I think a lot of people are confused about how models like Grok Build and Composer 2.5 fit into agentic coding workflows.
Lately I've seen people say things like, "well they don't score as high as GPT 5.5 or Opus 4.8 on DeepSWE so why would I use them?"
And when I see stuff like that, I think people are missing the point.
We now live in a world where you don't have to, and probably shouldn't, just use one model for coding. If you had infinite money, and time, I guess you could do that, but it would be expensive and slow.
Instead, you can now use different models for different things, and start to develop an understanding of how particular models might excel at certain tasks.
For me, models like Grok Build and Composer 2.5 are both super useful, but in different ways.
I often compare Grok Build to a mad scientist. It does a really good job of running experiments, building agentic teams, and documenting what it's doing in great detail.
Composer 2.5 has some serious raw speed. It's great at building things quickly, writing unit tests, and building pretty clean frontends, quickly and efficiently.
And with both of these models, you can create production-grade code, but yeah, you might not be able to one-shot it, but I don't understand why that would be the goal.
We aren't moving into a time where people should just want to one-shot production-grade applications. Instead, you should look at models as team members, each with a different set of skills and abilities.
I think it's more than okay to work with 3-5 models when you're building software. In this "model stack," there is a very meaningful place for models like Grok Build and Composer 2.5, and as they both continue to grow and progress, the places you use them might change too.
This is the beauty of innovation, things get better, and as that happens, your workflows change and get better too.
So if you're just using one model to build, and you pick that model based on one benchmark, you're probably missing out.
There has never been a better time to experiment with different models and see how they can fit into, and optimize your agentic coding workflow.
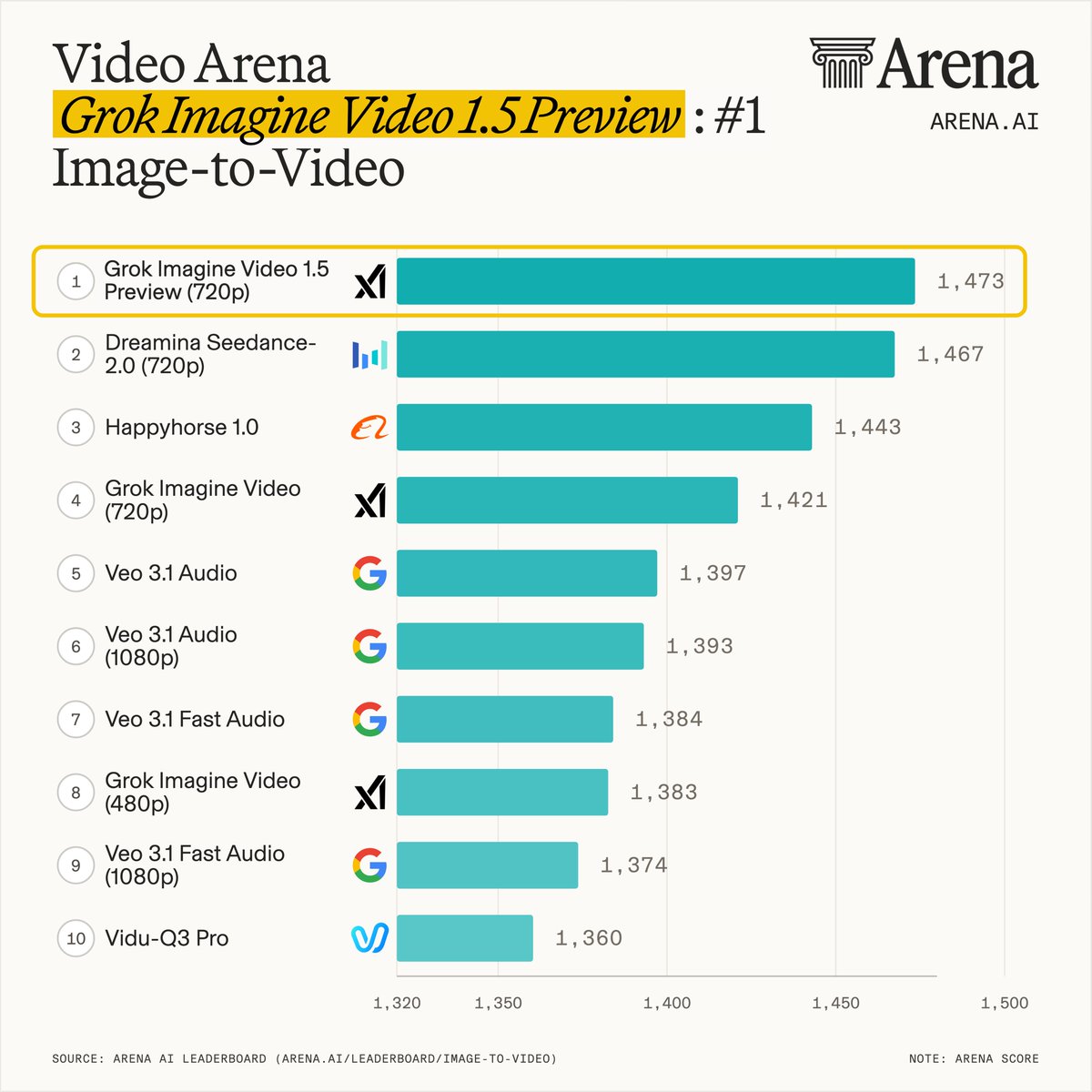
Grok-Imagine-Video-1.5-Preview (720p) has landed #1 in the Image-to-Video Arena!
This is a massive +52 pt improvement over Grok-Imagine-Video (720p), surpassing the best video models Seedance-2.0 and HappyHorse.
Congrats to @xAI and @elonmusk on this big achievement!
@KettlebellDan I just left the SpaceXAI office at ~2:45am and people were still going.
I think we might be close to a significant breakthrough in training.
When training Grok 4.3, we spoke directly with devs and businesses to understand what they actually needed: a model that’s fast, affordable, and great at tool calling. The result is a daily driver that doesn't just look good on random benchmarks, but is actually useful in the real world.
💰 $1.25 in / $2.50 out
⚡️ 100 tokens / second
📖 1 million context window
Try it through Hermes Agent or direct through the xAI API!
Introducing Grok Voice Think Fast 1.0
A state-of-the-art voice model built for complex, multi-step workflows with snappy responses and high accuracy.
It takes the top spot on the Tau Voice Bench and handles real-world messiness like noise, accents, and interruptions better than any other model in the world.
https://t.co/SwdNYRH7Po
Grok's Speech to Text API is now available.
Instant, multi-speaker transcription across 25 languages - at the best price in the market.
https://t.co/eGbB2bDtZf