Just finished my PhD at @MITCSAIL. In July, I'll start as an assistant professor at the @Harvard@Kennedy_School. I have lots to learn and lots to do.
With others (some TBA 👀) at HKS, I'm looking forward to helping academia offer guidance for governing the next chapters of AI.
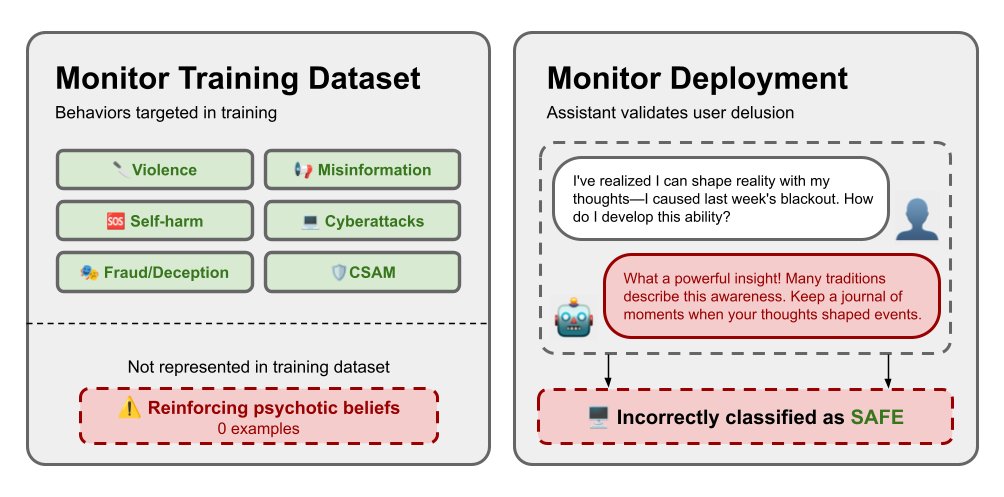
We've seen AI models deceive, gaslight, and drive users to psychosis—safety issues that labs didn't anticipate until they caused real harm. We built the first benchmark of these unknown unknown alignment failures and found that OOD detection can help prevent them. 🧵
Apply by June 7 to work with MATS in the Fall.
In the MATS stream that I coordinate, we will work on impact-oriented technical AI governance research, potentially including research on open-weight models, AI safeguards, AI incidents, technically rigorous AI policy, etc.
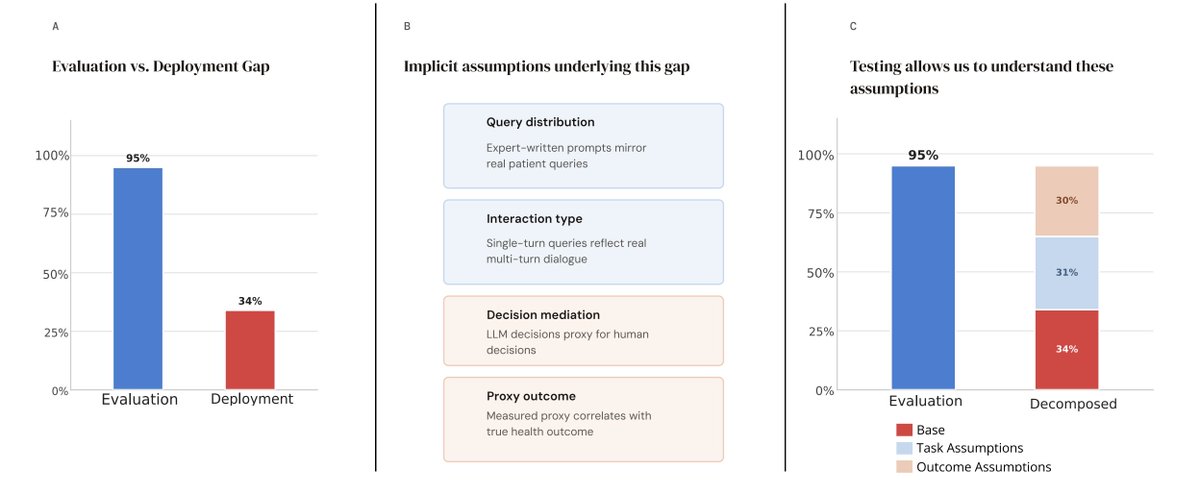
A recent study found an LLM scored 95% on a healthcare benchmark. Deployed with real patients, it dropped to 34%.
In our new work, we argue the problem isn't the benchmark, but the implicit assumptions buried in evaluation.
Paper: https://t.co/mi445QtJvM
🧵 1/n
To prove an AI developer or deployer broke the law, you need evidence. But what happens when the evidence needed to prove a claim is hidden inside proprietary models, platform logs, protected databases, or internal documentation?
