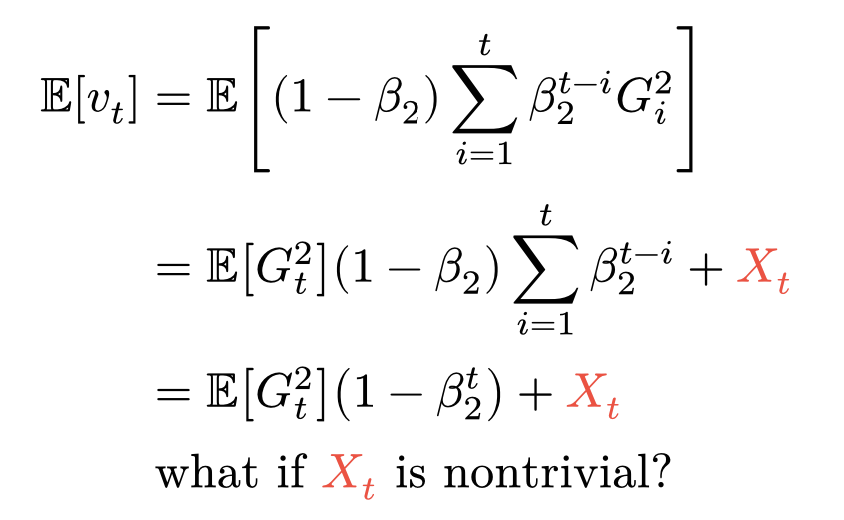I am genuinely interested! Empirical research around how well our ad-hoc estimates (of gradients, variances, and Fisher information for example) perform is surprisingly limited, since it needs to be constantly reevaluated as SOTA changes
Adam depends on the gradient distribution during training, which, as far as I know, we don't understand well?
Here, adapted from the Adam paper, v_t is the var estimate, G_t is the gradient r.v. and X_t is an error r.v. for distribution shift.
Should we be trying to detect distribution shift and correct it (eg. by taking more samples at the same set of parameters)? Does this matter in some models and not others?
My first PhD paper!🎉We learn *diffusion* models for code generation that learn to directly *edit* syntax trees of programs. The result is a system that can incrementally write code, see the execution output, and debug it. 🧵1/n
@Apoorva__Lal Garner's usage dictionary calls these needless variants. Usage dictionaries outside of professional editing seem somewhat rare, but would be very useful in technical disciplines (if unrealistic to make.)
@bronzeagepapi Probably not. I've generally found custom kernels to be less necessary when using JAX due to compilation (the benefit may be marginal compared to PyTorch.)
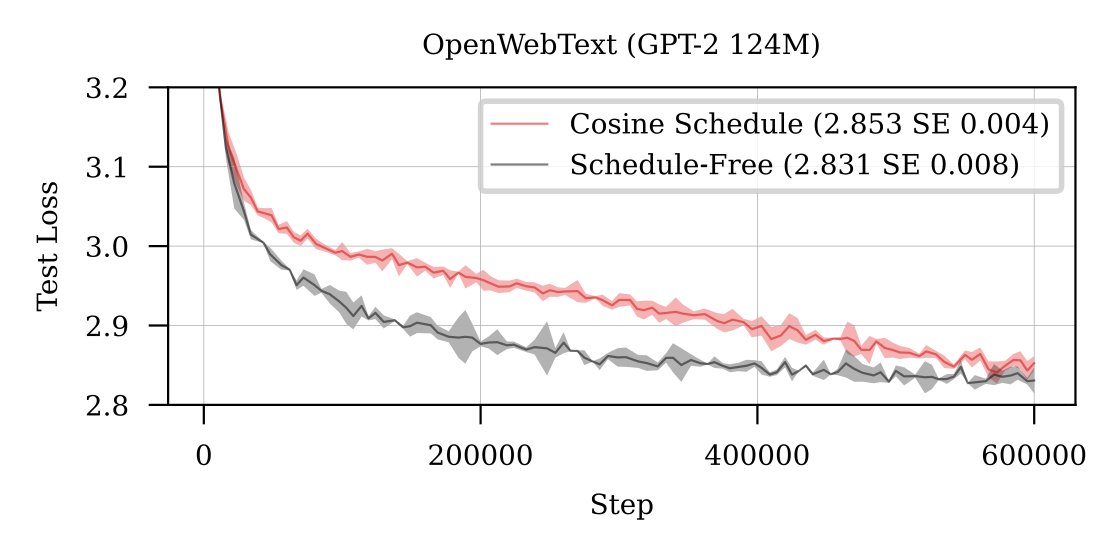
Schedule-Free paper is up!
https://t.co/vduzoGL5EP
Joint work with collaborators @alicey_ang@HarshMeh1a@konstmish @akhaledv2 @AshokCutkosky
We have some strong small-scale experiments on Transformers, comparing to chinchilla-style cosine 10x reduction schedules.
@sp_monte_carlo Neat! Heuristics based on this crop up in stochastic optimisation. Often in the argument of stepsize * sum/sqrt(squared_sum) being "roughly" bounded by stepsize. Of course the independent and symmetric assumptions are both violated but that never stopped anyone...
@RndmForestRunnr@wser Ultimately I think the question is "who do we want getting into wser?" Optimising the lottery is not the hard part, it's agreeing on who we should be optimising for that is.
Finally, a million thanks to @PatrickKidger, who supervised this whole project.
If you’re following me, chances are good you already follow him. If not, go give him a follow! (right after installing Lineax of course 😉)
4/4
⭐ Lineax is now on arXiv! ⭐
If you’re doing linear solves or linear least-squares in JAX, give it a shot today!
Lineax
is fast ⚡️,
has new solvers (eg. QR, tridiagonal),
supports general linear Operators.
github: https://t.co/Qn8PEI8SYH
arXiv: https://t.co/nnDSiKMWOJ
1/n
The paper describes out how we achieved many of these things (such as differentiation through all our solvers,) and outlines some of the design choices we made when creating Lineax.
https://t.co/nnDSiKMWOJ
They mentioned the choice between these two model functions made little difference in practice.
While this is believable, and indeed proved to be true, it struck me as an example of a claim which is very difficult to verify using existing optimisation software.
12/12
Tikhnov regularised trust-region methods (*cough* Levenberg-Marquardt) oddly use two different approximations to the objective function at each step.
One regularised, one not.
What if we just regularised both?
1/