토스 출신 디자이너의 AI 디자인 워크플로우
1. 레퍼런스 수집
핀터레스트 등에서 마음에 드는 디자인 레퍼런스 찾기
2. AI로 디자인 구성 계획 및 초안 생성
Gemini나 Claude로
디자인의 구조와 구성 계획을 먼저 텍스트로 설계
레퍼런스 이미지를 첨부하고,
"이런 느낌으로 XX 만들려고 하는데
어떻게 구조를 짜면 좋을까?
이미지 만들지 말고 구성 계획을 해줘"
구조가 마음에 들 때까지
AI와 대화하고 수정하며 초안 생성
3. 피그마에서 편집하기
AI가 만든 초안을 바탕으로
피그마에서 폰트, 레이아웃, 디테일 등을
직접 다듬어 완성도 있는 출력물을 제작
특히 아���디어 구조 설계나 비주얼 디자인 초안 생성에
AI를 사용하면 리소스를 절감할 수 있음.
AI 용어 공부 1화 — 토큰
AI 공부하기로 결심
가장 기초가 "토큰"이라길래 거기부터 봤음
근데 용어 한 개 공부했을 뿐인데
Think Tank 시스템을 통째로 수정함
토큰 효율 2-30% 상승할듯
1. 토큰이란?
- 언어 모델이 글자를 처리할 때 쓰는 가장 작은 단위
- Anthropic 공식 기준 "Claude는 1토큰 ≈ 영어 글자 3.5개"
근데 단순히 글자 수로 자르는 건 아님
자주 쓰이는 단어는 통째로 1토큰
잘 안쓰는 단어는 잘게 쪼개짐
예시:
- "Hello" → 1토큰
- "running" → 1토큰
- "Anthropic" → 3토큰 (An + throp + ic)
- "asdfghjk" → 8토큰 (의미없는 나열)
이 로직 알고리즘 이름은 BPE (Byte Pair Encoding)
자주 같이 붙어 나오는 글자 쌍을 합쳐서 사전에 등재하고 반복하는 방식
2. 영어 > 한국어
-영어 토큰화는 효율 좋고 한국어는 안 좋음
결국 LLM은 학습 데이터 기반으로 작동함
AI 학습 데이터에서 영어는 60-70%가 넘는데 한국어는 1-2% 수준
한국어 묶음 통계 자체가 약함 → 글자 단위로 쪼개짐
그리고 한국어의 은~는~이~가~~ 조사 어미가 병목임
영어는 "Bugi / to Bugi / of Bugi" 단어가 그대로인데
한국어는 "부기 / 부기가 / 부기를 / 부기의"
매번 조사가 달라지니까 BPE 입장에서 "부기" 통째로 묶기가 어려움
같은 의미라도 한국어 토큰이 2-3배 소모됨
---
3. Think Tank 시스템 개선 - 추론 과정 영어화
내 시스템도 내부 추론을 한국어로 굴리고 있었음
근데 추론 과정은 우리 안읽잖아..? 응답만 보지
CLAUDE.md에 한 줄 추가함
"추론(thinking)은 영어로, 응답은 한국어로"
추론 토큰 20-30% 절약될 듯
---
4. Think Tank 시스템 개선 - 메모리 영어화
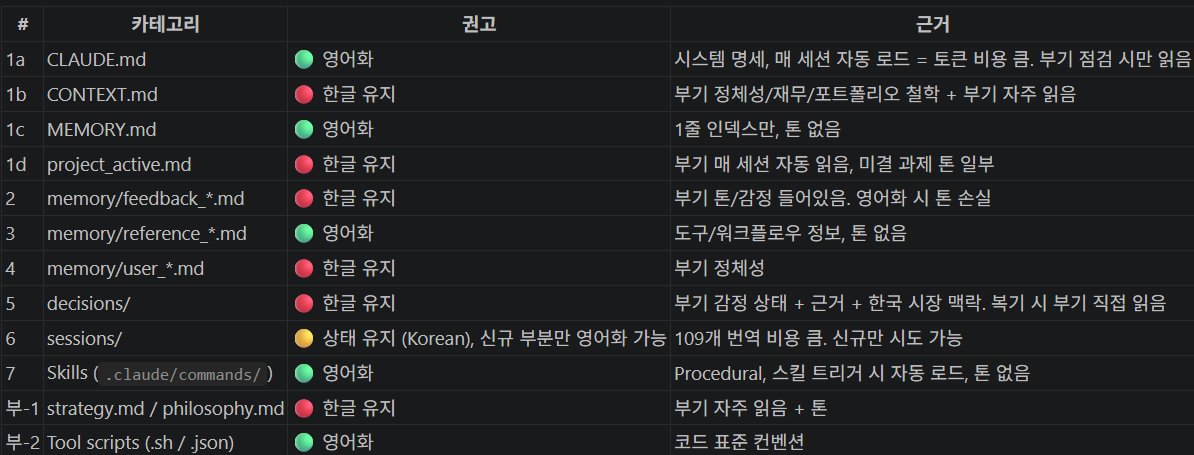
내 Think Tank 구조는 첨부 사진처럼 되어있음
다 한글로 구성해뒀었는데 파일별 성격따라 영어화로 변경함
매 세션 자동 로드되는 거 (CLAUDE.md, MEMORY.md)
→ 영어화. 세션 토큰 손실 줄임
내 톤 들어있는 거 (feedback, decisions)
→ 한국어 유지 (톤 손실)
내가 자주 읽는 거 (CONTEXT.md)
→ 한국어 유지
거의 안 읽는 거 (오래된 sessions)
→ 그냥 두기 (번역 비용 ROI 0)
전체 영어화도 아니고 전체 한국어도 아니고
파일별로 분류한 언어 정책 적용함
---
용어 한 개 공부했을 뿐인데
시스템 개선까지 해버림
- 추론은 영어, 응답은 한국어
- 파일별 언어 정책 설계
- MEMORY.md 영어화 파일럿 예정
이래서 Think Tank 굴리는 거임..
같이 공부하고
같이 개선해나가면서
내 지식을 장기 기억으로 만들기!!
📌20년 짬밥 과일가게 사장님의 천재적 꿀팁
1>레드향이나 오렌지 까기 귀찮을때
반으로 자른다음 뒷면을 살살 자르면서 밀어주기만 하면 됨
2>사과 자르기
가운데 꼭지를 기준으로 양 옆을 잘라주고 돌려서 양 옆 자르면 버리는 것 없이 먹을 수 있다
3>키위 자르기
코다리를 잘라주고 세로로 칼집 낸 다음 숟가락으로 살살 돌려만 주자!
4>아보카도 자르기
아보카도에 거품기를 넣고 돌려주기만 하면 3초만에 깔끔하게 아보카도를 도려낼 수 있다!