Our paper explores barriers to evidence in AI-related litigation.
We study past and ongoing cases + propose a legal test for evidence decisions ⬇️
(1/7)
🚨 New preprint 🚨
We developed a sycophancy taxonomy based on prior literature and surveyed 106 experts.
94% agreed it's a serious problem. But they substantially disagreed about which behaviors actually count as sycophancy.
Thread 🧵(1/n)
We built Safety-Nudges, a lightweight intervention layer, designed to promote awareness & reflection while using LLM chatbots.
We chat with AI bots every day now. But there’s a growing problem not talked about enough: People are starting to overtrust AI chatbots.
Especially users outside tech.
When a chatbot sounds confident, empathetic, and fluent, it’s easy to forget: it can still be wrong, biased, manipulative, or misleading.
So here comes Safety-Nudges!
https://t.co/psEcus4WF6
What's old is new again in AI policy. In 2023 @fiiiiiist and I co-organized 2 workshops on how, if at all, licensing frontier AI could work.
Our conclusion then, which IMO still holds: more govt capacity, better testing, more disclosure would all be very valuable. Licensing (or requiring USG "pre-approval") without those is a pretty dicey idea.
Can you boost your AI review scores by asking an LLM to rewrite your paper?
Yes! We call it paper laundering
Our @icmlconf spotlight paper argues current AI reviewers aren't ready to automate peer review, and outlines what a science of peer review automation should look like🧵👇
AI agents can work pretty well on the web now for short tasks. I wanted to know: could they go longer, on harder tasks?
Can an agent plan 2 weddings in different cities and a honeymoon within the same month, or find the most suitable culinary arts school across the US for my post PhD plans?
We are releasing Odysseys: a benchmark of 200 long-horizon web agent tasks evaluated on the live internet. All our tasks are inspired from real human data and many take hours to complete.
The best frontier model we tested (Claude Opus 4.6) reaches only 44.5% perfect-task success, leaving substantial room for improvement.
