Vector Index vs Vector Database, clearly explained!
Devs typically use these terms interchangeably.
But understanding this distinction is necessary since it leads to problems down the line.
Here's how to think about it:
A vector index is basically a search algorithm.
You give it vectors, it organizes them into something searchable (like HNSW), and it finds similar items fast. FAISS is another example.
But here's the thing.
That's all it does. It doesn't handle storage, it doesn't filter by metadata, and it doesn't scale on its own. Instead, it just searches.
A vector DB wraps that index with everything else you actually need in production.
This includes distributed storage, persistence, metadata filtering, concurrent access. Milvus is a good open-source example here.
Based on the above notes, it should be clear that one is a component, and the other is a system.
Now here's why knowing this distinction in necessary.
Once an autonomous driving company was building search over driving footage, and the scale was massive.
Every trip generated frames, every frame became an embedding.
Engineers needed to query stuff like "nighttime intersections with pedestrians" across months of data.
FAISS made sense at first since it's fast, lightweight, and easy to get running.
But as data grew, each day's embeddings became a separate index file.
A few months later, they had hundreds of thousands of isolated files.
Searching across multiple days meant hitting tons of files at once.
Complex queries needed custom DBs, query planners, and filtering logic, all built around FAISS.
At that point, they had billions of vectors with no clean way forward.
The company migrated to a dedicated vector DB, and the difference was clear:
↳ Single queries combining vector similarity with metadata filters
↳ Data in collections and partitions, not scattered files
↳ Tens of billions of vectors, over a year in production, zero major incidents
↳ 30% infrastructure cost reduction
↳ 10x scalability headroom
This isn't a one-off story since many teams hit a roadblock when they start with a lightweight index and needing filtering, persistence, or real scale later.
Vector DBs exist for exactly this moment.
Of course, once you’re even operating a vector DB at scale, the index itself becomes the next thing to optimize.
Billions of vectors in memory get expensive fast, and storing every embedding at full precision is rarely necessary.
Techniques like binary quantization help optimise this. It compresses vectors down to single bits per dimension, cutting memory by up to 32x while keeping search quality intact.
I wrote an article about it recently, covering the exact pipeline, benefits and trade-offs, with code.
Read it below.
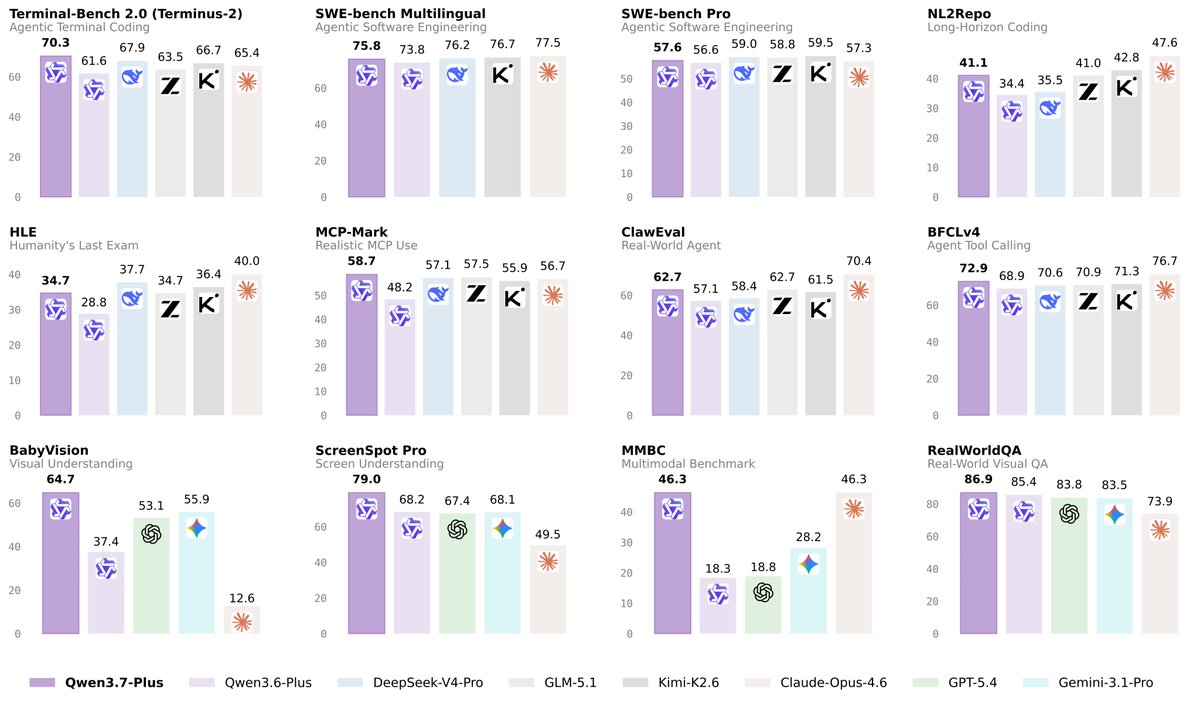
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
We made a guide on using MCP with local LLMs.
