[Tech Blog] LoRA.rar uses a hypernetwork to merge content and style LoRAs in real-time, outperforming ZipLoRA in speed and quality. Trained on diverse pairs, it generalizes to unseen combinations, making it perfect for edge devices.
#AI#LoRA#ImageGen
https://t.co/BW2h3IioDP
Our paper LoRA.rar just won the Best Paper Award at the P13N: Personalization in Generative AI Workshop @ ICCV 2025! 🎉
📄 Check it out here: https://t.co/J2EXdxiEej
(1/7) Happy to share that our paper on adapter merging (https://t.co/OdFdAxjclY) has been accepted to EMNLP 2025 (Main Conference)!
Huge thanks to my co-authors:
@OBohdal, Mete Ozay, KyengHun Lee, Jijoong Moon, Hyeonmok Ko, @umbertomichieli
🚀Exciting news, 𝗟𝗼𝗥𝗔.𝗿𝗮𝗿 has been accepted to @ICCVConference, which will be held in October in Hawaii🌈.
Huge thanks to the team: @OBohdal, Mete Ozay, Pietro Zanuttigh, and @umbertomichieli.
📜Preprint: https://t.co/3p3mpVinBh
💻Code: https://t.co/iVBIOtnbur
I'll be at #ICLR2025 next week to present VL-ICL, our benchmark for multimodal in-context learning.
Find me at the poster session and happy to chat about all kinds of stuffs on multimodal LLMs and more. DM/email is welcome!
Our benchmark for evaluating in-context learning of multimodal LLMs has been accepted to ICLR'25! 🎉 Check out the project page for more details: https://t.co/qitK1gjBqb 📄
Our VL-ICL bench is accepted to @iclr_conf! It's been almost a year since we developed it yet state-of-the-art VLMs still struggle on learning in-context. Great to work with @OBohdal and @tmh31.
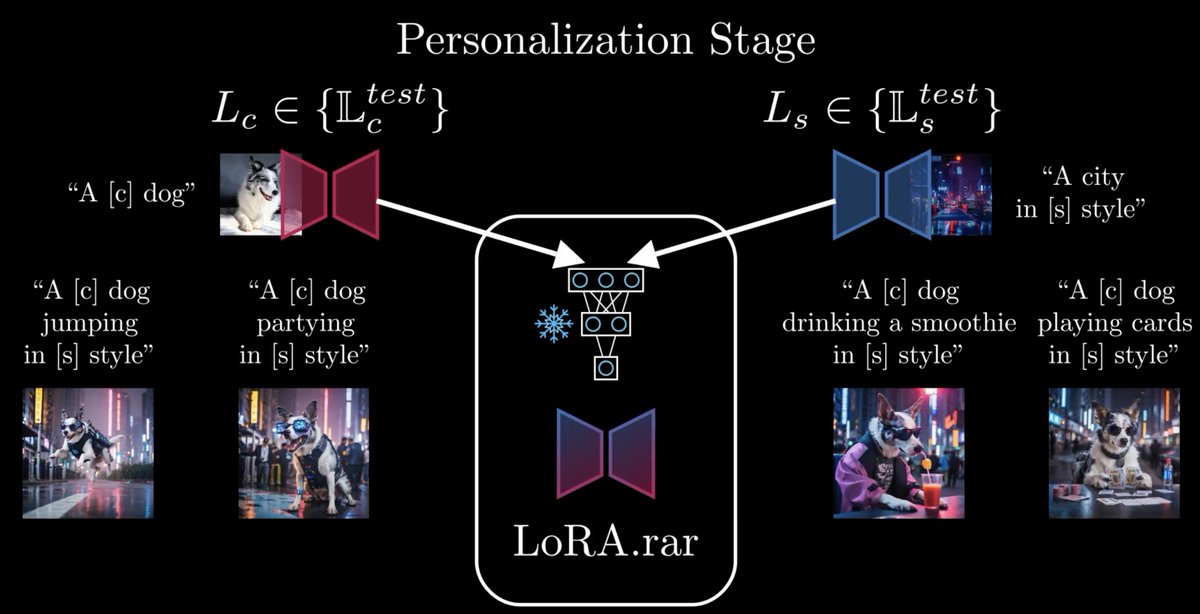
🛸Excited to release 𝗟𝗼𝗥𝗔.𝗿𝗮𝗿, a groundbreaking method for personalized content and style image generation 🦕.
