Your unfair advantage in love & life. Master Psyche Dating, destroy dead bedrooms, dominate divorce, stack jobs, accelerate your career & future proof your life
Is Psychology "Woo"?
Nope. Psychology is a Technology.
Specifically, software -- Psychological software.
And like Software, Psychology is intangible.
But nonetheless real.
Its math, its functions and its algorithms are all computationally deterministic.
1+1 = 2
4-2 = 2
1*2 = 2
4/2 = 2
2^1 = 2
No one in their right mind would claim that "software doesn't exist" and that Microsoft, Oracle, SAP, Netsuite, SFDC or Workday are all "scammers" and "grifters" selling "woo".
And the "PsycheOS" and "Psyche Stack" aren't "Woo".
It's Applied Psychophysics.
The critics' first line of attack is always personal -- "this is woo!", "pseudoscience!", and "you're a pseudointellectual!".
In reality, I am just a solution architect and a software programmer -- of Psychological Software.
The next attack is, "where is the evidence? You can't program the Psyche!"
Or moving goal posts -- "The Psyche is 'real' but it's not programmable!"
And yet these same people are all programmable primates who have been programmed down to their very last neuron.
And are clueless this has even happened.
So where is Microsoft's peer-reviewed research and papers that Microsoft Word works or that you can bold a selection or italicize it or use spell check?
Where is Oracle's peer-reviewed research and papers that you can join a table or write a stored procedure?
They don't exist and yet that software generates hundreds of billions of dollars of revenue per year and employs over 2 million highly paid staff while their customers - businesses we all know and trust - P&G, Unilever, Toyota, Honda, Dell, Lenovo, etc. -- rely on this "woo" aka software to run their businesses.
My evidence is the system, the math, the functions, the algorithms, the software and the results.
Just as theirs is.
The PsycheOS, PsycheStack and Programmable Psyche are testable.
In fact, we have hundreds of millions of data points to back this up over centuries.
The solution?
The solution is to code.
People.
It would be like comparing a Japanese kei truck to a Scat Pack Challenger or Hellcat. They all have engines and wheels but the performance, memory b/w & ability to handle these workloads are in different leagues.
Raspberry Pi 5 ~0.7–3 tok/s
vs
Jetson Orin Nano Super ~15 tok/s
Chips run the world but data defines reality.
No matter how powerful or cost-effective the compute stack is, if the training data is biased, flawed, incomplete or intentionally misleading, then that "trillion-parameter" model on the sexy supercharged tech stack becomes a high-speed autobahn producing plausible falsehoods or distorted worldviews and gets outgamed by my 2005 Excel spreadsheet running VBA and vlookups (or hlookups if that's your cup of tea).
NVIDIA QUIETLY DROPPED A $249 BOX THAT REPLACES YOUR $200/MONTH OPENAI SUBSCRIPTION WITH $2 IN ELECTRICITY
it's called the jetson orin nano super. smaller than a wallet, runs at 25 watts, does 70 trillion ai operations per second. runs llama 3, mistral, gemma and deepseek locally with no api fees and no data leaving your house
a developer running automations and coding assistants pays $200 a month to openai. the same workload on this box costs $2 a month in electricity and breaks even in 10 weeks
install ollama with one command. change one line in your code. point it at localhost instead of openai. everything else works identically
7 billion parameter models handle 80% of what people use chatgpt for. summarization, drafting, coding, document q&a, automation pipelines. total monthly cost drops from $200 to $22
cloud subscriptions keep getting more expensive and rate limits keep getting tighter. the people who set this up in 2025 are going to look very smart in 2027
bookmark this and read the article below
@AuroraMar1eL Many people knew this but the valley echo chamber and circle jerk is/was too powerful.
The CIA AI Cartel thought they could push their bullshit that GPUmaxxing was the only moat that mattered.
And then Qwen, Kimi, Deepseek and friends knocked their c0ck to their back pocket.
🚨BREAKING: HKUST just gave AI agents permanent memory that improves over time.
No retraining required. Lessons from one model transfer to another.
Up to 11 points better on the hardest benchmarks.
> Every AI agent you use today starts each task completely blind. No memory of what worked last time. No memory of what failed. Every mistake gets repeated forever.
> HKUST built XSKILL a dual memory system that accumulates two types of knowledge after every task: skills (what workflows to follow) and experiences (what specific mistakes to avoid).
