1/7 I entered the Grokathon at @xai in London this weekend.
X just open-sourced their For You algorithm where Grok runs per user, per post, per request.
I built a version where Grok learns online without inference.
It's a million times more efficient.
A token is ~a word …
A human generates ~a token/sec
There are ~10B humans on Earth
Humans generate ~10B tokens/sec
A H100 generates ~1,000 tokens/sec
There are ~10M H100s et al.
Machines generate ~10B tokens/sec
2026 is the fleeting equilibrium of man+machine.
it's not that easy. i can explain why they didn't release a model competitive with what we have seen trained by a lab with 30 people
it was performance review season and that is literally all that matters
You had one job Meta:
- take the DeepSeek recipe
- scale the recipe to 5T params
- train it with your bazillions of H100s and unlimited social media data
- RL until your staff is burnt out from babysitting the runs
- distill into cuter 30B, 100B and 500B models
- profit
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
@jkcarlsmith@AmandaAskell what work is being done to understand the constitution in latent space. is it already prompt fine tuned as a prepended embedding? telling someone what their soul is incurs signal loss as it is internalised
@fchollet they also conflate general intelligence with being able to do any job. not realising how much of people's jobs is generating their own context to fulfil an unclear spec that describes their responsibilities
@EitanTurok they will only be able to distill on a model's text if they had some sort of machine learning algorithm that could learn from patterns in large amounts of data
@ID_AA_Carmack i think that all arch choices should have a mechanistic interpretation like this. in any paper i read there is always a "we posit this is because intuitively it's easier for the model to x". any example of a researcher's intuition in a paper is the ideal seed for a new paper
> 2026 version of "crypto will remove all financial friction" while its financial market share is zero
entire industries replaced by AI in 2027?
try starting with replacing ONE sp500 company and see how hard a sell this is
I spent 100 hours over the past week researching, writing and editing the piece we just put out.
It’s a scenario, not a prediction like most of our work. But it was rigorously constructed, dismissing it outright requires the kind of intellectual laziness that tends to get expensive.
And we’ve released it for free. Hopefully you enjoy it.
https://t.co/YK8E11GcDU
please give a source of a single 2+ year old h100 listing that was actually verifiably fulfilled at $7-12K. you're falling for the same scheme that those 'sellers' are hoping you will fall for. they want to send you a box of rocks from china for $7-12K and have no recourse
I can argue the other points too but you're goal post shifting 'hedging' is too far from the truth to do so in good faith.
@HedgieMarkets the H100 launched at ~$40K and is now selling used for $15–25K roughly 2–3 years in, that lines up pretty well with straight-line depreciation over 5 years
your main point was fabricated and your thesis is being debunked by your own numbers
Who’s working on this idea:
Openclaw for personal finance
- integrates w all your banks/cards/etc
- understands tax returns and filings
- monitors portfolio and competitors
- digests proprietary data sources (credit card panels, app rankings, and etc)
- reads company news and X
Etc etc
Impressive! Basically everything in your post is wrong!
The few H100s that are being sold for $6k on eBay are “parts-only” meaning they don’t function, they are only for repairing other H100s.
In reality, used H100s are still selling for $15-20k+. Not bad considering the original MSRP was $25-40k depending on the exact variant!
What’s more, NVDA still makes H100s and sells them for nearly the same price it did at launch.
