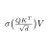All the recordings for the @GPU_MODE x @scaleml series are up as a playlist in case you missed it 😁
There's so much value in these ~8 hours of lectures, from proving quantization error bounds on a whiteboard to a deep-dive into GPU warp schedulers!
Plz take advantage of it!
@rankdim Until qwen models emerged, no other models worked well with RLVR.
Qwen inherently had capabilities like verification and backtracking, which let RLVR improve the likelihoods of these capabilities
Just today years old when I learned that gradient descent is basically the same as Lagrangian mechanics, shoutout to my high-energy physics PhD friend for blowing my mind. 🤯
OpenAI's OSS model possible breakdown:
1. 120B MoE 5B active + 20B text only
2. Trained with Float4 maybe Blackwell chips
3. SwiGLU clip (-7,7) like ReLU6
4. 128K context via YaRN from 4K
5. Sliding window 128 + attention sinks
6. Llama/Mixtral arch + biases
Details:
1. 120B MoE 5B active + 20B text only
Most likely 2 models will be released as per https://t.co/b0lszaF1eV - 120B MoE with 5B/6B active and a 20B dense probably (or MoE).
Not multimodal most likely, just text for now.
2. Trained with Float4 maybe Blackwell chips
MoE layers MLP are merged up / down probably with 8bit scaling factors and float4 weights. Most likely trained with Blackwell chips since they support float4. Or maybe PTQ to float4.
3. SwiGLU clip (-7,7) like ReLU6
Clips SwiGLU to -7 and 7 to reduce outliers and aid float4 quantization. Normally -6 to 6 is good for float4's range, but -7 and 7 is ok as well.
4. 128K context via YaRN from 4K
Native 128K context extended via YaRN from 4K. Long context extension was done probably during mid-training.
5. Sliding window 128 + attention sinks
SWA of 128 was used, but to counteract the SWA not remembering past info, attention sinks like in https://t.co/JMAERMJZGf was used. Maybe 4 / 8 vectors are used. TensorRT-LLM supports the flag "sink_token_length" for attention sinks https://t.co/n2Nqf7iOBt
6. Llama/Mixtral arch + biases
Merged QKV, MLP and also biases are used on all modules it seems. MoE Router has bias as well.
We discussed in @AiEleuther discord here: https://t.co/bxXVtkSUkB
Credits to @apples_jimmy , @secemp9 and others in the Discord server for the discussions!