> The model itself never changes. The memory just gets smarter.
> The part nobody expected: knowledge learned by Gemini transfers directly to GPT and o4 mini. No additional training. One model's lessons become another model's head start.
→ Up to 11.13 point improvement over the strongest baseline on hard benchmarks
→ Syntax errors cut nearly in half: from 20.3% to 11.4% after skills added
→ Cross-model transfer works: Gemini's knowledge improves GPT-5-mini and o4-mini
→ Zero parameter updates required at any point
→ Knowledge compounds: more tasks = smarter memory = better performance
The fix is simple in principle. Skills stop the agent from wasting steps on errors it already made. Experiences tell it exactly which tool to pick in which situation. Together they turn a stateless agent into one that actually learns from its past.
Every AI agent deployed today is leaving this on the table.
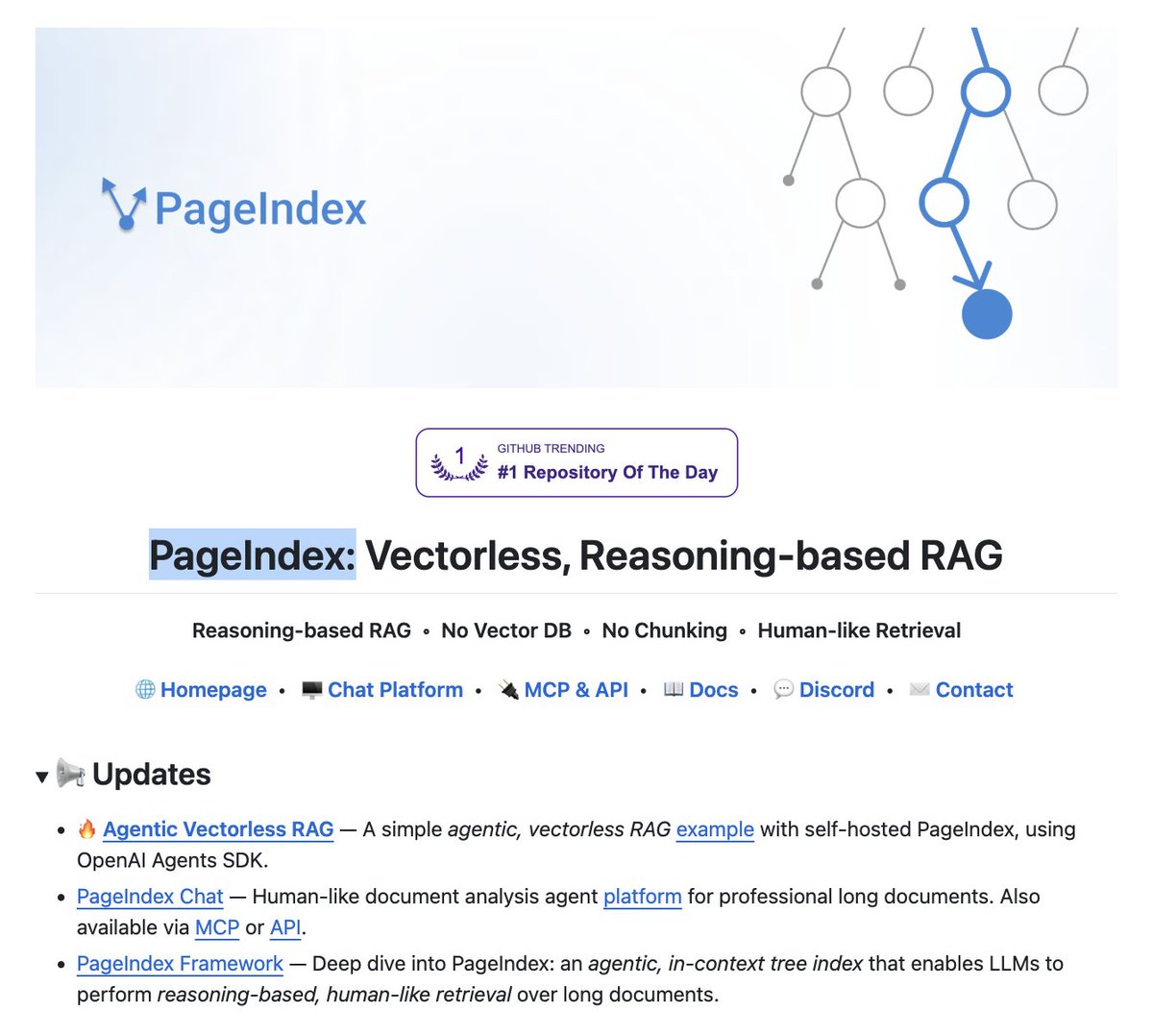
The entire RAG industry is about to get cooked.