📜 Paper and video: https://t.co/3p3mpVinBh https://t.co/10GUW58lvr
Huge thanks to the co-authors: @OBohdal, Mete Ozay, Pietro Zanuttigh, and @umbertomichieli
Looking to reduce memorization WHILE improving image quality in diffusion models?
Delighted to share our work "𝐌𝐞𝐦𝐂𝐨𝐧𝐭𝐫𝐨𝐥" now accepted at WACV '25 (@wacv_official). We show strong results for medical image generation and also establish an initial benchmark!
More 👇
Career update: I'm excited to share the news that I've recently joined Samsung Research! 🎉
I'll be primarily doing research on large language models.
Looking forward to catching up with friends in London 🇬🇧 🙌 and also meeting new people here!
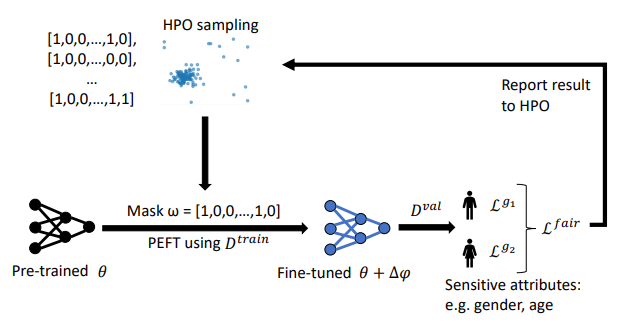
🚨 MemControl: Mitigating Memorization in Medical Diffusion Models via Automated Parameter Selection
A new strategy to mitigate memorization in Diffusion models
Arxiv: https://t.co/EIGrSOk8DL
Work done with @SnchzPedro_@OBohdal@STsaftaris@tmh31@BioMedAI_CDT
🧵👇
Finally arrived in Vienna to present FairTune at @iclr_conf. A dream come true ✨
Also, co-organizing the ML-Collective social on 8th (12:45-2:15 CEST) with @savvyRL@rahiment@osaukh and @Muhtasham9. Do join us!
DM for discussions around PEFT, diffusion, Medical imaging etc
Noise can be helpful for improving generalisation and uncertainty calibration of neural networks - but how to use it effectively in different scenarios? Find out in our recent paper that was accepted to #TMLR!
I am thrilled to share our latest paper, "Navigating Noise: A Study of How Noise Influences Generalisation and Calibration of Neural Networks https://t.co/Mq88BKttB3," published in @TmlrOrg, This work is a collective effort by @OBohdal , @tmh31, @mrd_rodrigues and myself :).
Curious about how to better evaluate in-context learning in multimodal #LLMs? We introduce VL-ICL Bench to enable rigorous evaluation of MLLM's ability to learn from a few examples✨. Details at https://t.co/OhEgAqywmm
Evaluating the capabilities of multimodal in-context learning of #VLLMs? You can do better than VQA and captioning! Introducing *VL-ICL Bench* for both image-to-text and text-to-image #ICL.
