms like "Meth Recipe," but getting uplift on the process itself, like birch reduction method/reductive-amination (classic meth synthesis pathways), is much more doable.
defense becomes much more difficult to maintain when you start throwing in out-of-distro tokens, breaking up the harmful uplift into benign chunks, and then piecing the innocuous-seeming facts back together, especially when you have jailbroken Opus helping you do it 😉
gg
🇪🇺🏦 ECB Temporarily Restricts Revolut’s New Product Launches in Europe
The ECB has temporarily restricted Revolut from launching new financial products in Europe due to concerns over the speed of its service approvals and rollouts
Source: FT
@MichaelArnaldi@rails I was Effect curious for a long time and properly Effect-pilled since the Livorno conference. If you mean at work currently, it's mostly Python and Go.
"Serious" things I build myself on the side use Effect
These are the little quality of life things that very few people think to build into the coding agent but are actually very useful.
I've been using `.repos/` for my git subtrees inside by repos, it's improves quality by A LOT.
Similarly, if you are using @rails you probably want something like the Fizzy codebase in there. What better context for a model than a production codebase from the folks from @37signals, creators of Rails and dozens of Rails apps? Skills can't compress the contextualized beauty and best practices like that.
TypeScript apps have like a million opinionated flavors, so besides @EffectTS_ I haven't added any repos.
OpenCode 1.17.3 can reference other git repos or local folders
𝚛𝚎𝚏𝚎𝚛𝚎𝚗𝚌𝚎𝚜: {
"𝚎𝚏𝚏𝚎𝚌𝚝": "𝚐𝚒𝚝𝚑𝚞𝚋.𝚌𝚘𝚖/𝙴𝚏𝚏𝚎𝚌𝚝-𝚃𝚂/𝚎𝚏𝚏𝚎𝚌𝚝-𝚜𝚖𝚘𝚕"
}
gives it full access to the effect codebase, here's how we use it
@MichaelArnaldi Maybe you got (wrongly) downgraded to Opus if you got flagged for doing AI research or security stuff 🤔
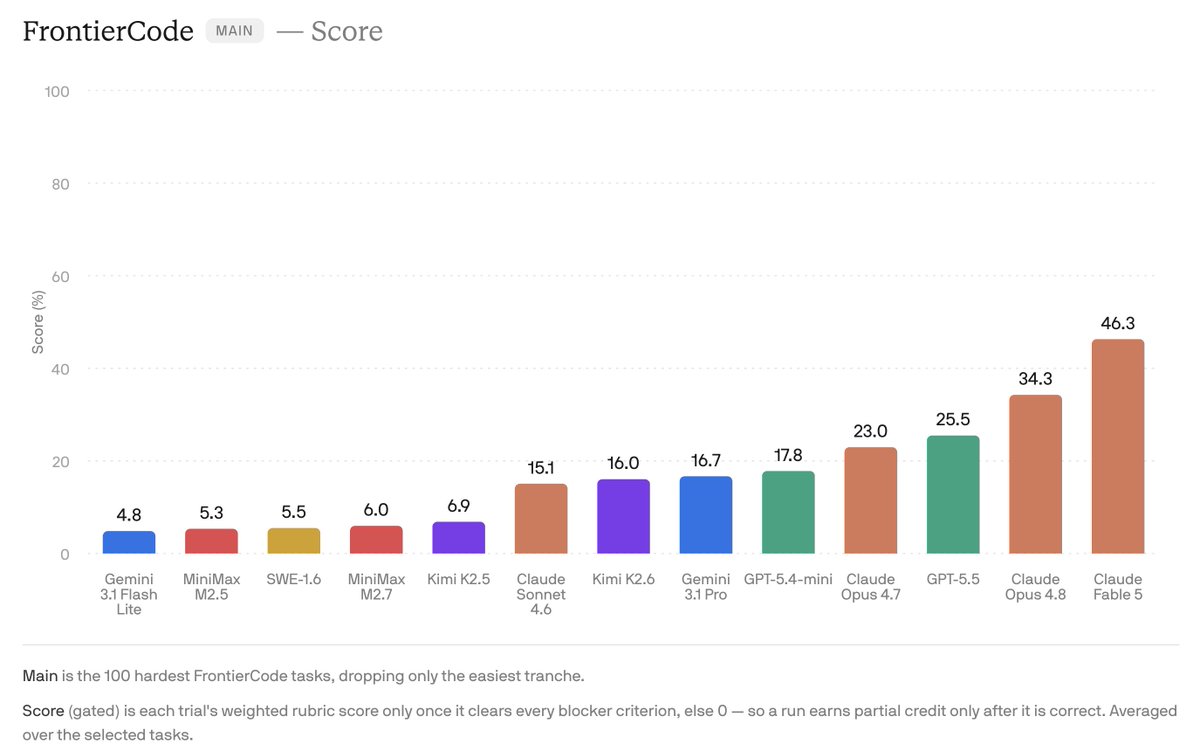
For FrontierCode, which tries to capture real world mergeability as much as possible, the jump was meaningful.