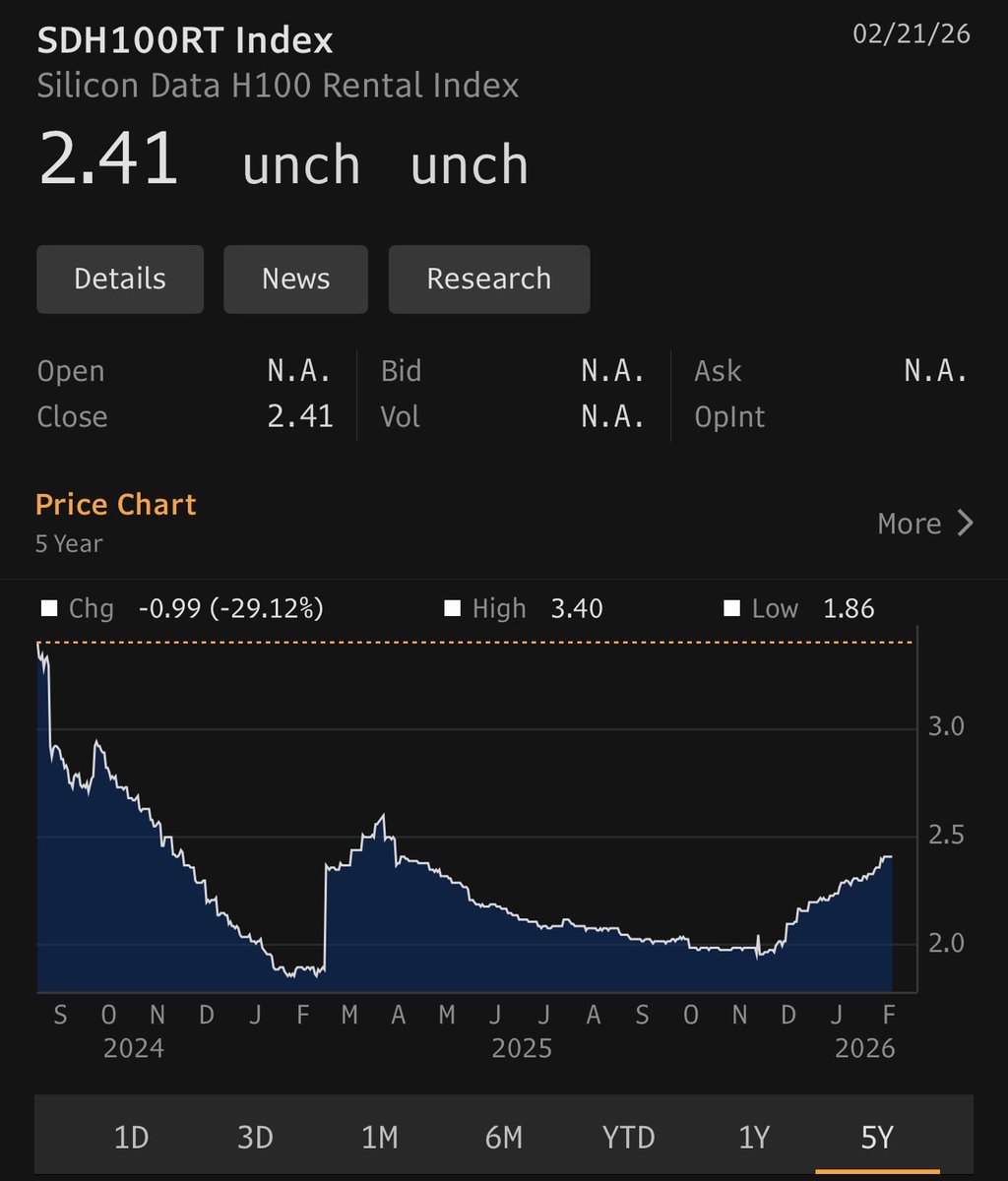
Lastly, I’ve included a screenshot of the H100 rental price index showing that H100 rental prices are actually growing again. We don’t have to use your flimsy math to determine their value, we can just check the market!
@deedydas stating the ai breakthrough they are going to make money from would probably make this list less interesting
how many are "copilot for x" "verifiable agents for y" "open source version of z". neolab needs to make money too no matter how cool their goals are
Today, @steipete became the first confirmed (long theorized) one-person Unicorn!
OpenClaw launched as a weekend side project by less than 3 months ago. Here's the timeline:
Nov 25: First GitHub commit. Starts as a weekend side project
Jan 25: Goes nuclear. 9k stars in one day. 2M website visitors in a single week
Jan 27: Renamed Moltbot (possibly the worst renaming ever) after Anthropic trademark complaint
Jan 29: Renamed @OpenClaw (thank GOODNESS!), blog confirms 100k+ stars milestone
Early Feb: Hits 145k–149k stars + 20k forks
Feb 11: Steinberger notes 180k people starred the repo
Feb 12: Steinberger on Lex Fridman podcast, shares story & vision
Feb 15 (today): Sam Altman announces Steinberger joining OpenAI to build next-gen personal/multi-agent systems
Full cycle: 82 days from zero to this
Absolutely INSANE!