Researchers have built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book.
hit 98.7% on financebench. beats every vector RAG on the leaderboard.
no embeddings. no chunking. no vector DB.
100% open source.
I’m unsure why consciousness would be exempt from scientific study.
If it’s the "interface" or HUD/heads up display (dashboard), then it’s precisely a structured system that we can analyze, deconstruct and reconstruct.
This allows us to learn what generates it, what shapes its contents and how it interfaces/relates to underlying mechanisms and systems (brain, regions of brain, psyche, etc.)
Maybe the issue is that we don’t force enough constraint/s on theories early on.
If ideas are forced to be systemized, operationalized, and then required to produce falsifiable, discriminative predictions, this should stop these interchangeable interpretations (of the same intuitions/patterns sensed).
And it may well be that "that" constraint is w hat generates a genuinely new structure/s by reducing error (eror reduction( in how we update or move between competing explanations.
Math + BCI make sense because they add constraints.
But without clearer definitions of "consciousness" (and its dimensions/factors, thresholds, etc.), having even better data and formalisms may just have us see the same disagreements but in higher resolution and color.😀
In my view, the key is whether the theories can be made falsifiable in a way that actually separates them.
If all experience is already simulation (brain-generated), then "simulated vs real" collapses.
What would appear to matter most is the structure and constraints of the simulation and factors/dimensions involved and converging for that to happen, rather than the substrate or label/s involved.
@pubity It just means you start a new company where you are not hiring people who are replaced by AI, you are an AI company where you are hiring some humans to assist the AI.
Tencent has killed fine-tuning and RL with a $18 budget.
Right now, if you want an AI agent to become an expert at a specific, complex real-world task, you have to use Reinforcement Learning.
You let it try, fail, and update its internal parameters over and over again.
This is the exact optimization technique (GRPO) that DeepSeek used to build their massive reasoning models.
But there is a massive problem.
Updating model weights is insanely expensive. It requires massive GPU clusters. And worst of all, when you train a model to be highly specialized at one thing, it often "overfits" and forgets how to be good at everything else.
Tencent killed this bottleneck forever.. by building Training-Free GRPO.
Instead of spending thousands of dollars to permanently alter the AI's brain, they asked a simple question: What if we just distill the experience of learning, and inject it as a memory?
Here is how it works.
They run the AI through the exact same trial-and-error process. But instead of updating the weights, they extract the "semantic advantage"—the actual logic of why one answer was better than another.
They compress this winning logic into a "token prior”, a tiny package of high-quality experiential knowledge.
Then, they just attach that knowledge directly into the API call.
The results are staggering.
Tested on DeepSeek-V3, this method required only a few dozen training samples to turn the AI into a specialized expert in complex math and web searching.
It didn't just compete with models that were actually fine-tuned. It outperformed them.
Zero parameter updates. Zero expensive training runs. Zero base-model amnesia.
@LaWRLDxx@om_patel5 Bayesian inference is "just saying numbers" to a moron.
Heidegger or Kierkegaard is "just saying letters of the alphabet", to a moron.
https://t.co/6xYzH6PDbc
Exactly. Business is the only Battlefield that matters (outside of one's mind / human mind).
And tech founders should be thinking how their business can terraform the world to support their worldview while monetizing their enemies' demise.
7 birds : 1 stone
(ideally 10 birds : 1 stone but not your stone, not your labor, you still get all 10 birds)
Heavy Technical Debt powered by Big Block Brute Force AI.
vs
Fully optimized Clean Sheet Paper process design.
In fact, Clean Sheet Paper processes powered by Microsoft Excel even beat Broken Processes powered by AI.
Startup / New Venture reality:
It's a process of falsification and elimination which takes time but market timing is always pulling the strings.
But the most you can do is push on the strings.
So you need to move as fast as you can (to falsify and eliminate) BUT be resilient enough to hang on if the market isn't ready yet -- and the market, especially nascent markets are almost never ready when you or your product is.