Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
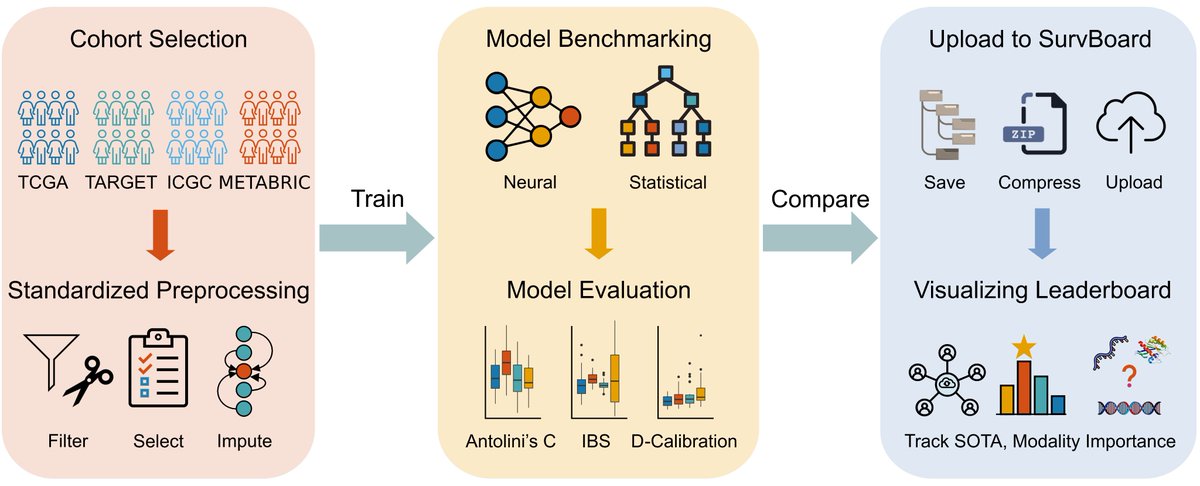
Fresh from the press 👉 "SurvBoard: standardized benchmarking for multi-omics cancer survival models" https://t.co/u3QF7z0hBd with David Wissel, @niklexical, @AayushGrover8, and amazing @MariaRoCompBio, now published in Briefings in Bioinformatics🙌
This work presents a framework, SurvBoard, to benchmark multi-model survival models for cancer patients 🌐 https://t.co/Cxd4CXnwGb
💪Submit your best model there and see how it performs!
📊Our current results show that deep learning approaches underperform compared to statistical models (PriorityLasso and BlockForest).
I used em dashes (a lot) before ChatGPT made them the official punctuation of soulless AI prose.
(can't believe I've had to gentrify my own writing style)
Elated to finally see this work out!🤩Data is at the centre of everything we do. But what if we don’t have enough (something we often face in ML for health😪)? Read our paper to find out how you can augment transcriptomic data using phenotypes! w/ @mormontre@MariaRoCompBio
🧬 Now published in Bioinformatics Advances: “Phenotype driven data augmentation methods for transcriptomic data”
Explore the full study: https://t.co/aQz7RVat7q
Authors include: @niklexical
@irina_espejo@malberts99@drugilsberg Want to start using it already!? We got you covered here - https://t.co/fNcdDUnttS
Check out our paper to understand how we do what we do https://t.co/6DaKSDf03T 😁 Excited to hear your thoughts!!
🚨NeurIPS Workshop Paper🚨
Afraid of releasing LLMs trained on your confidential or proprietary data fearing training data leakage? Worried about how science will progress in domains with small, sensitive datasets? Fret not! We have a solution for you @ https://t.co/PMcko24QaT👇
I'm super proud of this work and super super excited for what's to come! 🤩 A huge shoutout to my AMAZING co-authors @irina_espejo * @malberts99 Andrea @drugilsberg and Antonio (https://t.co/LlUgXTyKl9) without whom none of this would have been possible! only ❤️for my A-Team!
Our chapter serves as a great resource for researchers, chemists, and AI enthusiasts. It is part of the newly published Springer book “Drug Development Supported by Informatics” (https://t.co/9NsP0JvM3q). So what are you waiting for? Give it a read & let us know what you think 😄
📖Book Chapter Alert! “Language Models in Molecular Discovery” (https://t.co/CfuvBRpnuq) is a deep dive into how language models can be used to accelerate molecular discovery, highlighting their strengths and weaknesses.
Together with @JannisBorn@teodorolaino Tim & Sarath, this chapter also provides great pointers to software tools for anyone who’d like to get started with molecular discovery! And as a bonus, a sneak peek into Chemchat, our vision for the future of molecular design 😉
@francoisfleuret We just discussed this paper in our Journal Club today! The idea itself is simplistic and cool, and they show it scales well. But there is some behind the door magic happening with the lambda parameter which imo should be explained in the paper.
🚀 We’re thrilled to introduce SparseSurv, a Python package that brings a new approach to survival analysis by fitting sparse models using knowledge distillation. This method provides powerful predictive insights while keeping models small and interpretable, even with high-dimensional biomedical data.
🔑 Key Highlights:
- Combines machine learning and survival analysis to handle complex datasets.
- Optimizes model sparsity for better interpretability and efficiency.
- Designed for high-dimensional multi-omics and clinical data.
Learn more about the SparseSurv Python package by reading our paper by David Wissel, @niklexical et al. in Bioinformatics: https://t.co/I2I5M0JTwR
Big news! @IBMResearch and @NASAEarth just released a foundation model for weather and climate, Prithvi WxC, on @huggingface to help scientists and devs gain new insights about short-term weather and long-term climate conditions. https://t.co/XeyGnlaVKr
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka 🍓) Let me explain 🧵 1/
We're hiring! My new group at @ETH_en has the following opening:
"PhD Position in Medical AI and Foundation Models"
More details here:
https://t.co/veVSlHr06J
Please share & repost widely!