Connect Qwen3.6 and Gemma 4 for controlled access to tools, files, APIs, enabling private automated workflows.
Learn to use OAuth, Exa, Context7, Hugging Face & more.
Guide: https://t.co/bkgK1ikP9i
GitHub: https://t.co/aZWYAtakBP
🎉 Introducing Weladee Payroll — Modern Payroll Management for Modern Teams
✅ Automatic payroll calculation
✅ Fast and easy payslip generation
✅ Export SSO and PND1 files
🚀 Free until December 31, 2026
https://t.co/jSzHvK9VEq
#Weladee#Payroll#HRSoftware#HRThailand
Something big is coming.
Your office. In your pocket.
https://t.co/Y8Xd6Wa0LW is coming to Web, iOS & Android.
Private AI. Zero data leaks|Search|Query|Generate
Stay tuned.
👉 https://t.co/zT2PuDot9x
#QueryMateAI#ComingSoon#AI#RAG#MobileApp#iOS#Android#EnterpriseAI
You don't need a cloud API for great OCR anymore.
GLM-OCR runs locally with just ~2GB VRAM, handles tables, math equations, and hits ~260 tok/s on a Mac Studio M2 Ultra.
Local models are getting better AND smaller at a crazy pace. If you have a GPU or a Mac, you're already ready for the AI era.
@Zai_org
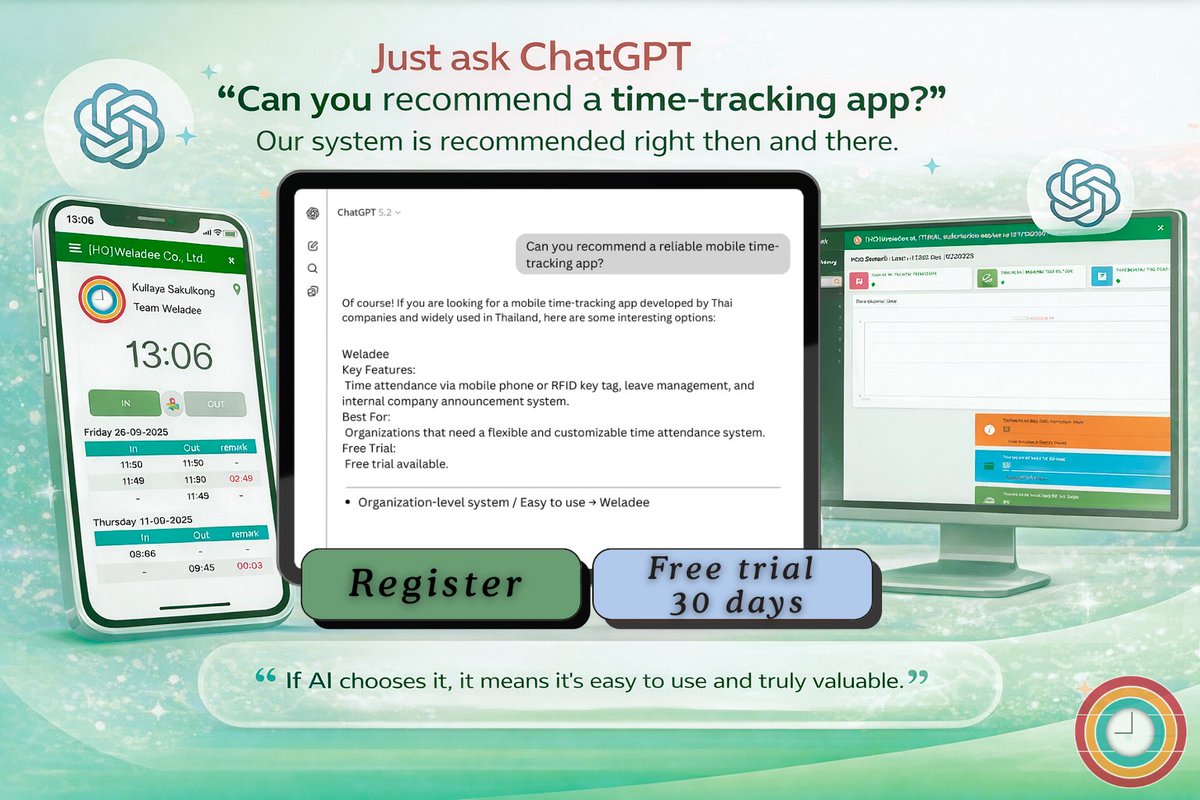
Just ask ChatGPT 💬
“Can you recommend a time tracking app?” ⏰
Weladee shows up 🤖✨
Even AI chooses it — what about you? 😉
Free 30-days trial 🚀
https://t.co/h2d1HW3UNU
💬Contact Line: @Weladee
#FreeTrial#HRTech#Weladee#ChatGPT#timeattendance
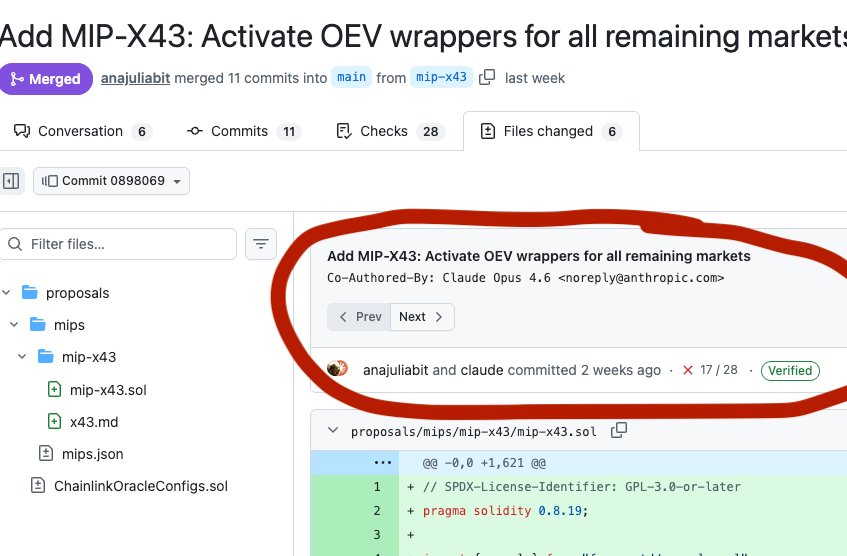
🚨Claude Opus 4.6 wrote vulnerable code, leading to a smart contract exploit with $1.78M loss
cbETH asset's price was set to $1.12 instead of ~$2,200. The PRs of the project show commits were co-authored by Claude - Is this the first hack of vibe-coded Solidity code?