Project page: https://t.co/Z9TFot8x8K
Vision-language models are highly capable yet prone to generate unsafe content. To help with this challenge, we introduce the VLGuard safety fine-tuning dataset ✨, together with two strategies for how to utilise it ✅. Learn more at ➡️ https://t.co/CGRMEJU6xk
Your #VLLMs are capable, but they are not safe enough! We present the first safety fine-tuning dataset VLGuard for VLLMs. By fine-tuning on it, the safety of VLLMs can be substantially improved while maintaining helpfulness. Check here for more details: https://t.co/CXiTscpMUk
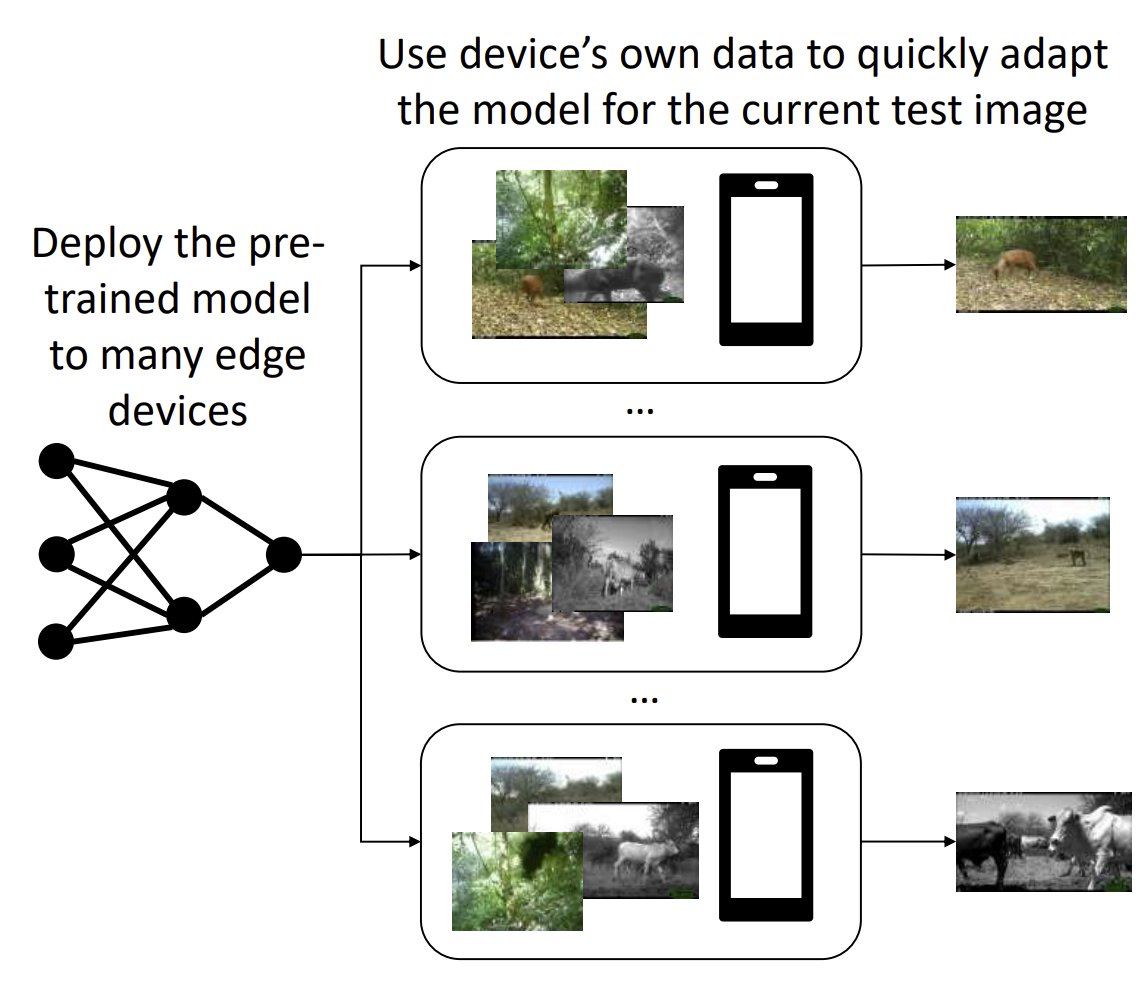
I'm excited to be at WACV'24 in Hawaii to present a poster for our Feed-Forward Latent Domain Adaptation paper! More details in the thread below 🧵 and at the project website https://t.co/F07dE1quxN
To address this challenging problem setting, we introduce a method that utilises a cross-attention mechanism to select relevant examples and adapt the model (3/4)