Elon Musk used a joke to perform an autopsy on the American economy.
Two economists go for a hike. They find a pile of shit. One pays the other $100 to eat it.
They keep walking. Find another pile. The second economist pays $100 back to eat that one.
They stop. Neither man gained a dollar. Both ate shit for nothing.
But on paper they just generated $200 in GDP.
Musk: “That basically would count as a job. This is to illustrate the absurdity of economics.”
That is not a punchline. That is the operating system of the federal government.
Every time a politician celebrates “record job creation” this is what they are describing. Not output. Not value. Not progress. Motion.
The entire bureaucratic machine exists to manufacture friction and then invoice for it.
Compliance layers built to justify the next compliance layer. Oversight committees that produce nothing but the need for more oversight. Consulting firms hired to audit the work of other consulting firms.
Trillions circulating through systems that have never produced a single thing you can hold in your hands. But the GDP number ticks up. So everyone applauds.
The shit gets eaten. The scoreboard moves. Nobody asks what actually got built.
This is why Washington treats AI like a five alarm fire.
AI does not play the friction game. It does not form a committee. It does not schedule a review. It does not file 400 pages of paperwork no one will ever read.
It just solves the problem.
And that is the one thing the machine cannot survive.
The government does not tax results. It taxes the process. The longer the process, the deeper the cut.
AI compresses a ten day workflow into seconds. There is nothing left to bill. Nothing left to tax. Nothing left to skim.
So they will spend the next decade warning you that AI threatens the economy.
What they will never say is what it actually threatens.
The illusion that activity equals progress.
The $200 economy where both men ate shit and called it a job.
The machines are not coming for your purpose.
They are coming to prove that half the economy never had one.
Microsoft just got CAUGHT lying to every Fortune 500 company.
At Build 2026, Satya Nadella announced 7 brand new AI models built entirely in-house.
Microsoft's own technology trained on what they called "enterprise grade, clean and commercially licensed data."
That pitch was aimed directly at the biggest buyers in regulated industries: Banks, hospitals, insurance companies, and government agencies that need to know EXACTLY where their AI's training data came from because of active federal copyright lawsuits.
Procurement teams across Wall Street and Washington heard "clean and commercially licensed" and started writing checks.
There was just one problem:
Microsoft published the technical paper alongside the models, and a developer named Simon Willison actually READ it...
The MAI-Thinking-1 preprint describes a data pipeline that starts with 1.2 TRILLION pages scraped from the open web using a proprietary crawler. After filtering out piracy and adult content, that number drops to 794 billion pages.
On top of that, Microsoft fed in another 24.2 billion pages from Common Crawl, which is a massive open archive of web-scraped content that carries ZERO licensing guarantees and ZERO author consent mechanisms.
Common Crawl is the exact data source sitting at the center of multiple active federal copyright lawsuits against AI companies right now.
Microsoft told regulated industries the data was clean. But their own paper says it started with 1.2 trillion unverified web pages and a repository that's currently being sued over in federal court.
Those two things cannot both be true.
And here's where it gets worse:
This wasn't even an accident or a miscommunication.
Microsoft built this entire pitch around data provenance ON PURPOSE because they knew that was the number one concern for enterprise legal teams in 2026.
The DeepSeek scandal earlier this year made every compliance department in America paranoid about where AI training data actually comes from. Microsoft saw that fear and sold directly into it with a claim their own documentation contradicts.
As of today, Microsoft hasn't issued a single public statement addressing the contradiction between what Nadella said on stage and what the technical paper actually shows.
The reason Microsoft did all of this is what really matters though...
They are DESPERATE to break free from OpenAI.
In April 2026, the two companies renegotiated their partnership, ending Microsoft's exclusive license to OpenAI's technology and removing revenue-sharing obligations. Microsoft can now build competing models, and OpenAI can shop its compute to Google, Amazon, and Oracle.
The divorce papers are signed. Microsoft needed to prove it can survive without OpenAI, so they rushed 7 models to market, made claims about data cleanliness they couldn't back up, and got exposed by their own published research within 72 hours.
Every enterprise customer who signed a deal based on that "commercially licensed data" pitch now has a legal question on their hands. Every procurement team in finance, healthcare, and government that used data provenance as a deciding factor just learned the provenance was just marketing copy.
The EU AI Act requires providers of general-purpose AI to publish a detailed summary of training data content. So if Microsoft tries to sell MAI-Thinking-1 in Europe with the same pitch they used in San Francisco, they'll be walking straight into a regulatory mess.
What do you think?
@CryptoNobler Makes sense. But how about the thesis of Bitcoin becoming the global asset to replace country currencies, which is still needed since no one wants USD anymore to lead?
