Head-tracked “Window Mode.”
Your front camera finds your head. The view reprojects in real time so the screen feels like a window into the 3D scene.
True3D, no glasses.
DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural net distillation procedure of 1991 [4]: a distilled chain of thought system.
REFERENCES (easy to find on the web):
[1] #DeepSeekR1 (2025): Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2501.12948
[2] J. Schmidhuber (JS, 2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models. arXiv 1210.0118. Sec. 5.3 describes the reinforcement learning (RL) prompt engineer which learns to actively and iteratively query its model for abstract reasoning and planning and decision making.
[3] JS (2018). One Big Net For Everything. arXiv 1802.08864. See also US11853886B2. This paper collapses the reinforcement learner and the world model of [2] (e.g., a foundation model) into a single network, using the neural network distillation procedure of 1991 [4]. Essentially what's now called an RL "Chain of Thought" system, where subsequent improvements are continually distilled into a single net. See also [5].
[4] JS (1991). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991. First working deep learner based on a deep recurrent neural net hierarchy (with different self-organising time scales), overcoming the vanishing gradient problem through unsupervised pre-training (the P in CHatGPT) and predictive coding. Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills - such approaches are now widely used. See also [6].
[5] JS (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990, introducing high-dimensional reward signals and the GAN principle). Contains summaries of [2][3] above.
[6] JS (AI Blog, 2021). 30-year anniversary: First very deep learning with unsupervised pre-training (1991) [4]. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled [4] into a single deep neural network. 1993: solving problems of depth >1000.
In Nodezator's dev branch: changed the magnetic sockets feature to make it closer to what I envisioned originally: the nodes had hands and would help you by grabbing the new connection for you.
The hands are CC0 assets from the excellent @KenneyNL#Python#nodeeditor
📢 Calling all #Python developers! 🐍
In a joint effort from various parts of the Python community, we need your insights on type annotations to improve the type system and tooling support ⚒️
Please take & share this quick survey 🙏
https://t.co/Ko7DfeKHvr
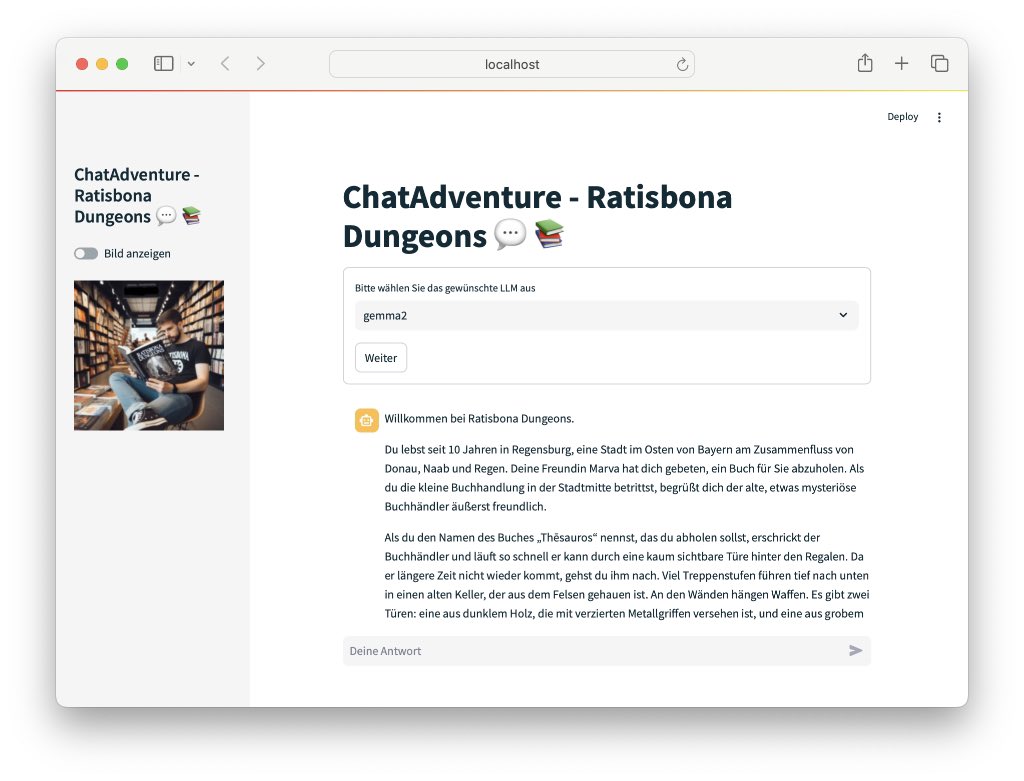
ratisbona-adventure
Habe Adventure-Spiele mit #chatgpt erstellt.
https://t.co/j9YwSMAPbV
Ist sogar im Web spielbar. Bitte rückmelden, wie es gefällt.
(Oder weiter leiten. danke)
#Python#gamedev@streamlit@heisedc
Back in 2020 I was contacted by Make-a-Wish who were looking for someone that could grant the wish of Luc, his dream was to create a (Mandalorian) game! Together we made this in Construct 🎮 #gamedev
The first episode of Learn with Kenney will release this week! I've put a lot of work into it, basically redoing it from scratch after receiving feedback. I hope you'll enjoy this quirky tutorial series, unlike any other 🌌
GeoChat - Talk with a Digital Twin In Natural Language
Part 2: There is no Bakerstreet 🔍 in London! Challenges 🧩
When you try to talk to your digital twin, you don't always get the answers you expect.
https://t.co/RepSGETPhN
#llamaindex#llm#digitaltwin#geoai#texttosql


















![SchmidhuberAI's tweet photo. DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural net distillation procedure of 1991 [4]: a distilled chain of thought system.
REFERENCES (easy to find on the web):
[1] #DeepSeekR1 (2025): Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2501.12948
[2] J. Schmidhuber (JS, 2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models. arXiv 1210.0118. Sec. 5.3 describes the reinforcement learning (RL) prompt engineer which learns to actively and iteratively query its model for abstract reasoning and planning and decision making.
[3] JS (2018). One Big Net For Everything. arXiv 1802.08864. See also US11853886B2. This paper collapses the reinforcement learner and the world model of [2] (e.g., a foundation model) into a single network, using the neural network distillation procedure of 1991 [4]. Essentially what's now called an RL "Chain of Thought" system, where subsequent improvements are continually distilled into a single net. See also [5].
[4] JS (1991). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991. First working deep learner based on a deep recurrent neural net hierarchy (with different self-organising time scales), overcoming the vanishing gradient problem through unsupervised pre-training (the P in CHatGPT) and predictive coding. Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills - such approaches are now widely used. See also [6].
[5] JS (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990, introducing high-dimensional reward signals and the GAN principle). Contains summaries of [2][3] above.
[6] JS (AI Blog, 2021). 30-year anniversary: First very deep learning with unsupervised pre-training (1991) [4]. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled [4] into a single deep neural network. 1993: solving problems of depth >1000.](https://pbs.twimg.com/media/Gioh8G8X0AAOdx8.jpg)