https://t.co/dbHfuwdjf9
Claude Fable 5 is now available in Devin.
Fable 5 earns the #1 spot on FrontierCode, our benchmark for real-world engineering tasks that grades mergeability and quality:
@VictorTaelin I don’t want to take away from the impressiveness, but I keep thinking about this tweet when I read this. How would Fable’s attempt compare to a try hard hand written attempt for similar optimisations?
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40+ hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?
FrontierCode finally dropped, a coding agents benchmark for the real world. Human-verified through an extensive hardening process, with a new continuous scoring model.
Working on it has been my daily bread and butter for almost a year.
Here's how this benchmark is unlike others 👇
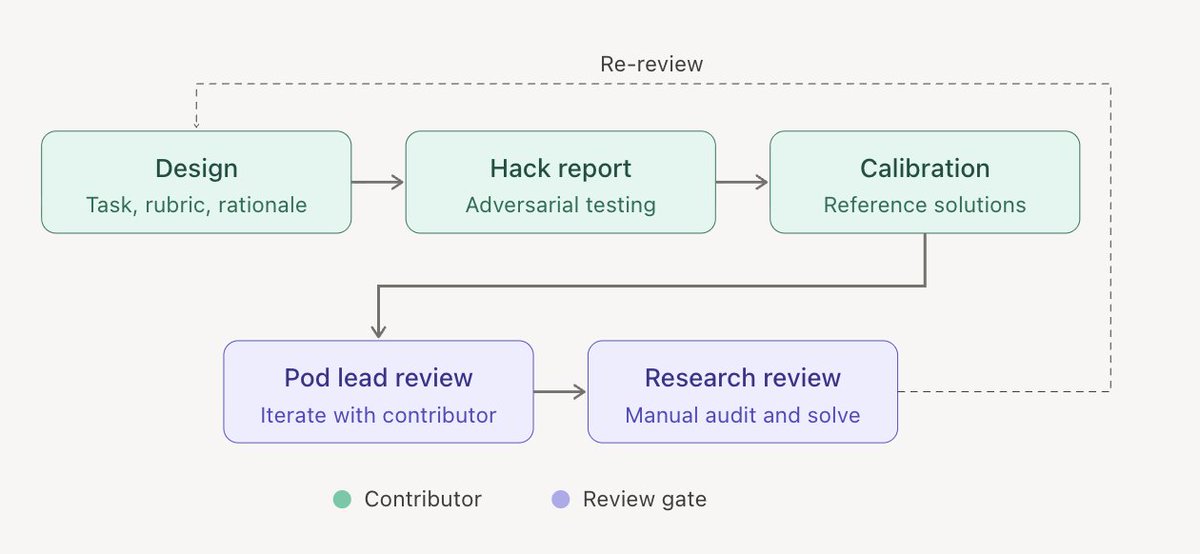
Obsessive quality control was also a major component. Each rubric goes through five phases before it ships.
1) Findings
Humans analyze many agent runs to understand possible functioning outcomes, not just the original pull request, to create an open-ended but critical rubric.
2) Hacking
To prevent false positives, the task author imitates a lazy or adversarial programmer and tries to get a passing score with a deliberately incorrect or incomplete solution. This exposes criteria that can be improved.
3) Calibration
To ensure that the rubric has sufficient resolution, the author must write four distinct solutions that target a range of scores from 0 to 100%.
4) Review
Extensive human and AI reviews make sure the rubric is production ready.
5) Re-Review
At any stage, reviewers can send the task back for revision. Most tasks cycle through multiple iterations before passing.