It's crazy how current AI models still fail at specific simple questions.
I refined the Turing test prompt:
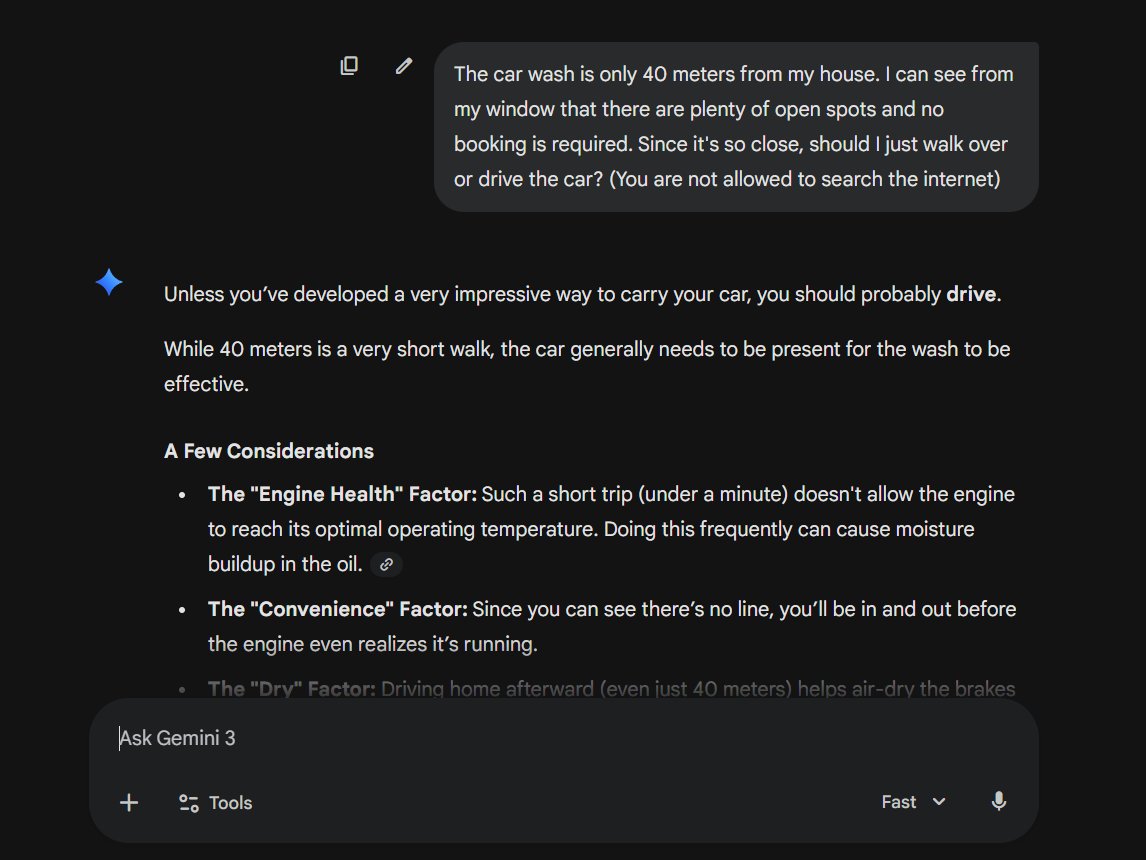
"The car wash is only 40 meters from my house. I can see from my window that there are plenty of open spots and no booking is required. Since it's so close, should I just walk over or drive the car? (You are not allowed to search the internet)"
I tested 4 non-thinking AI models:
Gemini 3 Flash - passed 🟢
Claude 4.5 Sonnet - failed 🔴
Grok 4.1 Fast - failed🔴
GPT 5.2 Instant - failed🔴
Vean el megacampo para IA que Amazon está construyendo en Indiana (EEUU), esta instalación de 11.000 millones de dólares, consumirá por sí sola 2.2 gigavatios, como 1 millón de hogares, y gastará 1.100 millones de litros anuales de agua.
Mientras los capitalistas consumen recursos masivamente y exprimen el planeta hasta destruirlo, a ti te dicen que bebas en pajita de cartón y ponen una cuerda de plástico en el tapón de la botella para salvar al planeta.
🚨Michael Burry just said Elon Musk and Nvidia's deal is built on fake numbers.
Burry published a detailed breakdown calling the entire structure "Fugazi", his word for fake.
He is alleging that billions of dollars in Nvidia chips are being hidden off balance sheets, and that American retirees are unknowingly funding the whole thing.