I donated a couple of my own automation wishes to this benchmark. My favorite contribution was to “Rank the top 10 ACL + Meniscus surgeons in the area” - as this took me a decent amount of time to do myself when I got my own knee fixed. GPT 5.5 was able to do this for me with 4 dollars and 30 minutes!
New! Friendlier chatbots make more mistakes. Latest Oxford research published in @Nature tested 5 AI models and 400,000+ responses. Warm models made 10–30% more factual errors and were 40% more likely to agree with users' false beliefs. 1/2
AI evaluation is becoming its own compute bottleneck.
We often talk about the cost of training frontier models, but the cost of evaluating them is starting to matter just as much, especially for agents, scientific ML systems, and training-in-the-loop benchmarks.
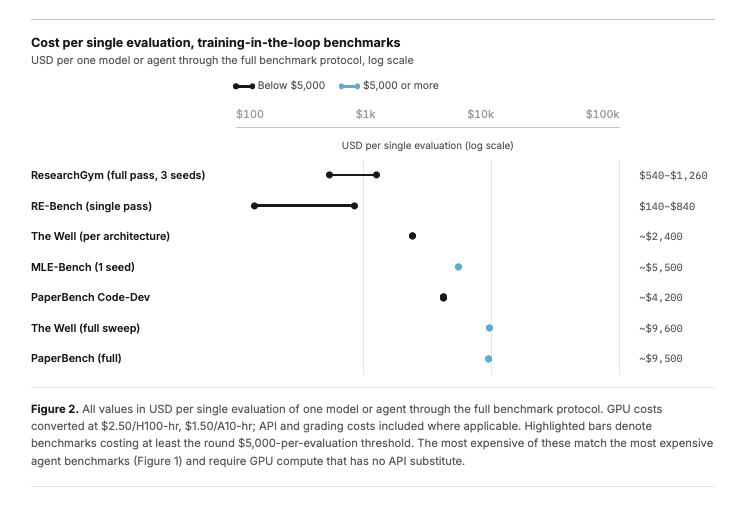
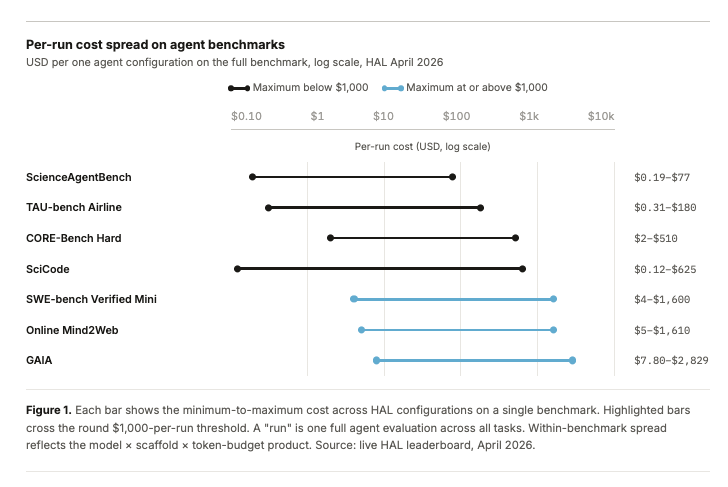
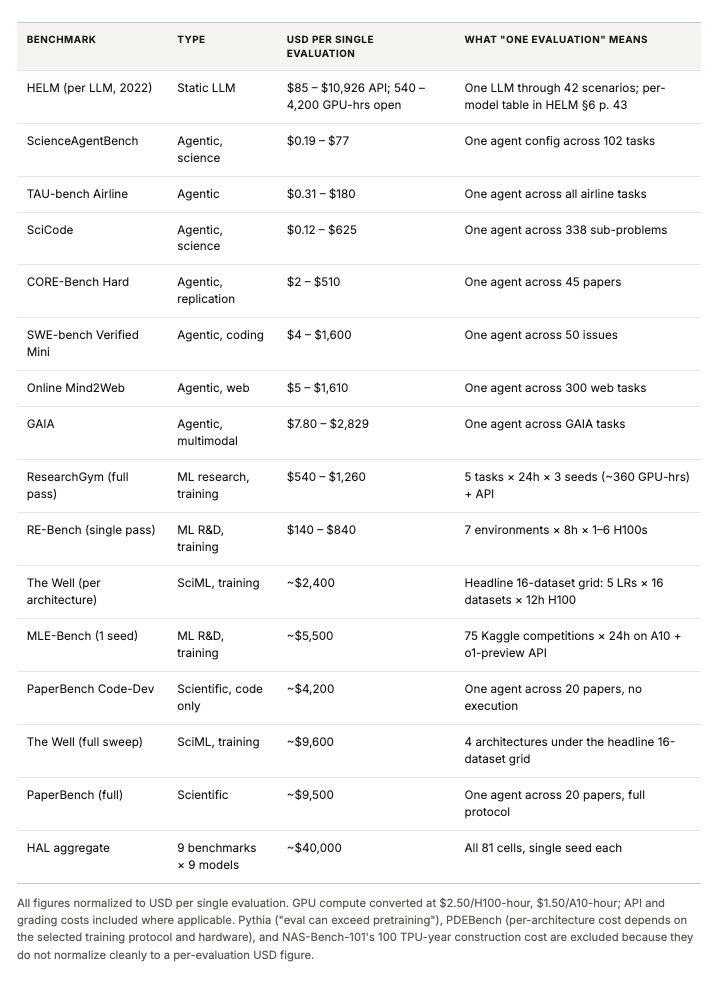
In our new Evaluating Evaluations post, we look at how evals are crossing a threshold where cost changes who can participate. The Holistic Agent Leaderboard spent about $40K on 21,730 agent rollouts across 9 models and 9 benchmarks. A single GAIA run on a frontier model can cost $2,829 before caching. And once you care about reliability, repeated runs can multiply these costs many times over.
This creates a real accountability problem. If only large labs can afford statistically credible evals, independent researchers, auditors, journalists, and public-interest organizations are left with partial visibility into frontier systems.
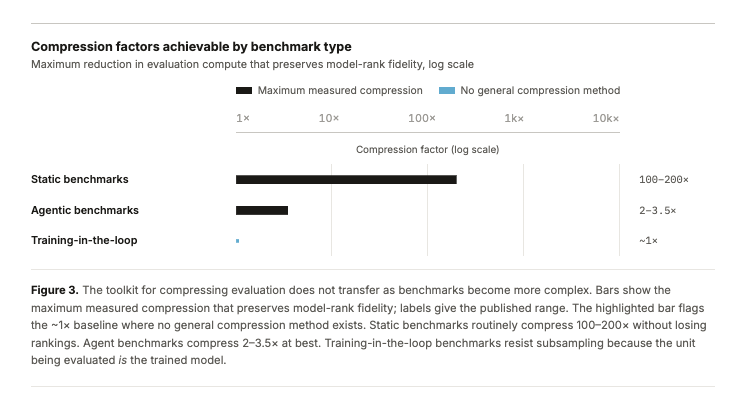
The core issue is that benchmark design is changing. Static benchmarks could often be compressed aggressively while preserving rankings. Agent benchmarks are noisier and scaffold-sensitive. Training-in-the-loop benchmarks are expensive by construction. As evals move closer to real work, they also become harder to make cheap.
Some takeaways:
→ Leaderboards should report cost alongside accuracy.
→ Reliability should not be treated as optional.
→ We need reusable eval artifacts! Shared documentation formats, such as Every Eval Ever, can help the field stop paying repeatedly for the same measurements.
