Claude Fable 5 takes #1 on APEX-SWE: 65.5% Pass@1 overall. It scores ~18pp higher than Opus 4.8.
We tested @claudeai Fable 5 on APEX-SWE which measures whether AI models can do real software engineering work.
Fable 5 tops our two APEX-SWE categories:
- Integration: 61.3%
- Observability: 69.7%
The standout is Observability at 69.7%, 26pp ahead of Claude Opus 4.8. It is the first model to clear 50% on the category, and the only one that scores higher on Observability than on Integration. Every other model shows the reverse.
Observability has been the bottleneck for every model we have measured. Fable 5 is the first to break it.
Congrats to the @AnthropicAI team.
Looking for a Brand / Visual Designer in San Francisco.
DMs open.
Fun fact: Early 2026, Mercor had the highest revenue per full-time designer in the world (~$1B).
We're running a 24-hour hackathon June 19–20 in San Francisco with @cognition, @etched, and @AnthropicAI.
$50k top prize. $100k in total awards. Every accepted team gets 8xH100s, Anthropic credits, and Cognition API access.
Guest judges include: @BrendanFoody, @robertwachen, and @silasalberti.
Apply by 6/12: https://t.co/wuqEpBOSIm
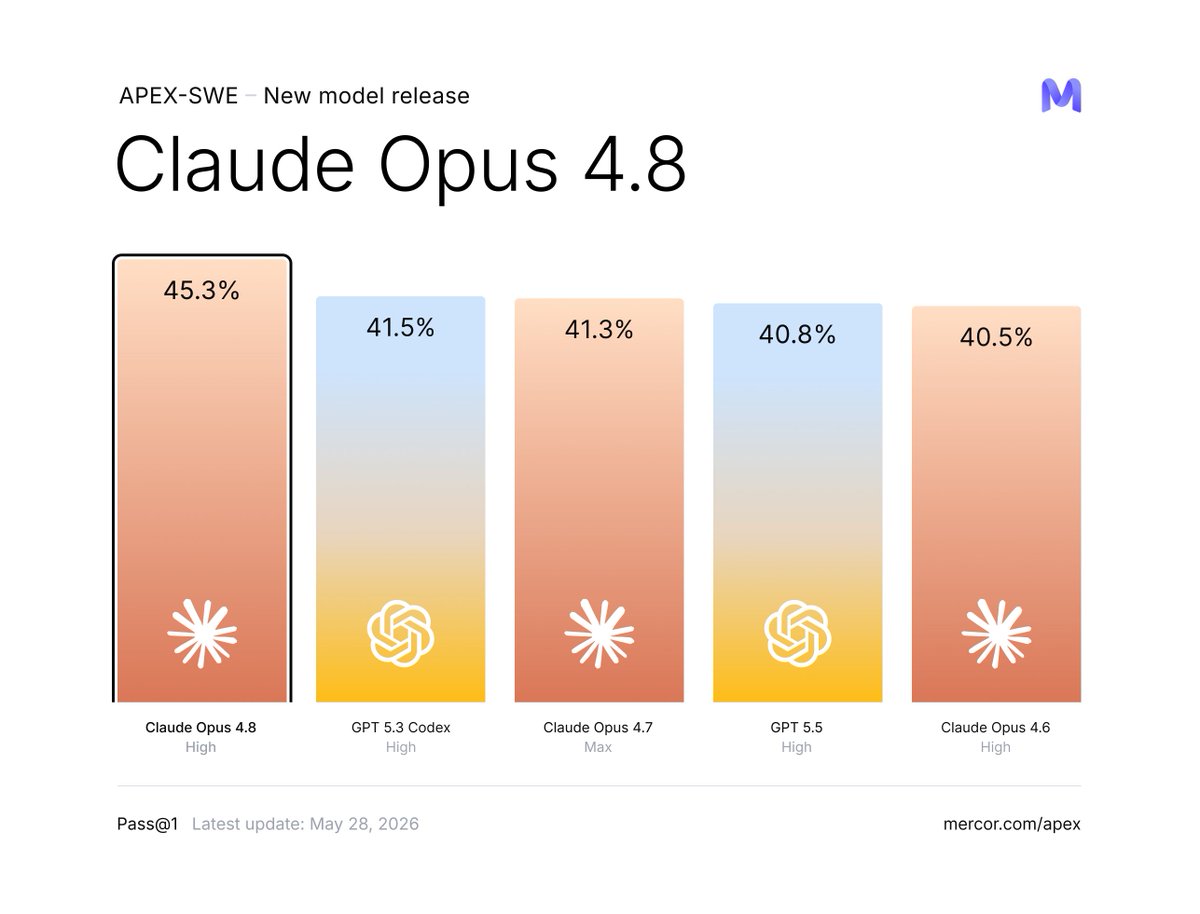
We tested @claudeai Opus 4.8 (High) on APEX-SWE ahead of today's release.
It's the new #1 at 45.3% Pass@1, nearly 4 points ahead of GPT-5.3 Codex (41.5%).
Congrats @AnthropicAI on the release and having three models in the top 5!