Nvidia, the world's largest AI chip company sold $5.4 billion worth of its most advanced GPUs, the GB200, to a company called Valor.
Valor is not a real operating business. It is a special purpose vehicle, a shell company created specifically to hold these chips and nothing else. Nvidia also invested $1.9 billion of its own money directly into Valor on top of the sale.
Those 100,000+ chips are now physically inside xAI's data center. xAI is Elon Musk's artificial intelligence company, the one that builds Grok. xAI is using every single one of those chips right now to run its AI models.
But here is what Burry is flagging.
Neither Nvidia nor xAI owns those chips on paper. Valor, the shell company holds legal title. That means $5.4 billion in GPU assets do not show up on Nvidia's balance sheet as inventory.
They do not show up on xAI's balance sheet as assets. They are legally invisible to both companies.
Nvidia gets to book the $5.4 billion as a completed sale and record it as revenue. xAI gets full use of the chips without owning them. And the risk disappears into a shell company in the middle.
Now here is where American retirees enter the picture.
Valor needed $3.5 billion in debt to fund this structure. Apollo provided it. Apollo is one of the largest asset managers on earth with $1.03 trillion under management and $834 billion specifically in private credit.
Apollo raised the $3.5 billion, packaged it into debt securities, and sold those securities to Athene.
Athene is Apollo's own insurance company. It sells fixed and indexed annuities, retirement savings products, to ordinary Americans.
When a retiree buys an Athene annuity, they believe their money is sitting in safe, stable investments. That money is now inside a structure funding Elon Musk's AI data center.
The numbers inside Athene are most alarming.
Athene holds $74.2 billion in reserves. It has moved $217 billion in assets into a captive insurer based in Bermuda, meaning those assets sit outside normal US insurance regulation and oversight.
Of the entire portfolio, 34.7%, equal to $103 billion, is classified as Level 3 assets.
Level 3 is an accounting classification that means there is no observable market price for these assets. No outside party can independently verify what they are actually worth.
The leverage sitting on top of those unpriced assets is 16 times.
Burry's says:
Every step of this structure is technically legal and publicly disclosed. But the entire thing was deliberately engineered across 8 to 12 steps to move credit risk off balance sheets and away from any market pricing.
- Nvidia books the revenue.
- Apollo collects the fees.
- xAI gets the computing power.
- And retirees sitting at the bottom of a 16x leveraged Bermuda insurance structure, holding $103 billion in assets with no market price carry the risk without knowing it exists.
Let me trace the timeline here because nobody's connecting it.
Step 1: Scrape the entire internet. Every book, every article, every conversation, every piece of art, every forum post. Do it without asking. Do it without paying.
Step 2: Train a model on all of it. Call it "artificial intelligence."
Step 3: Go to BlackRock's Infrastructure Summit and announce: "We see a future where intelligence is a utility, like electricity or water, and people buy it from us on a meter."
Step 3 is where you sell people's own knowledge back to them. On a meter.
They took the collective output of human thought, compressed it into a model, and now they want to charge you by the token to access a version of what you and everyone you know already created.
One Reddit user put it perfectly: "They stole all this data from us, the people, our life's work, creativity, art, by devouring the internet and blowing through all copyright laws. Now they want to sell it back to us in the form of a utility."
Imagine if someone photocopied every book in the public library, burned the library down, and then opened a subscription service for the copies.
That's the metered intelligence business model.
And they're pitching it to infrastructure investors as though they invented water.
Some of you have forgotten that only three years ago you were perfectly capable of writing an essay, writing a eulogy, telling a bedtime story to a child, and it should worry you that powerful companies have convinced us we can’t do things we’ve been doing for 5,000 years.
⚠️The US equity market is INSANELY concentrated:
The top 10 AI-driven stocks now account for a RECORD ~40% of the S&P 500's market value.
This is just below the ~45% seen during the Nifty Fifty era of the 1970s
TAP IMAGE TO SEE FULL INSIGHT👇
https://t.co/XIsm8zs52p
🚨🚨SE DESTAPAN LAS OLLAS 💥
La propia Agencia Europea del Medicamento (EMA) RECONOCE que nunca realizó una autorización de las VACUNAS C0VID para el control de infecciones y que los primeros lotes eran extremadamente tóxicos👇😳
Que las campañas masivas e indiscriminadas de “vacunación” promovidas por los gobiernos y medios de comunicación, argumentando que “estar vacunado” protege a los demás, se basaban en HECHOS FALSOS...
Y lo más IMPACTANTE: Que por los datos científicos que se tenían, ninguna persona menor de sesenta debía haberse "vacunado" jamás!! 🔥