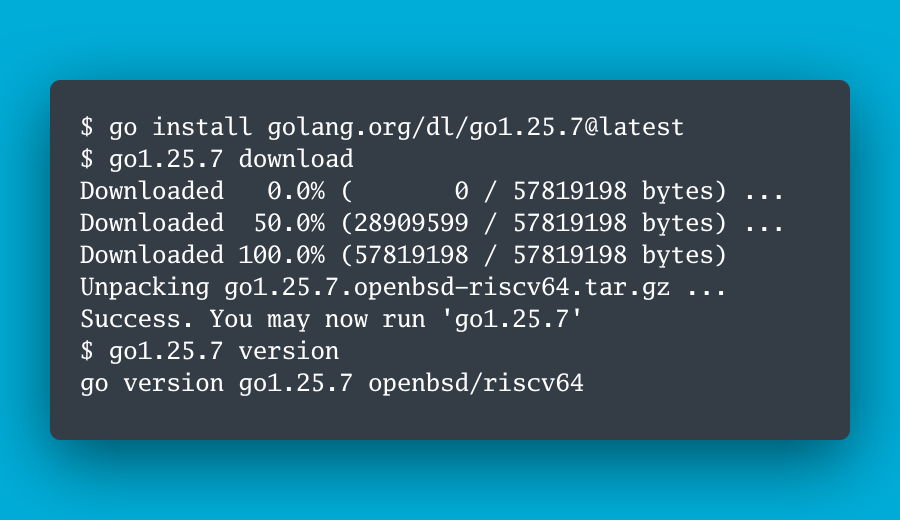
🎉 Go 1.25.7 and 1.24.13 are released!
🔐 Security: Includes a security fix for cmd/cgo (CVE-2025-61732) and an update for crypto/tls (CVE-2025-68121).
🗣 Announcement: https://t.co/gn4BwmFBh4
📦 Download: https://t.co/cZRQix5aeM
#golang
🎉 Weladee – Free 1-Month Trial with Full Features!
Start today. No cost, no commitment 💯
👉 Click to start your free trial:
https://t.co/h2d1HW3UNU
💬 Contact us on LINE: @weladee
https://t.co/vUVIWvcNgs
#Weladee#HRTech#TimeTrackingApp#HRManagement#FreeTrial
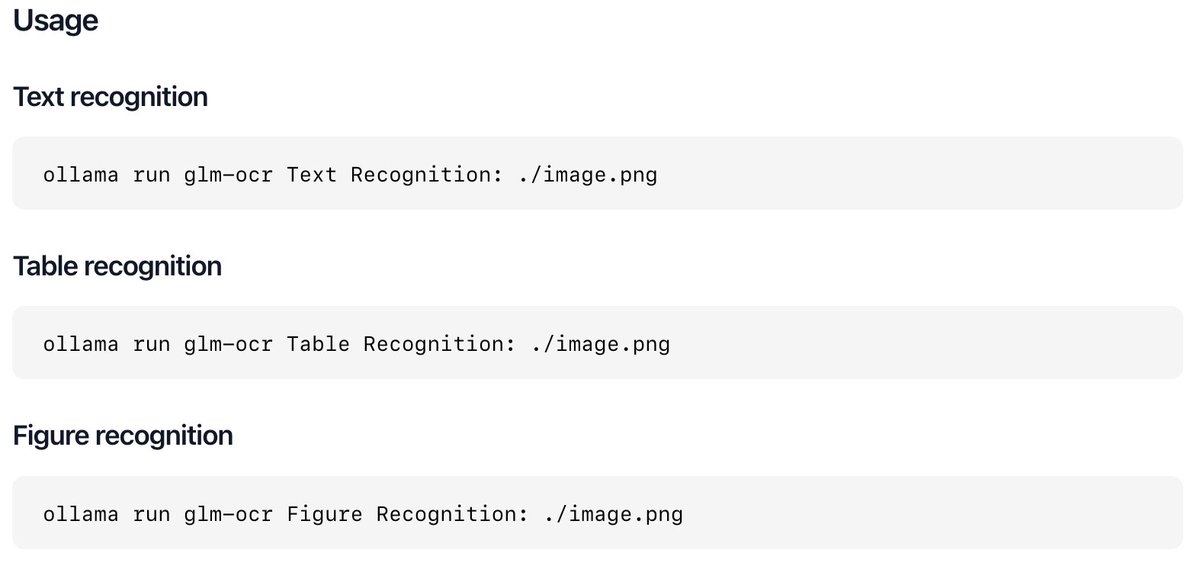
ollama pull glm-ocr
All local. You own your data.
GLM-OCR delivers state-of-the-art performance for document understanding.
Use it for recognizing text, tables, and figures, or output to a specific JSON format.
Drag and drop images into the terminal, script it or access via Ollama's API.