@DFintelligence Pour moi c’est la modification du travail. c’est un devis justement, un artiste dois te proposer 2 devis 1 ia boosted -> 30€ pour son expertise prompting avec sa pate d’artiste utilisant l’ia et un devis full hand made. C’est comme pour le dev le métier se transforme, codex !
@DFintelligence@BFMTV Bonne analyse mais il faudrait prendre en compte aussi que le plafond d’en livret A est de 22950 euros. Donc tous les plus riche que cette somme n’ont pas plus sur leur livret. Est ce que ça « débiaise » pas un peu cette moyenne ?
#1 / #XR, #AI & CONVERGING TECHNOLOGIES 🎤 1st talk with @Alex_BOUCH3T from @lavalvirtual The conference begins with the following topic 👇 How AI is enabling the future of XR? Let's get started! 🎬 #LavalVirtual#Technology
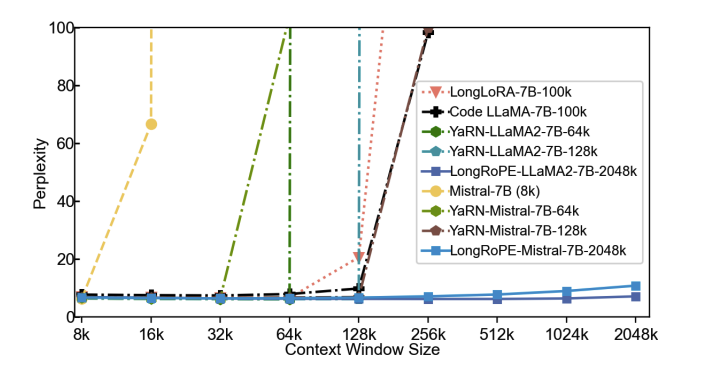
Microsoft presents LongRoPE
Extending LLM Context Window Beyond 2 Million Tokens
Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.
SeamlessStreaming is an AI translation model that can deliver state-of-the-art results on streaming translation with <2 seconds of latency. One core piece of our latest Seamless Communication research work by teams at FAIR.
More on this project ➡️ https://t.co/pPgkrTvryg
Google just revealed an ABSOLUTE depth estimation model 🤯
As opposed to recent depth models (Marigold, PatchFusion) which aim for maximum details, DMD aims to estimate the ABSOLUTE depth (in meters) within the image
More details below ⬇️⬇️
Tencent announces AppAgent
Multimodal Agents as Smartphone Users
paper page: https://t.co/liXrgJXyup
Recent advancements in large language models (LLMs) have led to the creation of intelligent agents capable of performing complex tasks. This paper introduces a novel LLM-based multimodal agent framework designed to operate smartphone applications. Our framework enables the agent to operate smartphone applications through a simplified action space, mimicking human-like interactions such as tapping and swiping. This novel approach bypasses the need for system back-end access, thereby broadening its applicability across diverse apps. Central to our agent's functionality is its innovative learning method. The agent learns to navigate and use new apps either through autonomous exploration or by observing human demonstrations. This process generates a knowledge base that the agent refers to for executing complex tasks across different applications. To demonstrate the practicality of our agent, we conducted extensive testing over 50 tasks in 10 different applications, including social media, email, maps, shopping, and sophisticated image editing tools. The results affirm our agent's proficiency in handling a diverse array of high-level tasks.
Gen2Det: Generate to Detect
paper page: https://t.co/KEPYCc3Ccy
Recently diffusion models have shown improvement in synthetic image quality as well as better control in generation. We motivate and present Gen2Det, a simple modular pipeline to create synthetic training data for object detection for free by leveraging state-of-the-art grounded image generation methods. Unlike existing works which generate individual object instances, require identifying foreground followed by pasting on other images, we simplify to directly generating scene-centric images. In addition to the synthetic data, Gen2Det also proposes a suite of techniques to best utilize the generated data, including image-level filtering, instance-level filtering, and better training recipe to account for imperfections in the generation. Using Gen2Det, we show healthy improvements on object detection and segmentation tasks under various settings and agnostic to detection methods. In the long-tailed detection setting on LVIS, Gen2Det improves the performance on rare categories by a large margin while also significantly improving the performance on other categories, e.g. we see an improvement of 2.13 Box AP and 1.84 Mask AP over just training on real data on LVIS with Mask R-CNN. In the low-data regime setting on COCO, Gen2Det consistently improves both Box and Mask AP by 2.27 and 1.85 points. In the most general detection setting, Gen2Det still demonstrates robust performance gains, e.g. it improves the Box and Mask AP on COCO by 0.45 and 0.32 points.
🚨 New paper!🚨
A few months ago, Meta released Segment Anything Model (SAM). It's already in photography apps, medicine, and video-generation. Now we’ve invented SAM’s little brother, EfficientSAM. It is small but mighty!
With 20x fewer parameters and 20x faster runtime, EfficientSAM is within 2 points (44.4 AP vs 46.5 AP) of the original SAM model.
How'd we do it? I have 2 words for you: Masked Autoencoders. Check out the following for more details!
Paper: https://t.co/2BufoGKDl4
Project details and demo: https://t.co/5Wuze3x0kD
with: @balakrishnan_vr@klightlm@mukosame@Fanyi_Xiao@dilin_wang@fiandola@raghuraman@vikasc, et al
Yesterday we introduced SeamlessExpressive — a new model that preserves unique vocal styles & expression for speech translation, built on our SeamlessM4T v2 foundation model.
More details on the family of Seamless Communication models ➡️
https://t.co/pPgkrTvryg