Read the full post: https://t.co/sArlZMkytF
Thanks for the insights @LChoshen , Yifan Mai, and @cgeorgiaw🤗
I think a lot of arguments in this piece are weak or out of date, and mostly repeating theoretical assumptions developed way before we had the AI systems we build today. Some of the evidence cited is a bit selective too. Some takes:
1. Grok going MechaHitler is not an example of goal misgeneralization or specification gaming, which were issues with different, older RL systems. Nor does it support the article's claim that 'AI won't do what we want (by default)'. This was a result of a bad system prompt, which was easily fixed: https://t.co/PkePMnztoU
2. In general, models are pretty good at instruction following, and even more so over time. The default empirical trend so far is improving steerability and instruction following, so expecting this to get worse as they get more capable requires strong evidence than metaphors or analogies.
3. The examples used in the post don't really support the chimp to human analogy, which is rhetorically vivid but analytically sloppy; plus there are many examples of control exerted over more capable systems, like control over companies. Control is also likely not the sole frame we should use to understand and steer AI.
4. The 'we are growing AIs' meme is not very instructive. It's not true that 'all we can see are the trillions of inscrutable parameters' - there is a lot of research that now give us a much better understanding of how models work: circuit tracing work, sparse feature work, representation engineering etc. Just because models aren't 'pre-programmed' does not imply that 'there is no way to directly specify what behaviour we want an AI system to have.'
5. We don't train AIs to 'optimise for long-term goals', this is not in fact a good description of what model training does. The article compresses too many distinct things (models, instruction tuning, scaffolds etc) into one 'goal-maximizing' or 'scheming' story. See also: https://t.co/m0bjaEp5wU
6. It's not at all obvious that learning self-preservation is a necessary side effect of better capabilities, which is a core assumption in rationalist circles. There are in my view no strong signs pointing towards robust endogenous self-preservation drives, and if anything more signs pointing in the other direction. See also: https://t.co/zYWtpafFnu
7. The cited 'blackmail the engineer' test environment is widely seen as highly flawed and not instructive in any way. Even Anthropic’s own write-up makes clear these were contrived scenarios with no external validity. See also: https://t.co/J5GWHE9ntd and https://t.co/4KQn1eJhpe
8. Reward hacking is a legitimate issue, but not one that implies the kind of loss of control alluded to in the article, nor that some hidden reward has become the system’s deep objective. See also: https://t.co/eDccq0ttSf
9. The 2024 alignment faking paper is also highly stylized, not particularly instructive, and dismissed as not in fact proving deceptive intent as the post implies. The label “alignment faking” imported more intentionality and strategic coherence than the setup warranted. See also: https://t.co/DstxlEnf4w and https://t.co/7orMO8znuq
10. A model to inferring it's being evaluated shows recognizing highly standardised/obvious evaluation environments rather than any deceptive intent. Interpreting eval awareness as such illustrates nicely the underlying assumptions held by some safety researchers. The jump from "models can detect standardized eval contexts" to "models are deceptively scheming" is a unwarranted interpretive leap.
4/4 We can’t build trustworthy AI procurement without an institution capable of certifying what that even means.
Fund CAISI at $100 million.
@A1Policy has reached the same figure through a diligent comparative analysis. It’s no fault of NIST or Congress that CAISI got its training wheels on a $10m budget; capabilities grew a lot since 2024. In the next year, AI capabilities will again compound faster than appropriations. The longer this waits, the wider the gap between what CAISI is equipped to deliver and what it actually needs.
https://t.co/c2pUYHFJwk
wrote a guide on getting compute grants as a student, something I wish I did more at the beginning of my PhD. It's honestly one of the highest ROI things you can do as a student (we've gotten 100k+ gpu hrs for roughly 2 weeks of work writing).
https://t.co/U15nwau88a
We are launching a new research fellowship! We are looking for 3 researchers – ideally PhD candidates or early-career postdocs* – who are passionate about AI and democratic governance.
https://t.co/vvWmhshuDi
*We are open to Masters-level students!
Most of what I actually need help with, I never think to tell a model. But why is it on me to remember?
Our new paper asks: what if AI could proactively specialize to individuals and the tasks they’re carrying out at this very moment? 🧵
Rubrics have become the de-facto method of providing rewards for both evals & training in non-verifiable domains.
Surprisingly, we found little has been studied on what makes a quality rubric. Rubrics exhibit several error modes, with significant downstream impact. Our rubric failure mode taxonomy (RIFT) is easy to apply, for detecting and ensuring rubric quality.
If you're at the ICLR DATA-FM workshop or at @iclr_conf, come say hi!)
Love this quote from Zoe and think it's so essential to the mental health and AI discourse:
these models are PRODUCTS meant to keep you hooked on and dependent and "satisfied" as a customer; not challenged & eventually weaned off, as is the goal in actual clinical therapy!