LLMs can attend to way more text than their original context window -- Accepted to ACL 2023 main conference 🥳🥳
"Parallel Context Windows for Large Language Models"
Paper: https://t.co/yDUFTRAsON
Code: https://t.co/r0KRAWJYjQ
#ACL2023#ACL2023NLP#NLProc
Alright, ready for this?
Here’s a quick thread with highlights from The 7 October Parliamentary Commission Report—also known as The Roberts Report.
It’s the most comprehensive document published to date on the events of October 7, 2023, detailing thousands of incidents from that day.
The report was compiled by a commission led by Lord Andrew Roberts of Belgravia—a historian and member of the UK House of Lords.
Its members included Lords, Barons, and MPs from across the British political spectrum.
“We added nothing that wasn’t proven. The horror needs no exaggeration.”
- Lord Roberts, Chair of the Commission
In this thread, I’ll share key excerpts from the report, divided into a few categories:
��� The numbers behind the barbaric attack
🔹 Selected quotes from Hamas terrorists during the assault—taken from Hamas’s own materials: GoPro footage, audio recordings, live streams, and social media posts
🔹 Some of the most extreme atrocities committed that day
🔹 Powerful testimony from survivors
No drama. No exaggeration. Just the facts.
Let’s start with the numbers:
👇
Today we launched Jamba 1.6, the best open model for private enterprise deployment. AI21’s Jamba outperforms Cohere, Mistral and Llama on key benchmarks, including Arena Hard, and rivals leading closed models while maintaining unmatched speed and quality.
Now available on AI21’s Studio and @Hugging Face.
Learn more: https://t.co/LZD7IXKqZe
📄Jamba-1.5 whitepaper is out!
The whitepaper details the architecture, training schemes, novelties and in-depth evaluations of our new long context hybrid SSM-Transformer models - Jamba-1.5-Large and Jamba-1.5-Mini.
Arxiv: https://t.co/bZpWQcbHSa
Here are some highlights and insights from the paper 👇1/7
We released the #Jamba 1.5 open model family:
- 256K #contextwindow
- Up to 2.5X faster on #longcontext in its size class
- Native support for structured JSON output, function calling, digesting doc objects & generating citations
https://t.co/tebBJW09c5
#AI#LLM#AI21Jamba
Introducing Jamba, our groundbreaking SSM-Transformer open model!
As the first production-grade model based on Mamba architecture, Jamba achieves an unprecedented 3X throughput and fits 140K context on a single GPU.
🥂Meet Jamba https://t.co/f2XZFOQbxh
🔨Build on @huggingface
#NLProc
I am happy to share I will be presenting our paper “Generating Benchmarks for Factuality Evaluation of Language Models” at #EACL2024!
Check out our updated version on arxiv, introducing a new benchmark: Expert-FACTOR (based on ExpertQA) 🚀
Paper, Datasets & Code: ⬇️⬇️
🧵
I just witnessed ~45 minutes of footage of the October 7th terrorist attack at the @AtlanticCouncil courtesy of @IsraelinUSA along with colleagues from think tanks across the ideological spectrum. What I saw was worse than I’ve ever seen.
Pure evil.
***Trigger Warning***
@jastorj No, it will be quadratic in the number of task token plus the number of tokens in a single window, but not quadratic in the sum of tokens in all windows.
#NLProc
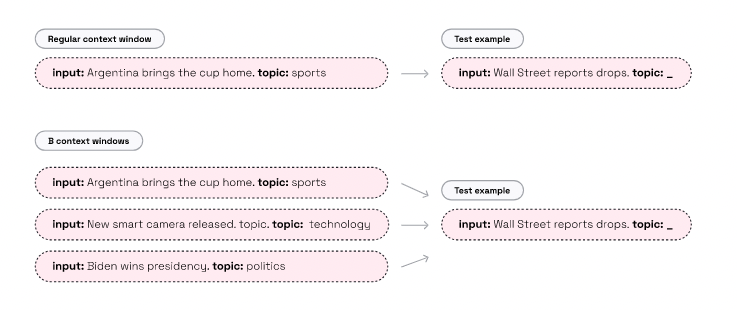
Is the context window of your LLM too small for you?
Do you want to add in-context examples but can’t?
Parallel Context Windows increase any LLM’s context *without further training*!
🚨 Paper from @AI21Labs
"Parallel Context Windows Improve In-Context Learning"
🧵
@boknilev@janundnik@boknilev Many reported results for multiple choices of N (https://t.co/IbiHe9NwuQ for example), but I can't recall any paper specifically focusing on those plots. I suspect that Min, S did this one of those plots in one of her papers but I can't recall which one.
Generating Benchmarks for Factuality Evaluation of Language Models
paper page: https://t.co/WpgdJBL99C
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators.
#NLProc
New paper!
“Generating Benchmarks for Factuality Evaluation of Language Models”
From @AI21Labs
Evaluate an LM’s tendency to generate true facts from your knowledge-intensive corpus!
Paper: https://t.co/xDm2f2tRne
Code & Data (soon): https://t.co/QyToxP4n2S
🧵⬇️
Do you want to process long texts with LLaMA models, but can't due to its context length? This one is for you!
We have implemented PCW for LLaMA, enabling larger contexts!!
Link:
https://t.co/r0KRAWJYjQ
#NLProc
Is the context window of your LLM too small for you?
Do you want to add in-context examples but can’t?
Parallel Context Windows increase any LLM’s context *without further training*!
🚨 Paper from @AI21Labs
"Parallel Context Windows Improve In-Context Learning"
🧵
LLMs can attend to way more text than their original context window -- Accepted to ACL 2023 main conference 🥳🥳
"Parallel Context Windows for Large Language Models"
Paper: https://t.co/yDUFTRAsON
Code: https://t.co/r0KRAWJYjQ
#ACL2023#ACL2023NLP#NLProc